一种基于语音时序特征的抑郁症诊断系统、设备及介质的制作方法
本发明涉及疾病诊断,特别是涉及一种基于语音时序特征的抑郁症诊断系统、设备及介质。
背景技术:
1、本部分的陈述仅仅是提供了与本发明相关的背景技术信息,不必然构成在先技术。
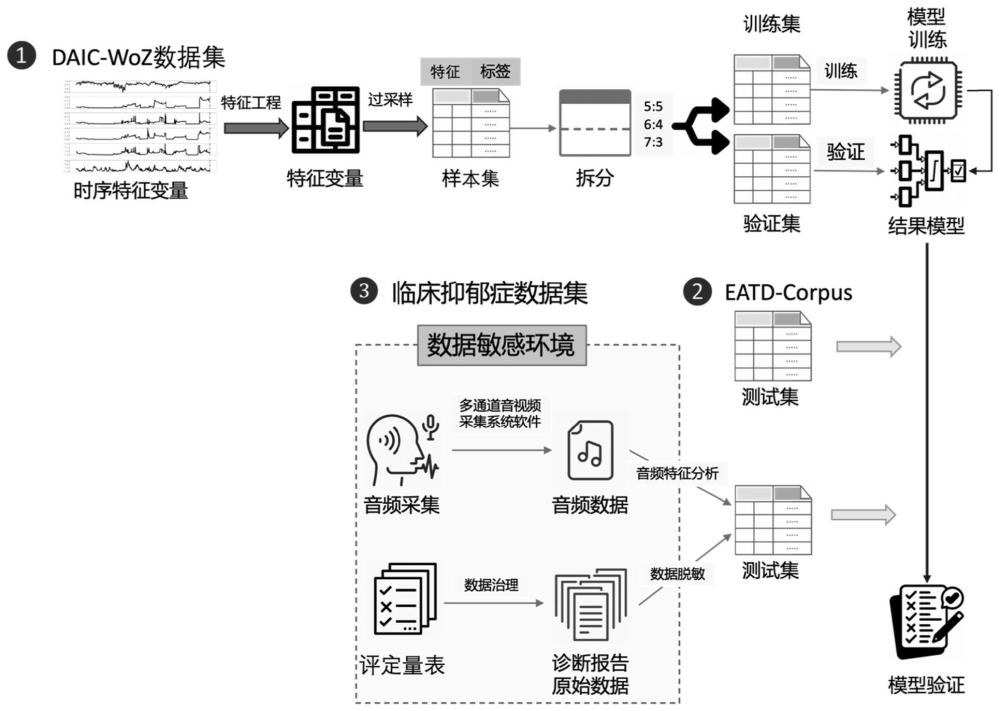
2、目前抑郁类精神疾病的诊断主要还是依靠精神科医生的临床访谈和评估,常用的诊断工具包括各种phq-8评定量表或sds问卷评分、诊断访谈等,其它一些辅助类的诊断手段,如影像学、生物标志物、基因检测等方面,多数还处在研究阶段,尚未广泛应用于临床。随着对抑郁症疾病认识的深入,越来越强调以维度而非分类的方式理解精神疾病,关注个体之间的异质性。互联网技术的发展为远程精神健康评估和服务提供了可能,但网络诊断仍面临数据质量、隐私保护等方面的挑战。目前临床专家普遍认识到,能否在保障病患隐私的前提下,更准确的对患者进行确诊,更好地指导治疗与康复才是精神疾病诊治的关键。
3、语音时序特征是一种隐私保障的诊断依据,目前,基于语音时序特征的抑郁症疾病诊断方法普遍存在以下缺陷和不足:(1)诊断方法的判定依赖患者的语音词汇,例如语音信息转换为文本的形式,但是患者语音词汇的表达受诊断访谈过程的影响,从而会影响诊断的准确性。(2)目前研究样本量太少、诊断标签缺乏权威性,从而导致诊断方法的准确率不高。
技术实现思路
1、为了解决上述问题,本发明提出了一种基于语音时序特征的抑郁症诊断系统、设备及介质,采用对语音时序特征作为训练数据,不涉及病患隐私,采用过采样技术对正样本进行扩增,解决数据不平衡问题,保证训练集充足的数据量。
2、为了实现上述目的,本发明采用如下技术方案:
3、第一方面,本发明提供一种基于语音时序特征的抑郁症诊断系统,包括:
4、数据获取模块,被配置为获取历史语音音频数据集及每个样本对应的正/负样本标签;
5、数据扩充模块,被配置为遍历历史语音音频数据集,以负样本中居中的设定时序长度的片段为新样本,对正样本根据设定时序长度进行切片划分,以每个片段为一个新样本,由此得到新样本集;
6、特征提取模块,被配置为对新样本集中每个样本在时序维度上提取语音特征值,得到训练数据集;
7、诊断模块,被配置为根据训练数据集对预先构建的分类模型进行训练,并采用训练后的分类模型对待测语音音频数据进行抑郁症诊断。
8、作为可选择的一种实施方式,将历史语音音频数据集中的所有样本按能够检测到语音输入信号为准,以设定采样率进行提取样本。
9、作为可选择的一种实施方式,对新样本集中的每个样本提取n个语音特征变量,对每个语音特征变量在时序维度上计算语音特征值,由此将新样本集中每设定时序长度的时序变量转换为包含语音特征值的序列。
10、作为可选择的一种实施方式,提取的语音特征值包括均值、方差、最小值、最大值和四分位数。
11、作为可选择的一种实施方式,分类模型的构建过程包括:
12、指定元学习算法和l个基础学习算法,对每个基础学习算法配置一组特定模型参数;
13、根据训练数据集训练l个基础学习算法,对每个基础学习算法执行k折交叉验证,获取每个基础学习算法的交叉验证预测值;
14、将每个基础学习算法的n个交叉验证预测值组合起来形成n*l矩阵,将该矩阵与原始训练数据组成一级数据;
15、采用一级数据训练元学习算法,由此将训练后得到的l个基础学习模型和元学习模型组成分类模型。
16、作为可选择的一种实施方式,对分类模型的构建及训练过程包括:所述基础学习算法为梯度提升机算法、极端随机树算法、深度随机森林算法和融合深度学习算法;所述元学习算法为广义线性模型算法。
17、作为可选择的一种实施方式,采用训练后的分类模型进行预测时,先利用l个基础学习模型进行预测,将l个基础学习模型的预测值输入到元学习模型中以生成整体预测值。
18、作为可选择的一种实施方式,对正样本进行切片划分时,踢除不足设定时序长度的片段。
19、第二方面,本发明提供一种电子设备,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成基于语音时序特征的抑郁症诊断方法,所述方法包括:
20、获取历史语音音频数据集及每个样本对应的正/负样本标签;
21、遍历历史语音音频数据集,以负样本中居中的设定时序长度的片段为新样本,对正样本根据设定时序长度进行切片划分,以每个片段为一个新样本,由此得到新样本集;
22、对新样本集中每个样本在时序维度上提取语音特征值,得到训练数据集;
23、根据训练数据集对预先构建的分类模型进行训练,并采用训练后的分类模型对待测语音音频数据进行抑郁症诊断。
24、第三方面,本发明提供一种计算机可读存储介质,用于存储计算机指令,所述计算机指令被处理器执行时,完成基于语音时序特征的抑郁症诊断方法,所述方法包括:
25、获取历史语音音频数据集及每个样本对应的正/负样本标签;
26、遍历历史语音音频数据集,以负样本中居中的设定时序长度的片段为新样本,对正样本根据设定时序长度进行切片划分,以每个片段为一个新样本,由此得到新样本集;
27、对新样本集中每个样本在时序维度上提取语音特征值,得到训练数据集;
28、根据训练数据集对预先构建的分类模型进行训练,并采用训练后的分类模型对待测语音音频数据进行抑郁症诊断。
29、与现有技术相比,本发明的有益效果为:
30、本发明在模型训练时采用的仅是对语音音频数据分析提取的语音时序特征作为训练数据,不使用涉及病患隐私敏感的如访谈内容、面部图像等信息,可以有效的保障病患的隐私安全。
31、本发明采用过采样技术对正样本进行扩增,解决数据不平衡问题,保证训练样本集充足的数据量,同时,训练后的分类模型在临床应用过程中,不需要词汇语料数据即可完成抑郁症疾病的诊断。
32、本发明采用集成模型进行预测,采用有监督的集成机器学习算法,使用堆叠过程,通过多种学习算法来获得比任何组成学习算法更好的预测性能,并找到预测算法集合的最佳组合,构建二元分类的任务模型,提高预测精度。
33、本发明附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本发明的实践了解到。
技术特征:
1.一种基于语音时序特征的抑郁症诊断系统,其特征在于,包括:
2.如权利要求1所述的一种基于语音时序特征的抑郁症诊断系统,其特征在于,将历史语音音频数据集中的所有样本按能够检测到语音输入信号为准,以设定采样率进行提取样本。
3.如权利要求1所述的一种基于语音时序特征的抑郁症诊断系统,其特征在于,对新样本集中的每个样本提取n个语音特征变量,对每个语音特征变量在时序维度上计算语音特征值,由此将新样本集中每设定时序长度的时序变量转换为包含语音特征值的序列。
4.如权利要求3所述的一种基于语音时序特征的抑郁症诊断系统,其特征在于,提取的语音特征值包括均值、方差、最小值、最大值和四分位数。
5.如权利要求1所述的一种基于语音时序特征的抑郁症诊断系统,其特征在于,分类模型的构建过程包括:
6.如权利要求5所述的一种基于语音时序特征的抑郁症诊断系统,其特征在于,对分类模型的构建及训练过程包括:所述基础学习算法为梯度提升机算法、极端随机树算法、深度随机森林算法和融合深度学习算法;所述元学习算法为广义线性模型算法。
7.如权利要求5所述的一种基于语音时序特征的抑郁症诊断系统,其特征在于,采用训练后的分类模型进行预测时,先利用l个基础学习模型进行预测,将l个基础学习模型的预测值输入到元学习模型中以生成整体预测值。
8.如权利要求1所述的一种基于语音时序特征的抑郁症诊断系统,其特征在于,对正样本进行切片划分时,踢除不足设定时序长度的片段。
9.一种电子设备,其特征在于,包括存储器和处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成基于语音时序特征的抑郁症诊断方法,所述方法包括:
10.一种计算机可读存储介质,其特征在于,用于存储计算机指令,所述计算机指令被处理器执行时,完成基于语音时序特征的抑郁症诊断方法,所述方法包括:
技术总结
本发明公开一种基于语音时序特征的抑郁症诊断系统、设备及介质,包括:获取历史语音音频数据集及每个样本对应的正/负样本标签;以负样本中居中的设定时序长度的片段为新样本,对正样本根据设定时序长度进行切片划分,以每个片段为一个新样本,由此得到新样本集;对新样本集中每个样本在时序维度上提取语音特征值,对预先构建的分类模型进行训练,并采用训练后的分类模型对待测语音音频数据进行抑郁症诊断。解决数据不平衡问题,保证训练集充足的数据量且不涉及病患隐私。
技术研发人员:于天贵,夏伟丽,刘娅飞,李文涛,李新
受保护的技术使用者:山东省精神卫生中心
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!