本发明涉及电子智能化领域,特别涉及一种语音唤醒方法、装置、设备及介质。
背景技术:
1、目前,智能音箱和手机中均含有语音唤醒功能,用来和自带的语音助手功能模块进行交互,该功能均为硬件厂商提供,集成后进行售卖。厂商可根据智能音箱和手机中的麦克风和音频解码相关硬件进行全方位的适配。随着电竞酒店蓬勃发展,部分商家也提供了在电脑端运行的数字人助手等功能。为了方便玩家,尤其在游戏过程中和数字人助手进行交互,语音唤醒是最合适的交互入口。
2、电竞酒店的电脑可能存在多种配置和组装方案,并且大多数通过外接耳麦的方式来完成音频信号的采集。电脑硬件和额外接耳麦的品牌和种类繁多,且无法提前获取相关信息,无法针对性地进行优化。麦克风的差异直接影响到搜集的音频信号的质量以及数据的增幅大小,从而影响到特征信息的提取,给后续的语音唤醒算法带来了巨大挑战,极大影响唤醒算法的精度和适用性。除此之外,环境背景的差异、使用者的人声差异以及音量大小也会对模型的稳定性造成影响。并且,由于唤醒算法在用户的pc上运行,电竞酒店的客户大多在pc上进行游戏等活动,对机器的性能较为敏感。语音唤醒需要尽量减少对硬件的资源占用,减少对用户游戏体验的影响。另外,由于用户在游戏开黑过程中,会频繁进行沟通交流。这种密集和近距离的人声数据对语音唤醒算法对唤醒词的判别能力要求较高,模型发生误判的概率增大。误唤醒会严重干扰用户的使用体验,也需要尽量进行避免。
3、由上可见,在现有的语音唤醒过程中,如何避免出现由于语音设备差异、环境背景差异、使用者人声差异以及音量大小差异导致干扰语音唤醒模型的稳定性是本领域有待解决的问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种语音唤醒方法、装置、设备及介质,提供一种数据过滤操作,根据用户的音量来进行数据筛选,减少一部分数据进行进入唤醒算法,一方面可以降低硬件资源的占用,另一方面可以减少由于各种实施环境下的差异导致语音唤醒模型的稳定性弱的情况,并且降低算法误判误唤醒的风险。其具体方案如下:
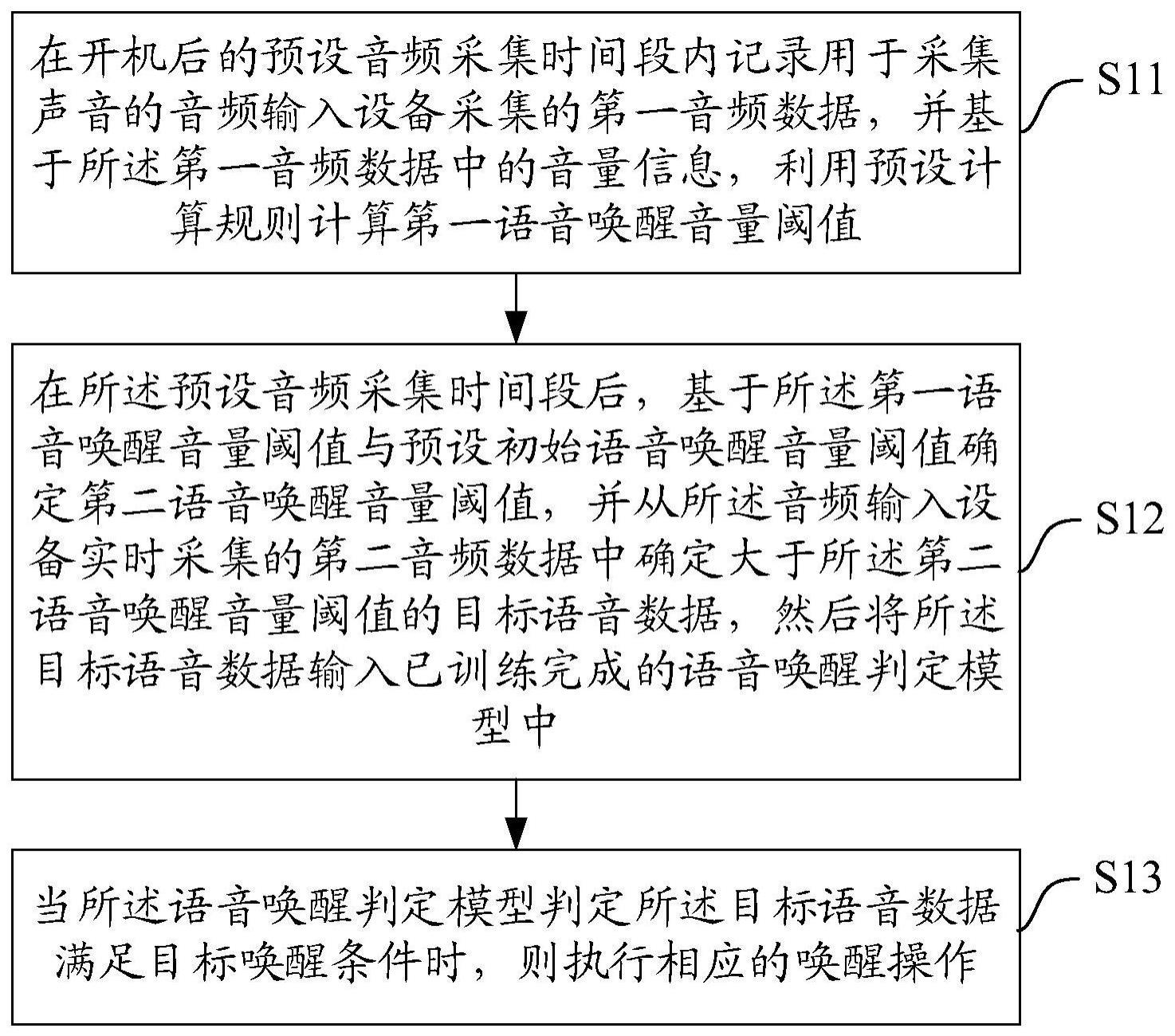
2、第一方面,本申请公开了一种语音唤醒方法,包括:
3、可选的,所述基于所述第一音频数据中的音量信息,利用预设计算规则计算第一语音唤醒音量阈值,包括:
4、基于所述第一音频数据中的音量信息与预设初始语音唤醒音量阈值,利用预设阈值计算公式计算第一语音唤醒音量阈值。
5、可选的,所述在开机后的预设音频采集时间段内记录用于采集声音的音频输入设备采集的第一音频数据之后,还包括:
6、利用预设数据特征提取算法确定所述第一音频数据对应的第一数据特征,并确定所述第一数据特征对应的第一特征参数;
7、相应的,所述语音唤醒方法,还包括:
8、在所述预设音频采集时间段后,基于所述第一特征参数与预设初始特征参数确定第二特征参数,并将所述第二数据参数更新至已训练完成的语音唤醒判定模型中。
9、可选的,所述第一特征参数、所述第二特征参数以及所述预设初始特征参数中均包括音频数据的均值和方差。
10、可选的,所述的语音唤醒方法,还包括:
11、设定预设初始语音唤醒音量阈值;其中,所述预设初始语音唤醒音量阈值为利用预先采集的样本数据中的音量信息计算四分位数,并基于所述四分位数确定并设定的阈值。
12、可选的,所述基于所述第一音频数据中的音量信息,利用预设计算规则计算第一语音唤醒音量阈值,包括:
13、计算第一音频数据中的全分贝刻度信息;
14、基于所述全分贝刻度信息,利用预设计算规则计算第一语音唤醒音量阈值。
15、可选的,所述基于所述第一语音唤醒音量阈值与预设初始语音唤醒音量阈值确定第二语音唤醒音量阈值,包括:
16、基于所述第一语音唤醒音量阈值与预设初始语音唤醒音量阈值,并利用预设滑动平均算法确定第二语音唤醒音量阈值。
17、第二方面,本申请公开了一种语音唤醒装置,包括:
18、第一阈值计算模块,用于在开机后的预设音频采集时间段内记录用于采集声音的音频输入设备采集的第一音频数据,并基于所述第一音频数据中的音量信息,利用预设计算规则计算第一语音唤醒音量阈值;
19、第二阈值计算模块,用于在所述预设音频采集时间段后,基于所述第一语音唤醒音量阈值与预设初始语音唤醒音量阈值确定第二语音唤醒音量阈值,并从所述音频输入设备实时采集的第二音频数据中确定大于所述第二语音唤醒音量阈值的目标语音数据,然后将所述目标语音数据输入已训练完成的语音唤醒判定模型中;
20、语音唤醒模块,用于当所述语音唤醒判定模型判定所述目标语音数据满足目标唤醒条件时,则执行相应的唤醒操作。
21、第三方面,本申请公开了一种电子设备,包括:
22、存储器,用于保存计算机程序;
23、处理器,用于执行所述计算机程序,以实现前述的语音唤醒方法。
24、第四方面,本申请公开了一种计算机存储介质,用于保存计算机程序;其中,所述计算机程序被处理器执行时实现前述公开的语音唤醒方法的步骤。
25、本申请先在开机后的预设音频采集时间段内记录用于采集声音的音频输入设备采集的第一音频数据,并基于所述第一音频数据中的音量信息,利用预设计算规则计算第一语音唤醒音量阈值,然后在所述预设音频采集时间段后,基于所述第一语音唤醒音量阈值与预设初始语音唤醒音量阈值确定第二语音唤醒音量阈值,并从所述音频输入设备实时采集的第二音频数据中确定大于所述第二语音唤醒音量阈值的目标语音数据,然后将所述目标语音数据输入已训练完成的语音唤醒判定模型中。当所述语音唤醒判定模型判定所述目标语音数据满足目标唤醒条件时,则执行相应的唤醒操作。这样一来,通过一种根据用户的音量来进行数据筛选的数据过滤操作,减少了一部分数据进行进入唤醒算法,一方面可以降低硬件资源的占用,另一方面可以减少由于各种实施环境下的差异导致语音唤醒模型的稳定性弱的情况,并且降低算法误判误唤醒的风险。
技术特征:1.一种语音唤醒方法,其特征在于,应用于电子设备,包括:
2.根据权利要求1所述的语音唤醒方法,其特征在于,所述基于所述第一音频数据中的音量信息,利用预设计算规则计算第一语音唤醒音量阈值,包括:
3.根据权利要求1所述的语音唤醒方法,其特征在于,所述在开机后的预设音频采集时间段内记录用于采集声音的音频输入设备采集的第一音频数据之后,还包括:
4.根据权利要求3所述的语音唤醒方法,其特征在于,所述第一特征参数、所述第二特征参数以及所述预设初始特征参数中均包括音频数据的均值和方差。
5.根据权利要求1所述的语音唤醒方法,其特征在于,还包括:
6.根据权利要求1所述的语音唤醒方法,其特征在于,所述基于所述第一音频数据中的音量信息,利用预设计算规则计算第一语音唤醒音量阈值,包括:
7.根据权利要求1至6任一项所述的语音唤醒方法,其特征在于,所述基于所述第一语音唤醒音量阈值与预设初始语音唤醒音量阈值确定第二语音唤醒音量阈值,包括:
8.一种语音唤醒装置,其特征在于,包括:
9.一种电子设备,其特征在于,包括处理器和存储器;其中,所述处理器执行所述存储器中保存的计算机程序时实现如权利要求1至7任一项所述的语音唤醒方法。
10.一种计算机可读存储介质,其特征在于,用于存储计算机程序;其中,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述的语音唤醒方法。
技术总结本申请公开了一种语音唤醒方法、装置、设备及介质,涉及电子智能化领域,该方法应用于电子设备,包括:在开机后的预设时间段内记录音频输入设备采集的第一音频数据,并基于音频数据中的音量信息,利用预设计算规则计算第一语音唤醒音量阈值;在预设时间段后,基于第一语音唤醒音量阈值与预设初始语音唤醒音量阈值确定第二阈值,并从实时采集的第二音频数据中确定大于第二阈值的目标语音数据,然后将目标语音数据输入已训练完成的语音唤醒判定模型中;当模型判定目标语音数据满足目标唤醒条件时,则执行相应的唤醒操作。本发明可以降低语音唤醒功能对于硬件资源的占用,增强语音唤醒模型的稳定性,降低误判误唤醒的风险。
技术研发人员:罗梦研,李鹏举,师艳伟
受保护的技术使用者:杭州顺网科技股份有限公司
技术研发日:技术公布日:2024/1/14