一种用于语音转换系统的音质评估方法
本发明涉及音质评估方法,具体涉及一种用于语音转换系统的音质评估方法。
背景技术:
1、语音转换是在不改变原说话人讲话内容的前提下将声音的音色转换为目标说话人音色。转换语音质量评估主要是对完成转换后的语音进行自然度和相似度的评估,通过质量评估来检测语音转换方法的优劣。评估的方法主要有客观评估和主观评估。客观评估是通过一定的算法来评测语音质量,例如pesq和p.563这样的有参考和无参考的语音质量评价标准。语音评估的主观方法就是通过测听人员对语音进行打分,比如mos、cmos和abxtest等评测方法。
2、当前转换语音的客观评价指标并不总是与人的感知相关。因此,在这种准则下训练的语音转换模型并不能有效地提高转换后语音的自然度和相似度。而主观评估本身又存在着诸多问题,例如mos评分。首先,为了确保mos评分的可信度足够高,需要大量的测听人员进行评价,导致mos评分的人力成本很高;其次,mos评分相当依赖于测听人员,同样的语音信号,不同的评价者会给出不同的评分。除此之外,mos评分还会受到听音环境、测听人员的状态等多种因素的影响。
技术实现思路
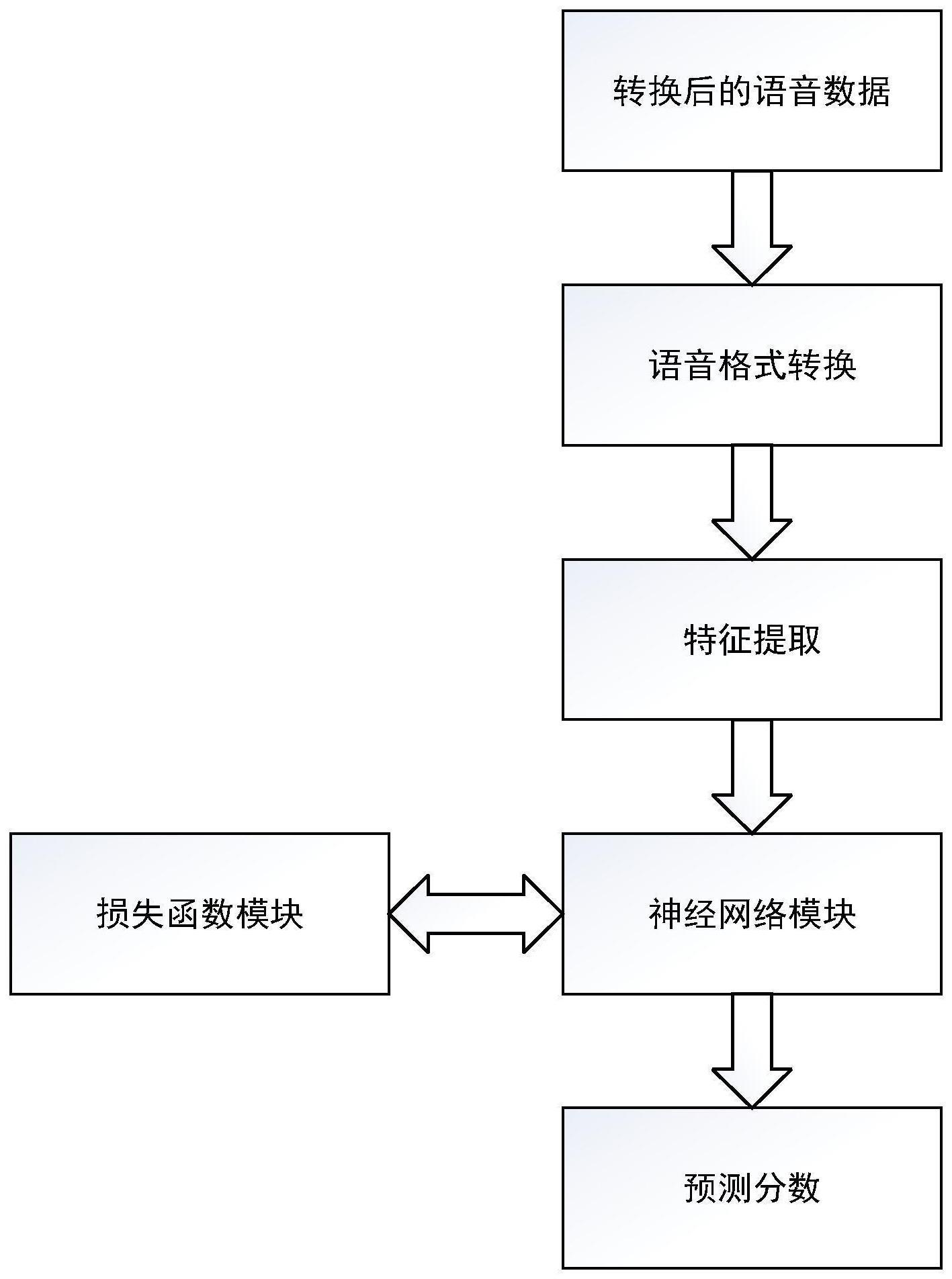
1、针对现有主、客观评价方法的不足,本发明目的在于提供一种用于语音转换系统的音质评估方法,包括以下步骤:
2、获取语音转换得到的语音数据和神经网络模型,将所述语音数据进行文件格式转换为所述神经网络模型能处理的格式,得到格式转换后的文件;
3、所述语音转换得到的语音数据包括已标注评价分数的公开语音数据集;
4、使用所述神经网络模型对格式转换后的文件进行特征提取,构建损失函数,使用已标注mos评价分数的所述公开语音数据集对所述神经网络模型进行训练,得到训练好的神经网络模型;
5、获取待评估的语音转换得到的语音数据,将其进行格式转换后,输入训练好的神经网络模型,得到评估结果。
6、优选的,所述语音数据的格式为wav格式;所述格式转换后的文件为h5格式。
7、优选的,所述使用所述神经网络模型对格式转换后的文件进行特征提取,包括:将所述格式转换后的文件进行分帧,所述分帧的帧长512个样本点,帧移256个样本点,再进行512点的短时傅里叶变换,得到由257维基于帧的频谱特征矢量构成的矢量序列;将所述矢量序列输入到所述神经网络模型中进行特征提取。
8、优选的,所述神经网络模型包括输入层、卷积层、池化层、双向长短时记忆层、全连接层、输出层
9、所述输入层用于将257维的频谱特征矢量序列进行激活并传导到卷积层;
10、所述卷积层的卷积核大小为3×3,数量为12,卷积步长为1,边缘填充方式为same激活函数为relu函数,通道数为[16,32,64,128];
11、所述卷积层之后设置所述池化层,所述池化层中的卷积核大小为2×2,数量为12,卷积步长为2;
12、所述池化层之后设置所述双向长短时记忆层;
13、所述双向长短时记忆层由两个lstm组合而成,一个lstm用于正向处理输入序列;另一个lstm用于反向处理序列,处理完成后将两个lstm的输出拼接起来;
14、所述双向长短时记忆层之后设置2个所述全连接层:两个所述全连接层用于将经过所述双向长短时记忆层得到的语音帧特征转换为帧级别的标量,以表示每帧的自然度评分;
15、2个所述全连接层之后设置输出层,所述输出层由平均池化层构成,用于通过将每帧的自然度评分进行全局平均运算,得到话语级的语音自然度评分。
16、优选的,所述神经网络模型由adam优化器进行训练,并将dropout设置为0.3;学习率为0.0001。
17、优选的,所述神经网络的损失函数为:
18、
19、其中,t为训练话语数,和gt分别表示第t个话语的真实分数和预测分数,为第t个话语里第n帧的预测分数,n为话语级的总帧数。
20、优选的,已标注的所述评价分数为mos评分、cmos评分、相似度评分中的任意一种。
21、本发明提出了一种基于深度学习的转换语音质量评估方法,利用深度神经网络来预测主观mos分数从而实现对语音质量的评估。本方法通过对主观评价的分数进行预测,能在一定程度上代替语音的主观评价,省去了人工成本。另外,通过改变评测分数的类别,使预测的分数既可以是语音mos分数,也可以是相似度分数,从而实现多类别的评价分数预测。
技术特征:
1.一种用于语音转换系统的音质评估方法,其特征在于,包括以下步骤:
2.如权利要求1所述的一种用于语音转换系统的音质评估方法,其特征在于,所述语音数据的格式为wav格式;所述格式转换后的文件为h5格式。
3.如权利要求1所述的一种用于语音转换系统的音质评估方法,其特征在于,
4.如权利要求3所述的一种用于语音转换系统的音质评估方法,其特征在于,
5.如权利要求4所述的一种用于语音转换系统的音质评估方法,其特征在于,
6.如权利要求5所述的一种用于语音转换系统的音质评估方法,其特征在于,
7.如权利要求1所述的一种用于语音转换系统的音质评估方法,其特征在于,
技术总结
本发明提供一种用于语音转换系统的音质评估方法,先将语音数据进行文件格式转换,再使用神经网络模型对格式转换后的文件进行特征提取,构建损失函数,使用已标注MOS评价分数的公开语音数据集对神经网络模型进行训练,得到训练好的神经网络模型,用于实际评估。本方法通过对主观评价的分数进行预测,能在一定程度上代替语音的主观评价,省去了人工成本。另外,通过改变评测分数的类别,使预测的分数既可以是语音MOS分数,也可以是相似度分数,从而实现多类别的评价分数预测。
技术研发人员:简志华,谈林涛,闫铎文,杨曼,梁承涵,刘二小
受保护的技术使用者:杭州电子科技大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!