语音数据的处理方法、装置、电子设备及存储介质与流程
本公开实施例涉及数据处理技术,尤其涉及一种语音数据的处理方法、装置、电子设备及存储介质。
背景技术:
1、语音作为一种方便快捷的沟通方式,被广泛应用于各种场景。随着科技的发展,在很多应用场景中都存在对语音数据进行智能化识别和处理的需求。然而由于语音数据为音频数据的数据格式,使其应用场景往往有所限制。
2、相关技术中,为了拓展语音数据的应用场景,将语音数据转化为其他格式的数据(如,文本数据)进行处理。但是,采用相关技术采用的语音数据处理方法一般需要根据其应用场景进行涉及,操作繁琐,且需要专业的技术支持,复用性较差。而且,相关技术处理后的得到数据,往往存在数据量较大或者语义损失较为严重等问题。
技术实现思路
1、本公开实施例提供了一种语音数据的处理方法、装置、电子设备及存储介质,以实现对语音数据的快速离散化处理。
2、第一方面,本公开实施例提供了一种语音数据的处理方法,该方法包括:
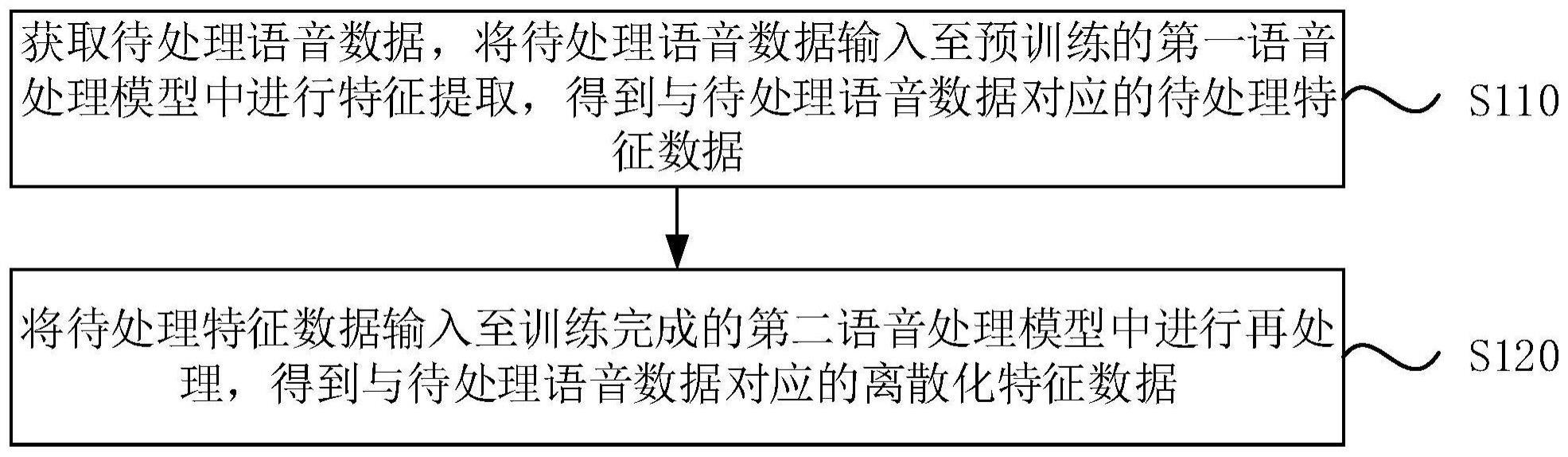
3、获取待处理语音数据,将所述待处理语音数据输入至预训练的第一语音处理模型中进行特征提取,得到与所述待处理语音数据对应的待处理特征数据;
4、将所述待处理特征数据输入至训练完成的第二语音处理模型中进行再处理,得到与所述待处理语音数据对应的离散化特征数据,其中,所述第二语音处理模型包括特征编码器以及与所述特征编码器连接的向量量化器,所述第二语音处理模型为基于样本语音数据对应的样本特征数据对预先建立的待训练模型进行训练得到,所述待训练模型包括所述第二语音处理模型以及与所述第二语音处理模型中的所述向量量化器连接的特征解码器。
5、第二方面,本公开实施例还提供了一种语音数据的处理装置,该装置包括:
6、语音特征确定模块,用于获取待处理语音数据,将所述待处理语音数据输入至预训练的第一语音处理模型中进行特征提取,得到与所述待处理语音数据对应的待处理特征数据;
7、离散化特征生成模块,用于将所述待处理特征数据输入至训练完成的第二语音处理模型中进行再处理,得到与所述待处理语音数据对应的离散化特征数据,其中,所述第二语音处理模型包括特征编码器以及与所述特征编码器连接的向量量化器,所述第二语音处理模型为基于样本语音数据对应的样本特征数据对预先建立的待训练模型进行训练得到,所述待训练模型包括所述第二语音处理模型以及与所述第二语音处理模型中的所述向量量化器连接的特征解码器。
8、第三方面,本公开实施例还提供了一种电子设备,该电子设备包括:
9、一个或多个处理器;
10、存储装置,用于存储一个或多个程序,
11、当所述一个或多个程序被所述一个或多个处理器执行,使得所述一个或多个处理器实现如本公开实施例中任一所述的语音数据的处理方法。
12、第四方面,本公开实施例还提供了一种包含计算机可执行指令的存储介质,该计算机可执行指令在由计算机处理器执行时用于执行如本公开实施例中任一所述的语音数据的处理方法。
13、本公开实施例的技术方案,首先通过获取待处理语音数据,将待处理语音数据输入至预训练的第一语音处理模型中进行特征提取,得到与待处理语音数据对应的待处理特征数据,能够自动便捷快速地获得待处理语音数据的数据特征,然后,通过将待处理特征数据输入至训练完成的第二语音处理模型中进行再处理,得到与待处理语音数据对应的离散化特征数据,能够自动便捷快速地获得待处理语音数据的离散化特征数据。由于第二语音处理模型包括特征编码器以及与特征编码器连接的向量量化器,第二语音处理模型为基于样本语音数据对应的样本特征数据对预先建立的待训练模型进行训练得到,而待训练模型包括第二语音处理模型以及与第二语音处理模型中的向量量化器连接的特征解码器,能够充分保证第二语音处理模型对待处理语音数据的准确转化,以减少语义损失,解决了相关技术中语音数据的应用场景受限以及语音数据的处理过程繁琐困难的技术问题,实现了对语音数据进行更高效的离散化处理,减小了语音数据的编码长度,节省了语音数据的存储空间,拓展了语音数据的应用场景的有益技术效果。
技术特征:
1.一种语音数据的处理方法,其特征在于,包括:
2.根据权利要求1所述的语音数据的处理方法,其特征在于,所述将所述待处理特征数据输入至训练完成的第二语音处理模型中进行再处理,得到与所述待处理语音数据对应的离散化特征数据,包括:
3.根据权利要求1所述的语音数据的处理方法,其特征在于,所述特征编码器包括编码器输入卷积层、与所述编码器输入卷积层连接的至少一个编码块以及与最后一级编码块连接的编码器输出卷积层,每个所述编码块包括至少一个残差单元以及与最后一个所述残差单元连接的单元输出卷积层。
4.根据权利要求1所述的语音数据的处理方法,其特征在于,在所述将所述待处理特征数据输入至训练完成的第二语音处理模型中进行再处理之前,还包括:
5.根据权利要求4所述的语音数据的处理方法,其特征在于,所述将所述样本特征数据输入至预先建立的待训练模型中的第二语音处理模型中进行再编码处理,得到与所述样本语音数据对应的预测特征数据,包括:
6.根据权利要求5所述的语音数据的处理方法,其特征在于,所述将所述特征编码数据输入至所述待训练模型中的所述向量量化器中进行量化处理,得到与所述待处理语音数据对应的预测特征数据,包括:
7.根据权利要求4所述的语音数据的处理方法,其特征在于,所述基于所述语音重构数据、所述预测特征数据以及所述特征编码数据对所述待训练模型中的第二语音处理模型进行优化,包括:
8.根据权利要求1所述的语音数据的处理方法,其特征在于,所述第一语音处理模型包括hubert模型、data2vec模型、wav2vec模型以及whisper模型中的编码器中的至少一种。
9.一种语音数据的处理装置,其特征在于,包括:
10.一种电子设备,其特征在于,所述电子设备包括:
11.一种包含计算机可执行指令的存储介质,其特征在于,所述计算机可执行指令在由计算机处理器执行时用于执行如权利要求1-8中任一所述的语音数据的处理方法。
技术总结
本公开实施例提供了一种语音数据的处理方法、装置、电子设备及存储介质。其中,该方法包括:获取待处理语音数据,将待处理语音数据输入至预训练的第一语音处理模型中进行特征提取,得到与待处理语音数据对应的待处理特征数据;将待处理特征数据输入至训练完成的第二语音处理模型中进行再处理,得到与待处理语音数据对应的离散化特征数据,其中,第二语音处理模型包括特征编码器以及向量量化器,第二语音处理模型为基于样本语音数据对应的样本特征数据对预先建立的待训练模型进行训练得到,待训练模型包括第二语音处理模型和特征解码器。本技术方案,实现了对语音数据进行更高效的离散化处理,减小了数据编码长度,拓展了语音数据的应用场景。
技术研发人员:黄志超,高汝霆
受保护的技术使用者:脸萌有限公司
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!