音频处理方法及装置与流程
本申请涉及机器学习领域,特别涉及一种音频处理方法、装置、计算机设备及存储介质。
背景技术:
1、对音乐进行描述有利于方便进行音乐的推荐,帮助失聪人群了解音乐内容,也能成为音乐生成任务的接口和数据集的构建方式,为其它任务的研究提供便利,具有重要的意义。
2、然而,目前对音乐进行描述通常只是对音乐风格这个单一的角度进行描述,提供给用户的信息较少。
技术实现思路
1、本申请的目的在于提供一种音频处理方法、装置、计算机设备及存储介质,用于解决相关技术中音乐描述的信息较少的技术问题。
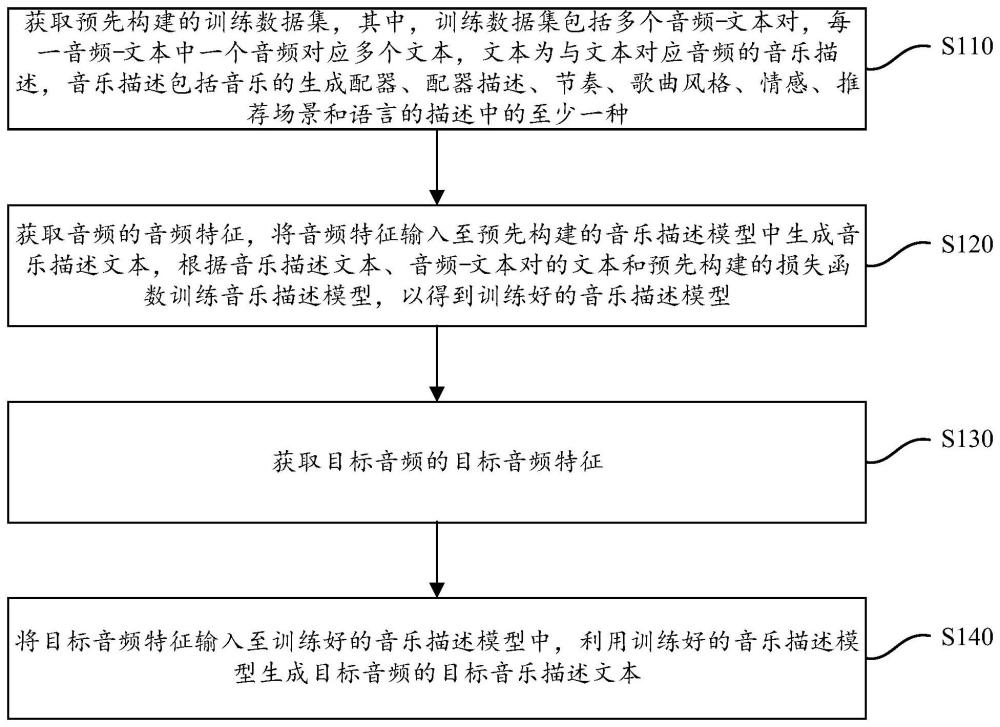
2、本申请实施例的一个方面提供了一种音频处理方法,包括:获取预先构建的训练数据集,其中,所述训练数据集包括多个音频-文本对,每一所述音频-文本对中一个音频对应多个文本,所述文本为与所述文本对应音频的音乐描述,所述音乐描述包括音乐的生成配器、配器描述、节奏、歌曲风格、情感、推荐场景和语言的描述中的至少一种;获取所述音频的音频特征,将所述音频特征输入至预先构建的音乐描述模型中生成音乐描述文本,根据所述音乐描述文本、所述音频-文本对的文本和预先构建的损失函数训练所述音乐描述模型,以得到训练好的音乐描述模型;获取目标音频的目标音频特征;将所述目标音频特征输入至所述训练好的音乐描述模型中,利用所述训练好的音乐描述模型生成所述目标音频的目标音乐描述文本。
3、可选地,在所述获取预先构建的训练数据集之前,所述方法还包括:获取多个训练音频及各个所述训练音频的相关信息;以所述相关信息为提示信息,利用生成式人工智能模型生成与每个所述训练音频对应的多个描述标签;根据预设的文本提示信息将多个所述描述标签扩写为描述长文本;根据所述描述长文本和与所述描述长文本对应的训练音频组成所述音频-文本对,以得到所述训练数据集。
4、可选地,所述根据所述描述长文本和与所述描述长文本对应的音频组成所述音频-文本对,包括:对所述训练音频进行副歌检测,在所述训练音频包括副歌部分的情况下,获取各个所述训练音频中的副歌片段;根据所述描述长文本和与所述描述长文本对应的所述副歌片段组成所述音频-文本对。
5、可选地,部分所述训练音频包括纯乐器演奏音频,所述纯乐器演奏音频包括配器标注信息。
6、可选地,所述获取所述音频的音频特征,包括:利用所述训练数据集微调文本-音频预训练模型,得到微调好的文本-音频预训练模型;利用所述微调好的文本-音频预训练模型获取所述音频的音频特征。
7、可选地,方法还包括:在训练的过程中,将所述音乐描述文本输入至所述微调好的文本-音频预训练模型,以得到所述音乐描述文本的文本特征;根据所述文本特征和所述音频特征计算特征损失,根据特征损失计算的结果更新所述微调好的文本-音频预训练模型。
8、可选地,所述将所述音频特征输入至预先构建的音乐描述模型中生成音乐描述文本,包括:将所述音频特征输入至预先构建的特征规范器,得到规范后的音频特征,其中,所述特征规范器包括若干个规范模块,每一所述规范模块包括批标准化层、一维卷积层、填充操作和激活函数;将所述规范后的音频特征输入至预先构建的音乐描述模型中生成音乐描述文本。
9、可选地,所述音乐描述模型通过预先构建的文本解码器生成所述音乐描述文本,所述文本解码器通过在因果自注意力层和前馈神经网络之间为每个transformer块加入交叉注意力层,所述交叉注意力层用于加入所述规范后的音频特征。
10、可选地,所述文本解码器用于将当前token部分之后的token加入预测过程,以通过预设的文本提示信息的提示来生成所述音乐描述文本。
11、本申请实施例的一个方面又提供了一种音频处理装置,包括:第一获取模块,用于获取预先构建的训练数据集,其中,所述训练数据集包括多个音频-文本对,每一所述音频-文本对中一个音频对应多个文本,所述文本为与所述文本对应音频的音乐描述,所述音乐描述包括音乐的生成配器、配器描述、节奏、歌曲风格、情感、推荐场景和语言的描述中的至少一种;训练模块,用于获取所述音频的音频特征,将所述音频特征输入至预先构建的音乐描述模型中生成音乐描述文本,根据所述音乐描述文本、所述音频-文本对的文本和预先构建的损失函数训练所述音乐描述模型,以得到训练好的音乐描述模型;第二获取模块,获取目标音频的目标音频特征;生成模块,用于将所述目标音频特征输入至所述训练好的音乐描述模型中,利用所述训练好的音乐描述模型生成所述目标音频的目标音乐描述文本。
12、本申请实施例的一个方面又提供了一种计算机设备,所述计算机设备包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时用于实现上述的音频处理方法的步骤。
13、本申请实施例的一个方面又提供了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机程序,所述计算机程序可被至少一个处理器所执行,以使所述至少一个处理器执行上述的音频处理方法的步骤。
14、本申请实施例提供的音频处理方法、装置、计算机设备及存储介质,包括以下优点:
15、通过获取预先构建的训练数据集,训练数据集包括多个音频-文本对,每一音频-文本对中一个音频对应多个文本,文本为对应音频的音乐描述;获取音频的音频特征,将音频特征输入至预先构建的音乐描述模型中生成音乐描述文本,根据生成的音乐描述文本、音频-文本对中的文本和预先构建的损失函数训练音乐描述模型,以得到训练好的音乐描述模型;获取目标音频的目标音频特征,将目标音频特征输入至训练好的音乐描述模型中,利用训练好的音乐描述模型生成目标音频的目标音乐描述文本,可以对音乐生成多种角度的音乐描述,从而为需要的用户提供较为丰富的音乐信息。
技术特征:
1.一种音频处理方法,其特征在于,包括:
2.根据权利要求1所述的音频处理方法,其特征在于,在所述获取预先构建的训练数据集之前,所述方法还包括:
3.根据权利要求2所述的音频处理方法,其特征在于,所述根据所述描述长文本和与所述描述长文本对应的音频组成所述音频-文本对,包括:
4.根据权利要求2所述的音频处理方法,其特征在于,部分所述训练音频包括纯乐器演奏音频,所述纯乐器演奏音频包括配器标注信息。
5.根据权利要求1所述的音频处理方法,其特征在于,所述获取所述音频的音频特征,包括:
6.根据权利要求5所述的音频处理方法,其特征在于,还包括:
7.根据权利要求5所述的音频处理方法,其特征在于,所述将所述音频特征输入至预先构建的音乐描述模型中生成音乐描述文本,包括:
8.根据权利要求6所述的音频处理方法,其特征在于,所述音乐描述模型通过预先构建的文本解码器生成所述音乐描述文本,所述文本解码器通过在因果自注意力层和前馈神经网络之间为每个transformer块加入交叉注意力层,所述交叉注意力层用于加入所述规范后的音频特征。
9.根据权利要求8所述的音频处理方法,其特征在于,所述文本解码器用于将当前token部分之后的token加入预测过程,以通过预设的文本提示信息的提示来生成所述音乐描述文本。
10.一种音频处理装置,其特征在于,包括:
11.一种计算机设备,所述计算机设备包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时用于实现权利要求1至9中任一项所述的音频处理方法的步骤。
12.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质内存储有计算机程序,所述计算机程序可被至少一个处理器所执行,以使所述至少一个处理器执行权利要求1至9中任一项所述的音频处理方法的步骤。
技术总结
本申请实施例提供一种音频处理方法,方法包括:获取预先构建的训练数据集,其中,训练数据集包括多个音频‑文本对,每一音频‑文本对中一个音频对应多个文本,文本为与文本对应音频不同角度的音乐描述;获取音频的音频特征,将音频特征输入至预先构建的音乐描述模型中生成音乐描述文本,根据音乐描述文本、音频‑文本对的文本和预先构建的损失函数训练音乐描述模型,以得到训练好的音乐描述模型;获取目标音频的目标音频特征;将目标音频特征输入至训练好的音乐描述模型中,利用训练好的音乐描述模型生成目标音频的目标音乐描述文本。本申请实施例提供的音频处理方法,可以对音乐提供多种角度的音乐描述,为用户提供更多的音乐信息。
技术研发人员:范欣悦,甘旭
受保护的技术使用者:上海哔哩哔哩科技有限公司
技术研发日:
技术公布日:2024/3/17
- 还没有人留言评论。精彩留言会获得点赞!