具备高速动态智能语音的开放空间沉浸式系统的制作方法
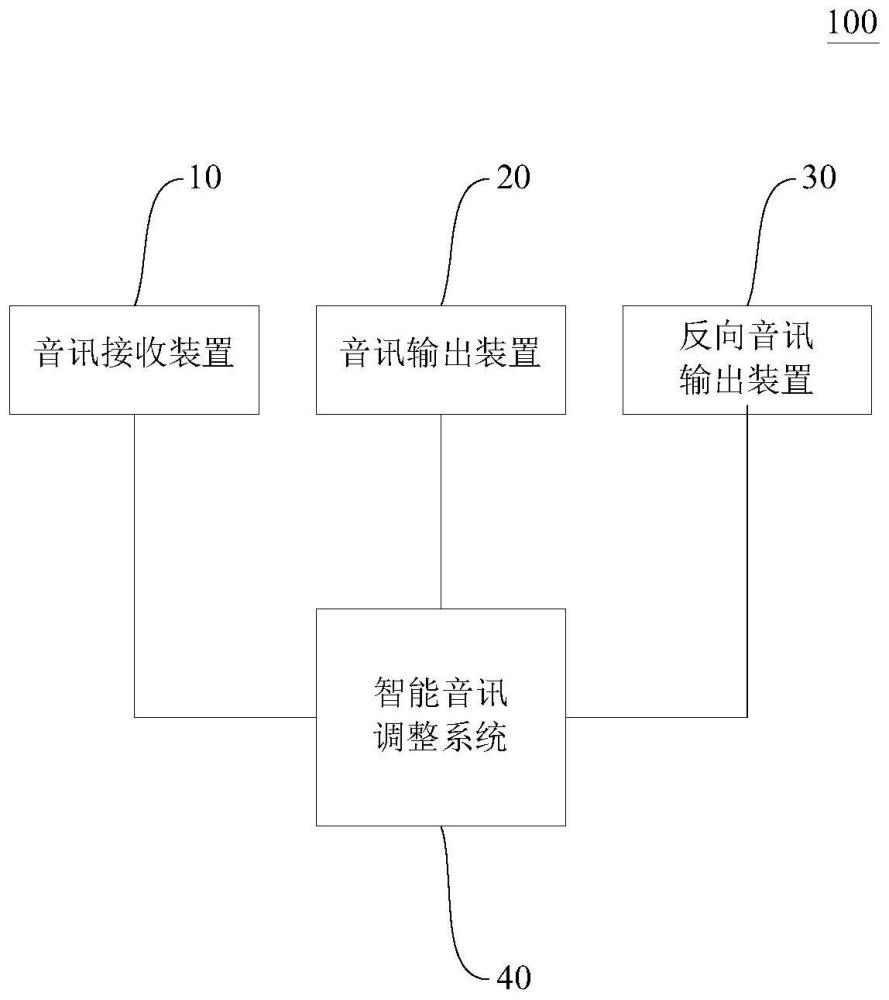
本发明有关于一种具备高速动态智能语音的开放空间沉浸式系统,特别是指一种对照语音指令生成控制指令的具备高速动态智能语音的开放空间沉浸式系统。
背景技术:
1、一般开放空间环境,例如住家、办公室、公共区域或交通枢纽,经常容易受到高水平背景噪声的影响,这些噪音会对个人的舒适度、注意力和工作效率产生负面影响。为了解决这些问题,降噪系统孕育而生,现存的降噪系统主要有两种,分别是被动降噪技术和主动降噪系统。
2、所述的被动降噪技术,常见例如吸音材料或物理屏障,可以帮助降低开放空间的噪音水平。然而,这些技术的效果有限,可能并不适用于所有环境或情况。主动噪声消除系统的原理是主动的产生抵消声波,以消除不需要的噪声,虽然这些主动噪声消除系统可能比被动降噪技术更有效,但它们通常需要用户佩戴耳机或其他个人音讯设备,这对所有用户来说可能并不方便或舒适。
技术实现思路
1、本发明的主要目的在于提供一种具备高速动态智能语音的开放空间沉浸式系统,包括一音讯接收装置、一音讯输出装置以及至少一处理器。该处理器经由载入至少一储存装置后执行一声音消除模组、一智能语音辨识模组、一音讯处理模组以及一处理模组,其中该声音消除模组经由该音讯接收装置接收非沉浸式区域的误差声音后,基于该误差声音生成反向音讯输出至该音讯输出装置,以产生一反向抵消声音。该音讯处理模组输出一播放音讯至该至少一音讯输出装置,借以于沉浸式区域内播放音效。该智能语音辨识模组由该音讯接收装置接收环境声音后,由该环境声音获得用户的语音信息,并经由解析该语音信息以获得一语音指令,该智能语音辨识模组包括一基于该环境声音生成真实语音信号的平行波形神经网路、一用以由该真实语音信号提取音讯特征的mfcc单元以及一将该mfcc单元输出音讯特征映射至该语音指令的语音辨识模组。该处理模组基于该用户的该语音指令生成对应的控制指令,并依据该控制指令切换该音讯处理模组的音讯输出模式或该声音消除模组的反向音讯输出模式。
2、可选的,该处理器经由载入该至少一储存装置后执行一位置侦测模组,该位置侦测模组由该环境声音分析该用户的位置信息,以确认该用户位于该沉浸式区域或该非沉浸式区域,该处理模组基于该用户的该语音指令及该位置信息生成对应的控制指令,并依据该控制指令切换该音讯处理模组的音讯输出模式或该声音消除模组的反向音讯输出模式。
3、可选的,该语音辨识模组为一卷积神经网路模型。
4、可选的,该智能语音辨识模组包括一ctc训练单元,ctc训练单元用于通过连接时序分类损失函数计算输出序列与标签序列之间的距离,并通过反向传播演算法更新该语音辨识模组模型的模型参数。
5、可选的,该位置侦测模组包括卷积神经网路,该卷积神经网路的训练为将输入的该环境声音映射为该语音指令,该语音指令的来源来自该沉浸式区域或该非沉浸式区域。
6、可选的,该卷积神经网路包括多个用于提取该环境声音特征的卷积层以及依据权重将多个该特征映射至该沉浸式区域或该非沉浸式区域的其中一分类结果的全连结层。
7、可选的,该卷积神经网路依据下面的流程进行训练:
8、前向传播:通过cnn模型进行前向传播,将输入资料映射到该沉浸式区域或该非沉浸式区域的其中一分类结果上,并计算预测结果与真实标签之间的差异;
9、反向传播:通过反向传播演算法,根据损失函数对该卷积神经网路的模型参数进行调整,以使模型的预测结果更接近真实标签;
10、参数更新:根据优化器对该卷积神经网路的模型参数进行更新,以最小化损失函数;以及
11、重复训练:重复执行前向传播、反向传播和参数更新操作,直到模型收敛或达到预定的训练次数。
12、可选的,该智能语音辨识模组于待机状态时经由指定语音信息或人机界面指令触发解析该语音信息的程序。因此,本发明通过高速语音辨识即时确定用户的指令,依据用户的语音指令即时反馈信号,以控制音讯输出体验以及声音消除效果,借此即时地满足个别用户的特定需求。
技术特征:
1.一种具备高速动态智能语音的开放空间沉浸式系统,其特征在于,包括:
2.根据权利要求1所述的具备高速动态智能语音的开放空间沉浸式系统,其特征在于,该处理器经由载入该至少一储存装置后执行一位置侦测模组,该位置侦测模组由该环境声音分析该用户的位置信息,以确认该用户位于该沉浸式区域或该非沉浸式区域,该处理模组基于该用户的该语音指令及该位置信息生成对应的控制指令,并依据该控制指令切换该音讯处理模组的音讯输出模式或该声音消除模组的反向音讯输出模式。
3.根据权利要求2所述的具备高速动态智能语音的开放空间沉浸式系统,其特征在于,该语音辨识模组为一卷积神经网路模型。
4.根据权利要求3所述的具备高速动态智能语音的开放空间沉浸式系统,其特征在于,该智能语音辨识模组包括一ctc训练单元,该ctc训练单元用于通过连接时序分类损失函数计算输出序列与标签序列之间的距离,并通过反向传播演算法更新该语音辨识模组模型的模型参数。
5.根据权利要求1所述的具备高速动态智能语音的开放空间沉浸式系统,其特征在于,该位置侦测模组包括卷积神经网路,该卷积神经网路的训练为将输入的该环境声音映射为该语音指令,该语音指令的来源来自该沉浸式区域或该非沉浸式区域。
6.根据权利要求5所述的具备高速动态智能语音的开放空间沉浸式系统,其特征在于,该卷积神经网路包括多个用于提取该环境声音特征的卷积层以及依据权重将多个该环境声音特征映射至该沉浸式区域或该非沉浸式区域的其中一分类结果的全连结层。
7.根据权利要求6所述的具备高速动态智能语音的开放空间沉浸式系统,其特征在于,该卷积神经网路依据下面的流程进行训练:
8.根据权利要求1所述的具备高速动态智能语音的开放空间沉浸式系统,其特征在于,该智能语音辨识模组于待机状态时经由指定语音信息或人机界面指令触发解析该语音信息的程序。
技术总结
本发明提供了具备高速动态智能语音的开放空间沉浸式系统包括音讯接收装置、音讯输出装置和至少一个处理器。处理器执行声音消除模组、智能语音辨识模组、音讯处理模组和处理模组,智能语音辨识模组包括基于环境声音生成真实语音信号的平行波形神经网路、提取音讯特征的MFCC单元以及将音讯特征映射至语音指令的语音辨识模组。音讯处理模组在沉浸式区域内播放音效。声音消除模组接收误差声音并生成反向音讯输出以抵消声音。处理模组根据语音指令生成对应的控制指令,切换音讯处理模组的音讯输出模式或声音消除模组的反向音讯输出模式,通过高速语音辨识即时确定用户的指令,依据用户的语音指令即时反馈信号,以控制音讯输出体验和声音消除效果。
技术研发人员:请求不公布姓名
受保护的技术使用者:昱盛电子股份有限公司
技术研发日:
技术公布日:2025/1/16
- 还没有人留言评论。精彩留言会获得点赞!