一种电梯场景下语音AI分析呼救系统的制作方法
本发明属于呼救系统,具体涉及一种电梯场景下语音ai分析呼救系统。
背景技术:
1、随着国内城市化率的提高,高层小区的建设数量也与日俱增,电梯是每个高层小区不可或缺的部分,为居民们的日常出行提供了便利,同时它又是一个存在风险的场所,尽管在做好年检的情况下,电梯故障概率不高,但它的每次故障却关系着人民群众的生命财产安全,因此要未雨绸缪,设法将故障发生时的损害降到最小。
2、尽管传统的电梯本身安装配置有紧急通话按钮,然而同样存在着这样的风险,即当电梯发生意外故障时,若电梯内乘客为不懂得使用呼救按钮的老人和小孩,通话按钮形同虚设,一旦被困人员尝试扒开电梯门,或者在电梯内蹦跳,很容易造成更加严重的事故;同样地,若电梯发生坠落、冲顶的故障,电梯内乘客容易在失重、高加速度情况下造成晕厥,无法主动呼救。
3、现有技术cn112978533a中,提出一种电梯困人故障自动救援系统及其救援方法,并具体公开了ard应急救援装置,执行应急解困救援任务、轿厢升降组件,控制轿厢上行和下行、困人报警装置,发送困人报警求救信号等,然而该系统安装难度较大,安装方式不便,并且需要被困人主动通过困人报警装置报警,收到困人报警信号后,才能执行解困任务。
4、因此,考虑到这些潜在问题,传统电梯及其设施尽管设置了紧急通话以保障乘客,然而仍存在一些缺点,如:1、需要被困人主动呼救,未考虑到被困人无法呼救的情形;2、安装不便,容易对电梯运行造成不良影响;3、无法快速通知救助者进行施救。鉴于现有电梯呼救系统的不足,有必要做进一步改进。
技术实现思路
1、本发明的目的在于克服上述现有技术存在的不足,为解决呼救方式为手动,且呼救方式单一,导致在被困人无法主动呼救的场景下造成呼救延误的问题,而提供一种电梯场景下语音ai分析呼救系统。
2、为了实现上述目的,本发明采用了如下技术方案:
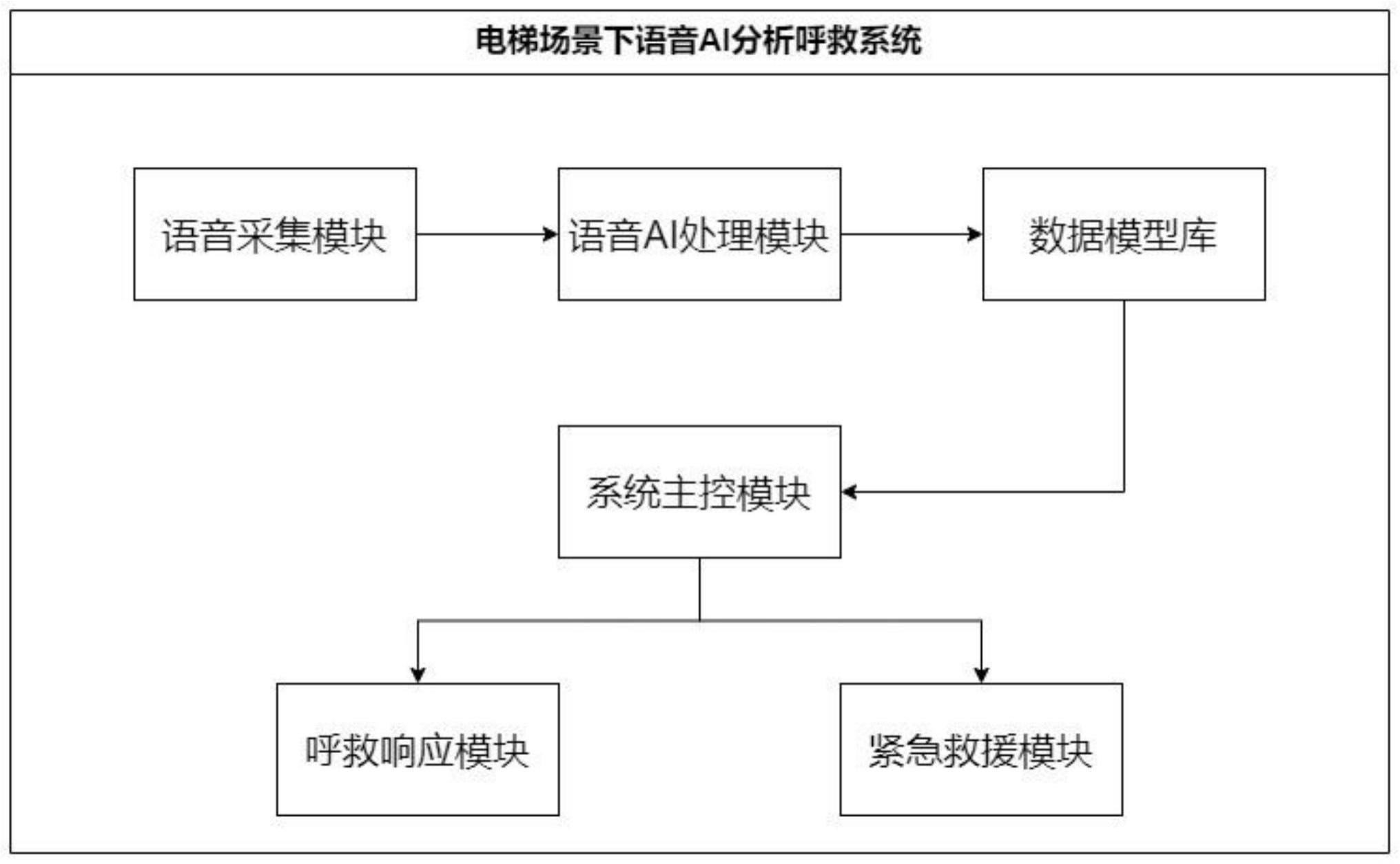
3、一种电梯场景下语音ai分析呼救系统,包括语音采集模块、语音ai处理模块、数据模型库、呼救响应模块、紧急救援模块和系统主控模块;
4、语音采集模块,用于实时采集电梯内的声音,并将其转化为数字语音信号后发送给语音ai处理模块;
5、语音ai处理模块,用于对数字语音信号进行识别、解析和判别,输出判别结果;
6、数据模型库,用于存储各类紧急情况的语音数据和训练完成的ai模型;
7、呼救响应模块,用于向电梯内乘客传递呼救信息;
8、紧急救援模块,用于启动电梯救援程序及外部人员救援流程;
9、系统主控模块,用于调控本系统的各个模块,控制采集、分析、呼救全流程。
10、优选地,语音ai采集分析呼救包括如下步骤:
11、s101:语音采集模块实时采集电梯内的源声音,形成语音流,通过语音采集模块内置的模数转换算法和降噪算法,得到可处理的数字信号;
12、s102:语音ai处理模块接收到模数转换并降噪后的数字信号,对信号进行特征提取,得到一组用于表示声音特征的特征系数;
13、最后,倒谱抬升后即可得到梅尔频率倒谱系数特征系数;
14、s103:数据模型库将提取的梅尔频率倒谱系数输入到分类模型中,分类模型经过计算及权重参数的组合,最终输出分类的结果,即与模型匹配的概率;
15、s104:系统主控模块监控分类模型的结果,若认定语音传感器采集的语音流为呼救声,则语音ai处理模块发出中断信号,系统主控模块接收信号,暂停当前任务并进入中断处理程序,调起紧急救援模块,启动救援程序,通知救援部门进行救援,并监控救援进度,调起呼救响应模块,通过主动通话,向电梯内乘客传递救援进度,待救援结束后,中断程序结束,跳转到s101。
16、优选地,降噪算法通过对输入信号进行离散小波变换,公式为:其中,h(n)为低通滤波器,g(n)为高通滤波器,a(k)为低频系数,d(k)为高频系数,x(n)表示输入信号,将输入信号分解成不同频率的子带,得到细节分量和近似分量,对细节分量进行如下式的软阈值处理:其中,d表示小波系数,thr表示阈值,对处理后的分量进行逆小波变换,将信号重构,为了使重构后的信号更加平滑,对重构后的信号进行如下式描述的均值滤波:其中,s(t)为转换前的一维信号,fs(t)为转换后的信号,信号的每时刻为t,用临近信号均值来平滑信号,然后输出最终降噪后的信号。
17、优选地,特征提取通过对信号进行预加重,提高语音信号高频部分的组成,使用如下所示的公式进行处理:f(n)=x(n)-kx(n-1),其中,语音信号的第n个采样点为x(n),k为传递系数,取值为0~1间的任意数字;
18、预加重后对语音信号进行分窗,由于语音信号的不平稳,选取的音频窗口大小为15ms,在这个窗口做特征抽取的计算操作,形成一个窗口的特征点,然后时间点向后移动一个长度,取10ms,再取一个15ms的音频窗口,并做计算,重复以上操作。
19、优选地,分窗后对音频窗口进行加窗,由于人声信号的不平稳,选择汉宁窗进行处理:其中,原始音频窗口为x,窗函数长度为n,音频窗口序号为i,i=0,1,2,3,…,n-1;
20、加窗后对语音信号进行傅里叶变换,使用短时傅里叶(stft)进行处理:
21、
22、其中,x(m)为输入信号,w(m)为窗函数,x(n,w)是时间n和频率w的二维函数。
23、优选地,分类模型使用的是三分类模型,当结果大于设置的上阈值时,认为匹配成功;当结果小于设置的下阈值时,认为匹配失败;当结果介于上下阈值中间的,作为模型的输入,手动标定并反馈于模型的训练。
24、优选地,采用放置在电梯不同位置的多个语音传感器,同时采集多通道声音信号,可使用独立成分分析算法进行高效分离,多通道声音信号分离出具有近似特征的声音后,进行相互参考,加强分离声音的置信度。
25、综上所述,由于采用了上述技术方案,本发明的有益效果是:
26、1、本发明将电梯内受困时的呼救方式改为自动呼救,同时呼救方式多样,解决了被困人无法主动呼救的场景下造成呼救延误的问题。
27、2、本发明通过将电梯内的声音转化为数字语音信号后进行识别、解析和判别,输出最终降噪后的信号,对信号进行特征提取后,得到反映声音特征的特征系数,分类模型经过计算及权重参数的组合,最终输出分类的结果,以阈值比较的方式反映匹配是否成功,以便精准高效的产生自动呼救,便于采取多样化的救援程序。
28、3、本发明采用人声分离的方法,利用放置在电梯不同位置的多个语音传感器,同时采集多通道声音信号,采用独立成分分析算法将同时采集到的多人声音进行分离操作,分离出具有近似特征的声音后,进行相互参考,加强分离声音的置信度,便于将提取出的特征系数与数据模型库进行精准判别,提高了多人同时呼救时声音交错场景下的声音提取判别精准度。
技术特征:
1.一种电梯场景下语音ai分析呼救系统,其特征在于,包括语音采集模块、语音ai处理模块、数据模型库、呼救响应模块、紧急救援模块和系统主控模块;
2.根据权利要求1所述的一种电梯场景下语音ai分析呼救系统,其特征在于,语音ai采集分析呼救包括如下步骤:
3.根据权利要求2所述的一种电梯场景下语音ai分析呼救系统,其特征在于,降噪算法通过对输入信号进行离散小波变换,公式为:其中,h(n)为低通滤波器,g(n)为高通滤波器,a(k)为低频系数,d(k)为高频系数,x(n)表示输入信号,将输入信号分解成不同频率的子带,得到细节分量和近似分量,对细节分量进行如下式的软阈值处理:其中,d表示小波系数,thr表示阈值,对处理后的分量进行逆小波变换,将信号重构,为了使重构后的信号更加平滑,对重构后的信号进行如下式描述的均值滤波:其中,s(t)为转换前的一维信号,fs(t)为转换后的信号,信号的每时刻为t,用临近信号均值来平滑信号,然后输出最终降噪后的信号。
4.根据权利要求2所述的一种电梯场景下语音ai分析呼救系统,其特征在于,特征提取通过对信号进行预加重,提高语音信号高频部分的组成,使用如下所示的公式进行处理:f(n)=x(n)-kx(n-1),其中,语音信号的第n个采样点为x(n),k为传递系数,取值为0~1间的任意数字;
5.根据权利要求4所述的一种电梯场景下语音ai分析呼救系统,其特征在于,分窗后对音频窗口进行加窗,由于人声信号的不平稳,选择汉宁窗进行处理:其中,原始音频窗口为x,窗函数长度为n,音频窗口序号为i,i=0,1,2,3,…,n-1;
6.根据权利要求2所述的一种电梯场景下语音ai分析呼救系统,其特征在于,分类模型使用的是三分类模型,当结果大于设置的上阈值时,认为匹配成功;当结果小于设置的下阈值时,认为匹配失败;当结果介于上下阈值中间的,作为模型的输入,手动标定并反馈于模型的训练。
7.根据权利要求1所述的一种电梯场景下语音ai分析呼救系统,其特征在于,采用放置在电梯不同位置的多个语音传感器,同时采集多通道声音信号,可使用独立成分分析算法进行高效分离,多通道声音信号分离出具有近似特征的声音后,进行相互参考,加强分离声音的置信度。
技术总结
本发明公开了一种电梯场景下语音AI分析呼救系统,涉及呼救系统技术领域;该电梯场景下语音AI分析呼救系统包括语音采集模块、语音AI处理模块、数据模型库、呼救响应模块、紧急救援模块和系统主控模块。语音采集模块用于实时采集电梯内的声音,并将其转化为数字语音信号后发送给语音AI处理模块;语音AI处理模块用于对数字语音信号进行识别、解析和判别,输出判别结果;呼救响应模块用于向电梯内乘客传递呼救信息;紧急救援模块用于启动电梯救援程序及外部人员救援流程。本发明的技术方案,在乘客受困时自动呼救,且呼救方式多样,解决了在被困人无法主动呼救的场景下造成呼救延误的问题。
技术研发人员:朱跃飞,周含奕
受保护的技术使用者:浙江新再灵科技股份有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!