车载语音识别模型的优化方法、车载语音识别方法及装置与流程
本申请涉及语音识别,特别涉及一种车载语音识别模型的优化方法、车载语音识别方法及装置。
背景技术:
1、个性化语音识别技术能够根据用户习惯和发音方式等特征,对用户输入的语音信息进行个性化识别,提高识别准确率。随着用户对车载语音服务的期待和要求不断提高,个性化语音识别技术逐渐成为车载语音服务领域的核心发展方向。
2、目前,个性化语音识别技术主要根据用户习惯和发音方式,优化通用声学模型。然而收集用户个人的语音习惯所构建的训练集规模较小,导致声学模型优化对语音识别模型的优化效果有限;并且在每次优化模型时,需要消耗更多计算资源和增加耗时。
技术实现思路
1、本申请旨在提供一种车载语音识别模型的优化方法、车载语音识别方法及装置,以解决当前语音识别模型的个性化优化效果差且资源消耗大的技术问题。
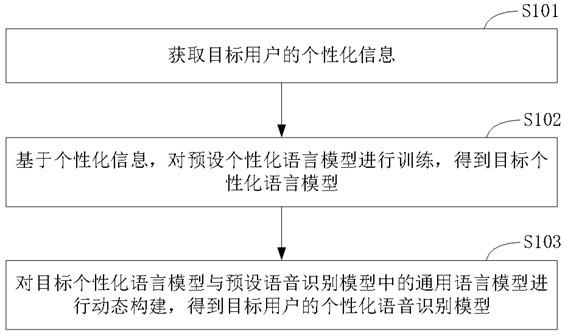
2、第一方面,本申请提供一种语音识别模型的优化方法,包括:
3、获取目标用户的个性化信息;
4、基于个性化信息,对预设个性化语言模型进行训练,得到目标个性化语言模型;
5、对目标个性化语言模型与预设语音识别模型中的通用语言模型进行动态构建,得到目标用户的个性化语音识别模型。
6、在第一方面的一些实现方式中,对目标个性化语言模型与预设语音识别模型中的通用语言模型进行动态构建,得到目标用户的个性化语音识别模型,包括:
7、根据加权有向状态转移图,调整目标个性化语言模型的第一权重系数和通用语言模型的第二权重系数;
8、利用预设线性插值加权函数,基于第一权重系数和第二权重系数,融合目标个性化语言模型和通用语言模型,得到个性化语音识别模型。
9、在第一方面的一些实现方式中,获取目标用户的个性化信息之前,包括:
10、获取目标用户的第一语音信号,并提取第一语音信号的声纹特征信息;
11、基于声纹特征信息,识别第一语音信号对应的用户标识信息;
12、将第一语音信号存储至用户标识信息对应的用户上下文信息库,用户上下文信息库用于提取目标用户的个性化信息。
13、第二方面,本申请还提供一种语音识别方法,包括:
14、获取目标用户的第二语音信号;
15、利用目标用户对应的个性化语音识别模型,对第二语音信号进行个性化识别,得到目标用户的语音信息,个性化语音识别模型为基于如第一方面的语音识别模型的优化方法得到个性化语音识别模型。
16、在第二方面的一些实现方式中,利用目标用户对应的个性化语音识别模型,对第二语音信号进行个性化识别,得到目标用户的语音信息,包括:
17、利用个性化语音识别模型的声学模型,提取第二语音信号的音素序列;
18、利用个性化识别模型中的目标语言模型,根据音素序列,在目标语言模型的加权有向状态转移图进行解码路径搜索,得到最优解码路径,目标语言模型包括目标个性化语言模型与通用语言模型;
19、基于最优解码路径,将音素序列转化为词序列,得到语音信息。
20、在第二方面的一些实现方式中,获取目标用户的第二语音信号之前,还包括:
21、获取目标用户的唤醒词语音信号;
22、计算唤醒词语音信号的唤醒词匹配得分,以及计算唤醒词语音信号的声纹匹配得分;
23、若声纹匹配得分大于第一阈值,且唤醒词匹配得分大于第二阈值,则进入获取目标用户的第二语音信号的步骤。
24、第三方面,本申请还提供一种语音识别模型的优化装置,包括:
25、第一获取模块,用于获取目标用户的个性化信息;
26、训练模块,用于基于个性化信息,对预设个性化语言模型进行训练,得到目标个性化语言模型;
27、构建模块,用于对目标个性化语言模型与预设语音识别模型中的通用语言模型进行动态构建,得到目标用户的个性化语音识别模型。
28、第四方面,本申请还提供一种语音识别装置,包括:
29、第二获取模块,用于获取目标用户的第二语音信号;
30、识别模块,用于利用目标用户对应的个性化语音识别模型,对第二语音信号进行个性化识别,得到目标用户的语音信息,个性化语音识别模型为基于如第一方面的语音识别模型的优化方法得到个性化语音识别模型。
31、第五方面,本申请还提供一种计算机设备,包括处理器和存储器,存储器用于存储计算机程序,计算机程序被处理器执行时实现如第一方面的语音识别模型的优化方法,或如第二方面的语音识别方法。
32、第六方面,本申请还提供一种计算机可读存储介质,其存储有计算机程序,计算机程序被处理器执行时实现如第一方面的语音识别模型的优化方法,或如第二方面的语音识别方法。
33、与现有技术相比,本申请至少存在以下有益效果:
34、通过获取目标用户的个性化信息,并基于个性化信息,对预设个性化语言模型进行训练,得到目标个性化语言模型,以得到针对目标用户个性化的独立语言模型,使得个性化语言模型更具有针对性,提高优化效果;再对目标个性化语言模型与预设语音识别模型中的通用语言模型进行动态构建,得到目标用户的个性化语音识别模型,从而提高语音识别模型的个性化识别能力。同时,本申请针对每个用户的个性化语言模型的训练过程相对独立,无需每次对语音识别模型重新训练,有效降低训练过程的资源消耗和提高优化效果。
35、此外,本申请还通过线性插值加权函数,动态构建目标个性化语言模型和通用语言模型,使语音识别模型的整体语言模型能够在加权有向状态转移图进行解码搜索,实现目标个性化语言模型与通用语言模型之间的融合,提高用户个性化语音识别效果。
36、本申请还建立用户上下文信息库存储用户日常语音,并基于此进行语言模型优化,以更加适用于用户的日常语音场景。
37、本申请还通过唤醒词匹配得分与声纹匹配得分综合决策,提高语音唤醒对象的识别准确度。
技术特征:
1.一种语音识别模型的优化方法,其特征在于,包括:
2.根据权利要求1所述的语音识别模型的优化方法,其特征在于,所述对所述目标个性化语言模型与预设语音识别模型中的通用语言模型进行动态构建,得到所述目标用户的个性化语音识别模型,包括:
3.根据权利要求1所述的语音识别模型的优化方法,其特征在于,所述获取目标用户的个性化信息之前,包括:
4.一种语音识别方法,其特征在于,包括:
5.根据权利要求4所述的语音识别方法,其特征在于,所述利用所述目标用户对应的个性化语音识别模型,对所述第二语音信号进行个性化识别,得到所述目标用户的语音信息,包括:
6.根据权利要求4所述的语音识别方法,其特征在于,所述获取目标用户的第二语音信号之前,还包括:
7.一种语音识别模型的优化装置,其特征在于,包括:
8.一种语音识别装置,其特征在于,包括:
9.一种计算机设备,其特征在于,包括处理器和存储器,所述存储器用于存储计算机程序,所述计算机程序被所述处理器执行时实现如权利要求1至3任一项所述的语音识别模型的优化方法,或如权利要求4至6任一项所述的语音识别方法。
10.一种计算机可读存储介质,其特征在于,其存储有计算机程序,所述计算机程序被处理器执行时实现如权利要求1至3任一项所述的语音识别模型的优化方法,或权利要求4至6任一项所述的语音识别方法。
技术总结
本申请提供一种车载语音识别模型的优化方法、车载语音识别方法及装置,通过获取目标用户的个性化信息,并基于个性化信息,对预设个性化语言模型进行训练,得到目标个性化语言模型,以得到针对目标用户个性化的独立语言模型,使得个性化语言模型更具有针对性,提高优化效果;再对目标个性化语言模型与预设语音识别模型中的通用语言模型进行动态构建,得到目标用户的个性化语音识别模型,从而提高语音识别模型的个性化识别能力。同时,本申请针对每个用户的个性化语言模型的训练过程相对独立,无需每次对语音识别模型重新训练,有效降低训练过程的资源消耗和提高优化效果。
技术研发人员:谭波
受保护的技术使用者:成都市卡蛙科技有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!