歌词字头的检测方法、装置、设备及存储介质与流程
本申请涉及音频处理,特别涉及一种歌词字头的检测方法、装置、设备及存储介质。
背景技术:
1、歌词字头位置是指每个歌词的开头在歌曲音频中的位置,歌词字头位置检测是指从歌曲中检测出每个歌词的开始位置。
2、相关技术中,是基于歌词对齐算法对歌词字头的位置进行检测,将完整的歌词与歌曲音频进行特征对齐,从而得到每个歌词字头在歌曲音频中的位置。
3、然而,上述方法需要提供完整的歌词,且无法在含伴奏的歌曲中进行歌词对齐。
技术实现思路
1、本申请实施例提供了一种歌词字头的检测方法、装置、设备及存储介质。所述技术方案如下:
2、根据本申请实施例的一个方面,提供了一种歌词字头的检测方法,所述方法包括:
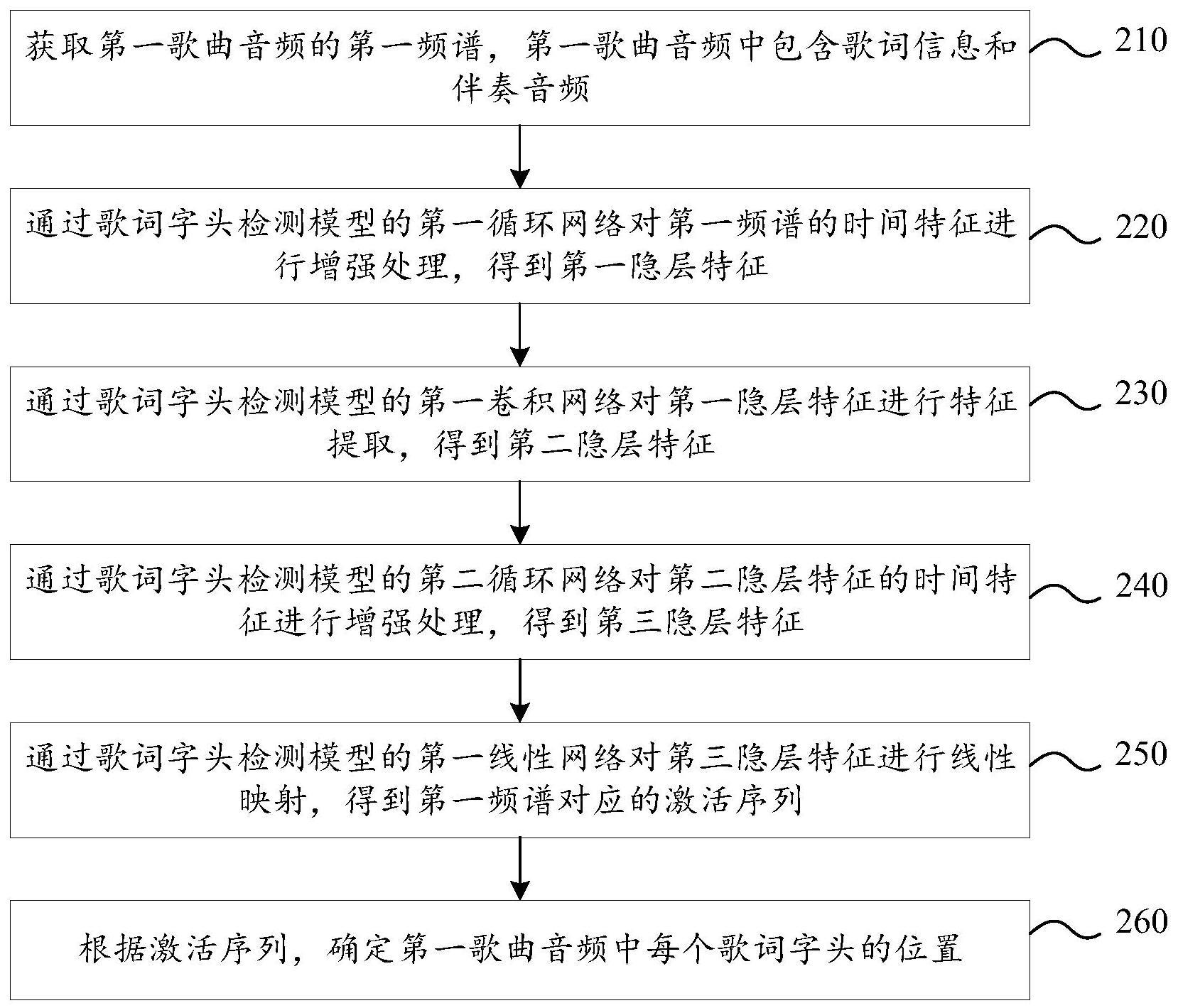
3、获取第一歌曲音频的第一频谱,所述第一歌曲音频中包含歌词信息和伴奏音频;
4、通过歌词字头检测模型的第一循环网络对所述第一频谱的时间特征进行增强处理,得到第一隐层特征;
5、通过所述歌词字头检测模型的第一卷积网络对所述第一隐层特征进行特征提取,得到第二隐层特征;
6、通过所述歌词字头检测模型的第二循环网络对所述第二隐层特征的时间特征进行增强处理,得到第三隐层特征;
7、通过所述歌词字头检测模型的第一线性网络对所述第三隐层特征进行线性映射,得到所述第一频谱对应的激活序列,所述激活序列中各个位置上的值用于指示各个位置对应的子音频为歌词字头的概率,所述子音频是所述第一歌曲音频中的音频片段;
8、根据所述激活序列,确定所述第一歌曲音频中每个歌词字头的位置。
9、根据本申请实施例的一个方面,提供了一种歌词字头检测模型的训练方法,所述歌词字头检测模型包括第一循环网络、第一卷积网络、第二循环网络和第一线性网络,所述方法包括:
10、获取所述歌词字头检测模型的训练数据集,所述训练数据集包含至少一个训练样本对,所述训练样本对中包含歌曲样本的样本频谱和所述样本频谱对应的样本激活序列,所述歌曲样本中包含歌词信息和伴奏音频,所述样本激活序列用于指示所述歌曲样本中每个歌词字头的位置;
11、通过所述第一循环网络对所述样本频谱的时间特征进行增强处理,得到第一隐层特征;
12、通过所述第一卷积网络对所述第一隐层特征进行特征提取,得到第二隐层特征;
13、通过所述第二循环网络对所述第二隐层特征的时间特征进行增强处理,得到第三隐层特征;
14、通过所述第一线性网络对所述第三隐层特征进行线性映射,得到所述样本频谱对应的预测激活序列,所述预测激活序列中各个位置上的值用于指示各个位置对应的子音频为歌词字头的概率,所述子音频是所述歌曲样本中的音频片段;
15、根据所述样本激活序列和所述预测激活序列之间的差异,对所述歌词字头检测模型的参数进行调整,得到训练后的歌词字头检测模型。
16、根据本申请实施例的一个方面,提供了一种歌词字头的检测装置,所述装置包括:
17、频谱获取模块,用于获取第一歌曲音频的第一频谱,所述第一歌曲音频中包含歌词信息和伴奏音频;
18、第一处理模块,用于通过所述歌词字头检测模型的第一循环网络对所述第一频谱的时间特征进行增强处理,得到第一隐层特征;
19、第二处理模块,用于通过所述歌词字头检测模型的第一卷积网络对所述第一隐层特征进行特征提取,得到第二隐层特征;
20、第三处理模块,用于通过所述歌词字头检测模型的第二循环网络对所述第二隐层特征的时间特征进行增强处理,得到第三隐层特征;
21、序列输出模块,用于通过所述歌词字头检测模型的第一线性网络对所述第三隐层特征进行线性映射,得到所述第一频谱对应的激活序列,所述激活序列中各个位置上的值用于指示各个位置对应的子音频为歌词字头的概率,所述子音频是所述第一歌曲音频中的音频片段;
22、字头确定模块,用于根据所述激活序列,确定所述第一歌曲音频中每个歌词字头的位置。
23、根据本申请实施例的一个方面,提供了一种歌词字头检测模型的训练装置,所述歌词字头检测模型包括第一循环网络、第一卷积网络、第二循环网络和第一线性网络,所述装置包括:
24、数据获取模块,用于获取所述歌词字头检测模型的训练数据集,所述训练数据集包含至少一个训练样本对,所述训练样本对中包含歌曲样本的样本频谱和所述样本频谱对应的样本激活序列,所述歌曲样本中包含歌词信息和伴奏音频,所述样本激活序列用于指示所述歌曲样本中每个歌词字头的位置;
25、第一处理模块,用于通过所述第一循环网络对所述样本频谱的时间特征进行增强处理,得到第一隐层特征;
26、第二处理模块,用于通过所述第一卷积网络对所述第一隐层特征进行特征提取,得到第二隐层特征;
27、第三处理模块,用于通过所述第二循环网络对所述第二隐层特征的时间特征进行增强处理,得到第三隐层特征;
28、预测输出模块,用于通过所述第一线性网络对所述第三隐层特征进行线性映射,得到所述样本频谱对应的预测激活序列,所述预测激活序列中各个位置上的值用于指示各个位置对应的子音频为歌词字头的概率,所述子音频是所述歌曲样本中的音频片段;
29、模型训练模块,用于根据所述样本激活序列和所述预测激活序列之间的差异,对所述歌词字头检测模型的参数进行调整,得到训练后的歌词字头检测模型。
30、根据本申请实施例的一个方面,提供了一种计算机设备,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机程序,所述计算机程序由所述处理器加载并执行以实现上述歌词字头的检测方法,或者歌词字头检测模型的训练方法。
31、根据本申请实施例的一个方面,提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有计算机程序,所述计算机程序由处理器加载并执行以实现上述歌词字头的检测方法,或者歌词字头检测模型的训练方法。
32、根据本申请实施例的一个方面,提供了一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序由处理器加载并执行以实现上述歌词字头的检测方法,或者歌词字头检测模型的训练方法。
33、本申请实施例提供的技术方案可以带来如下有益效果:
34、通过歌词字头检测模型的第一循环网络对第一频谱的时间特征进行增强处理,通过第一卷积网络对第一隐层特征进行特征提取,通过第二循环网络对第二隐层特征的时间特征进行增强处理,最后通过第一线性网络对第三隐层特征进行线性映射,得到第一频谱对应的激活序列,从而可以根据激活序列中各个位置上的值确定出各个位置对应的子音频为歌词字头的概率,以此确定出第一歌曲音频中每个歌词字头的位置。相较于相关技术,本申请提供的技术方案可以从带有伴奏音频的歌曲音频中检测出每个歌词字头的位置,而不需要事先进行人声和伴奏分离,并且提高了模型的泛化能力,以及提高了模型的歌词字头检测的准确率。
技术特征:
1.一种歌词字头的检测方法,其特征在于,所述方法包括:
2.根据权利要求1所述的方法,其特征在于,所述获取第一歌曲音频的第一频谱,包括:
3.根据权利要求1所述的方法,其特征在于,所述第一卷积网络包括至少一个卷积神经网络,所述卷积神经网络包括卷积层、批归一化层和激活层;
4.根据权利要求1所述的方法,其特征在于,所述第一循环网络包括至少一个循环神经网络,所述第二循环网络包括至少一个所述循环神经网络,所述第一线性网络包括至少一个线性层。
5.根据权利要求1所述的方法,其特征在于,所述根据所述激活序列,确定所述第一歌曲音频中的歌词字头位置,包括:
6.一种歌词字头检测模型的训练方法,其特征在于,所述歌词字头检测模型包括第一循环网络、第一卷积网络、第二循环网络和第一线性网络,所述方法包括:
7.根据权利要求6所述的方法,其特征在于,所述获取所述歌词字头检测模型的训练数据集,包括:
8.根据权利要求6所述的方法,其特征在于,所述获取所述歌词字头检测模型的训练数据集,包括:
9.根据权利要求6所述的方法,其特征在于,所述第一卷积网络包括至少一个卷积神经网络,所述卷积神经网络包括卷积层、批归一化层、激活层和随机丢弃层;
10.根据权利要求6所述的方法,其特征在于,所述样本激活序列中各个位置上的值用于指示各个位置对应的子音频是否为歌词字头;
11.根据权利要求6至10任一项所述的方法,其特征在于,所述根据所述样本激活序列和所述预测激活序列之间的差异,对所述歌词字头检测模型的参数进行调整,得到训练后的歌词字头检测模型,包括:
12.一种歌词字头的检测装置,其特征在于,所述装置包括:
13.一种歌词字头检测模型的训练装置,其特征在于,所述歌词字头检测模型包括第一循环网络、第一卷积网络、第二循环网络和第一线性网络,所述装置包括:
14.一种计算机设备,其特征在于,所述计算机设备包括处理器和存储器,所述存储器中存储有计算机程序,所述计算机程序由所述处理器加载并执行以实现如权利要求1至5任一项所述的歌词字头的检测方法,或者实现如权利要求6至11任一项所述的歌词字头检测模型的训练方法。
15.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质中存储有计算机程序,所述计算机程序由处理器加载并执行以实现如权利要求1至5任一项所述的歌词字头的检测方法,或者实现如权利要求6至11任一项所述的歌词字头检测模型的训练方法。
16.一种计算机程序产品,其特征在于,所述计算机程序产品包括计算机程序,所述计算机程序由处理器加载并执行以实现如权利要求1至5任一项所述的歌词字头的检测方法,或者实现如权利要求6至11任一项所述的歌词字头检测模型的训练方法。
技术总结
本申请公开了一种歌词字头的检测方法、装置、设备及存储介质,涉及音频处理技术领域。所述方法包括:获取第一歌曲音频的第一频谱;通过歌词字头检测模型的第一循环网络对第一频谱的时间特征进行增强处理,得到第一隐层特征;通过歌词字头检测模型的第一卷积网络对第一隐层特征进行特征提取,得到第二隐层特征;通过歌词字头检测模型的第二循环网络对第二隐层特征的时间特征进行增强处理,得到第三隐层特征;通过歌词字头检测模型的第一线性网络对第三隐层特征进行线性映射,得到第一频谱对应的激活序列;根据激活序列,确定第一歌曲音频中每个歌词字头的位置。本申请不需要事先进行人声和伴奏分离,提高了模型的歌词字头检测的准确率。
技术研发人员:罗程方
受保护的技术使用者:广州世音联软件科技有限公司
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!