声音记录和重新创建的制作方法
本公开涉及捕获和呈现音频,并更具体地说,涉及在第一装置处捕获音频中表达的情绪和意图,并在第二装置处自动再现带有情绪和意图的音频。
背景技术:
1、通过互联网进行通信已经成为主流。随着可用的交互式应用量以及用户当中以及用户与交互式应用之间交换的交互式数据量的增加,内容质量(例如音频质量)变得至关重要。特别是,当用户从不同的地理位置访问交互式应用或通过网络(诸如互联网)与其他用户通信时,内容质量可取决于远程通信设施(计算机、wi-fi连接等)的状态而有很大差异。例如,根据用户使用的通信设施的状态,话音质量可有很大差异。从听起来像在水下的话音到过于尖锐和响亮的话音,很难找到适当的平衡来在线听到其他人的话音。
2、为了减轻这种扭曲,采用语音转文本引擎将用户说出的语音转录为文本。然而,现有的语音转文本引擎可重新创建某人可以说的词语,但却未得到用户所说的词语背后的情绪和意图。像讽刺或兴奋等微妙的暗示很难传达。此外,语音转文本引擎有时无法解读所有文本,由于说出词语的速度或由于语言障碍或由于不同口音。
3、正是在此背景下提出了本公开的实施方案。
技术实现思路
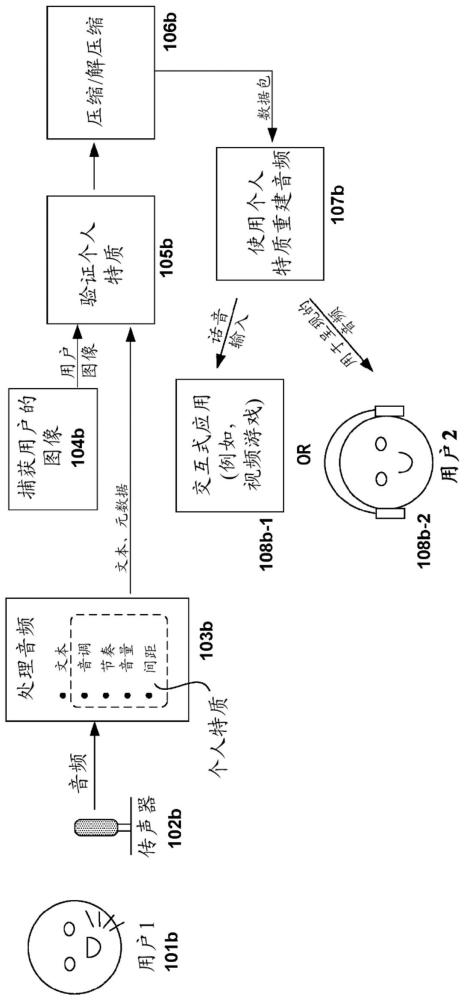
1、本公开的实现方式涉及在第一装置本地捕获音频、将音频转换为文本、分析音频以确定音频的一个或多个特性、将音频的一个或多个特性作为元数据与文本一起存储、将文本和元数据压缩成数据包并通过网络(诸如互联网)将数据包传输到第二装置的系统和方法。从音频确定的一个或多个特性可包括用户的音调、音量、节奏、间距、语调等。这些特性可用于确定生成音频的用户的情绪和意图。传输到第二装置的数据包被解压缩,并且数据包中包含的文本和元数据用于重新创建音频以便在第二装置处呈现。重新创建的音频不仅提供音频的文本,而且还基本上模仿了在第一装置处捕获的用户的情绪和意图。
2、第一装置处产生的音频是模拟信号,其转换成数字格式并传输到第二装置。表示音频的文本的一个或多个特性的元数据在大小上与文本相似,这远小于模拟信号。因此,表示音频的数字格式的数据包的大小要小得多,从而大大减少了通过网络传输到第二装置的文件大小。这些特性有助于在第二装置处重新创建音频。在第二装置处呈现的重新创建的音频更准确地表示了在第一装置处生成的音频中表达的用户的情绪和意图。
3、在一个实现方式中,公开一种用于重新创建音频的方法。该方法包括记录用户在第一装置处产生的音频。对用户的音频进行处理,将语音转换为文本,并标识捕获用户的情绪和口头表达(即意图)的一个或多个特性。一个或多个特性定义音频的元数据。文本和元数据被打包成数据包,通过网络传输到第二装置进行呈现。第二装置远离第一装置定位。数据包中包括的文本和元数据用于在第二装置处重新创建音频。重新创建的音频复制了用户在第一装置处表达的情绪和口头表达。
4、在一个实现方式中,公开一种用于重新创建音频的系统。该系统包括用于捕获用户说出的音频的第一装置。第一装置耦合至第一编解码器。第一编解码器被配置为记录用户在第一装置处说出的音频,处理音频以将语音转换为文本,并标识捕获音频中捕获的用户的情绪和口头表达的一个或多个特性。一个或多个特性定义音频的元数据。第一编解码器还被配置为使用针对音频标识的文本和元数据来生成数据包。通过压缩音频的文本和元数据生成数据包,以便传输到第二装置进行呈现。第二装置远离第一装置定位。第二装置耦合至第二编解码器。第二编解码器被配置为解压缩数据包以提取其中包括的文本和元数据。文本和元数据用于重新创建用户的音频,以便在第二装置处呈现。重新创建的音频复制了在第一装置处生成的用户表达的情绪和口头表达。
5、通过以下结合附图进行的以举例方式说明本公开原理的详细描述,本公开的其他方面和优点将变得显而易见。
技术特征:
1.一种用于重新创建音频的方法,其包括:
2.如权利要求1所述的方法,其中处理所述音频包括,
3.如权利要求1所述的方法,其中处理所述音频还包括,
4.如权利要求1所述的方法,其中所述一个或多个特性中的每个都是可调的以定义所述用户的个人偏好,所述个人偏好被定义为特定于所述用户、特定于所述音频中使用的语言、或特定于交互式应用。
5.如权利要求4所述的方法,其中处理所述音频还包括,
6.如权利要求1所述的方法,其中定义所述元数据的所述一个或多个特性包括语音的语调、音调、说出的词语的间距和音量中的任何一个或组合,定义话音指纹的所述一个或多个特性捕获所述用户的所述情绪和所述口头表达。
7.如权利要求1所述的方法,其中所述第一装置是第一笔记本计算装置或第一移动计算装置,并且其中所述第二装置是服务器计算装置或云服务器计算装置或游戏控制台或第二笔记本计算装置或第二移动计算装置。
8.如权利要求1所述的方法,其中通过将所述音频的语音转换为文本并标识定义所述音频的指纹的所述一个或多个特性来处理所述音频以将模拟信号转换为数字数据,并且其中带有所述音频的所述文本和所述元数据的所述数据包以数字格式传输到所述第二装置。
9.一种用于重新创建音频的系统,其包括:
10.如权利要求9所述的系统,其中所述第一编解码器集成在所述第一装置内,并且所述第二编解码器集成在所述第二装置内。
11.如权利要求9所述的系统,其中所述第一编解码器通信耦合到并且独立于所述第一装置,并且所述第二编解码器通信耦合到并且独立于所述第二装置。
12.如权利要求9所述的系统,其中所述第一装置是第一笔记本计算装置或第一台式计算装置或第一移动计算装置,并且
13.如权利要求9所述的系统,其中所述第一编解码器包括语言解译器,所述语言解译器被配置为根据所述音频中所说的语言来解译在所述第一装置处捕获的所述音频,以标识所述音频的所述一个或多个特性,所述一个或多个特性捕获所述用户用所述语言表达的所述情绪和所述口头表达。
14.如权利要求9所述的系统,其中所述第一装置耦合到图像捕获装置并且配置为接收在所述用户生成所述音频时所述图像捕获装置捕获的所述用户的图像,所述用户的所述图像与所述音频的对应部分相关联,所述第一装置将所述用户的所述图像转发到所述第一编解码器以相对针对所述音频的所述对应部分标识的所述情绪和所述口头表达来验证所述用户的面部表情。
15.如权利要求9所述的系统,其中所述第一编解码器包括一个或多个可调数字旋钮,用于调节所述音频的一个或多个特性以定义所述用户的个人偏好,其中所述第一编解码器被配置为根据所述用户的所述个人偏好处理所述音频。
16.如权利要求15所述的系统,其中所述一个或多个可调数字旋钮被配置为由用户、由交互式应用控制、或者针对所述音频中使用的语言进行调节。
技术总结
用于重新创建音频的方法和系统包括记录用户在第一装置处产生的音频。对音频进行处理以将语音转换为文本,并标识捕获用户的情绪和口头表达的音频的一个或多个特性。通过压缩文本和一个或多个特性来生成数据包,以便传输到第二装置。数据包中包括的文本和元数据用于在第二装置处重新创建音频。
技术研发人员:S·卡普
受保护的技术使用者:索尼互动娱乐股份有限公司
技术研发日:
技术公布日:2024/12/10
- 还没有人留言评论。精彩留言会获得点赞!