一种基于语谱图的声音识别的可解释评价方法
:本发明应用于声音识别和人工智能可解释的交叉领域。
背景技术
0、
背景技术:
1、随着人工智能的发展,机器学习模型的参数越来越多,使得人们难以理解机器所作出的决策。为此,可解释人工智能(explainable artificial intelligence,xai)被提出,致力于使用者理解、信任人工智能。近年来,自动声音识别已广泛应用于多个领域,如动物保护、远洋作业、医疗领域、智慧城市以及智能家居等。这些应用场景中,人们需要根据自动声音识别的结果做出决策,因此,声音识别的可解释变得越发重要。传统的声音识别方法依赖于浅层分类器,如梅尔频率倒谱系数(mfccs)和决策树,这些方法的特点在于模型具有较好的可解释性。然而,基于深度神经网络的声音识别分类器在性能上表现更优越,但其模型结构的复杂性导致其解释性相对不足。在这种背景下,研究人员亟需在提高性能的同时,保持模型的解释能力。
2、在声音识别领域,将声音转化为语谱图并进行识别和解释是一种常见的方法。dissanayake等对心脏跳动声音进行了研究,提出了一个有效监测异常声音的分类器,并对其进行了解释。wang等在此基础上比较了将心音通过不同特征提取方式转化成语谱图的解释效果,认为良好的特征提取方法能够提高模型的可解释性。zinemanas等提出了一种可解释性深度神经网络,它使用音频频率的相似性度量来提供对模型决策的解释。mishra等提出了一种用于音频内容分析的lime算法的变体slime。slime能够生成以时间、频率和时频分割的形式呈现的解释,并已应用于歌声检测。但上述方法仅针对于解释模型识别的结果,而难以去评估其解释的有效性和可靠性。
3、尽管可解释性的重要性受到重视,但如何评估解释的效果尚未有一致的共识。不同的应用场景、解释模型、数据类型和用户需求导致了可解释性评价的重点各不相同,因此很难建立一个被广泛认可的科学评价体系。目前,主要的可解释性评价方法可以大致分为主观评价方法和客观评价方法两类。主观评价方法应用较为广泛。其需要基于用户实验,评价结果受到用户专业认知程度的影响,并且不同用户之间难以形成一致的评价标准。而客观评价方法的应用相对较少。这种方法无需用户的参与,可以自动评估解释的效果。但客观评价方法受限于黑盒模型和应用场景,适用性相对较窄。vilone等分析了现有的解释评价方法,指出了主观评价和客观评价两类方法的局限性,并进行了批判性的探讨。mohseni等设计了一个可以用于跨学科背景的xai评估框架,以指导xai方法的设计。nauta等提出了一组包含12个属性的解释评价标准,旨在提高解释的质量。而miller等则充分借鉴了哲学、心理学和认知科学等领域的专业知识,深入分析了使用户容易理解的解释的特点。这些引用的研究都针对可解释性评价工作的现状,指出了其中存在的不足之处并对未来的评价方法给出建议。对于声音识别领域,寻找一种适用的可解释性评价方法具有重要意义。因此在这一背景下,本发明尝试将声音可解释性与现有的可解释性评价领域相结合,旨在提出一个适用于声音识别的解释评价方法。
4、shap是一种模型无关的、用于解释机器学习模型预测结果的方法,它基于博弈论中的shapley值理论。通过提供全局的特征重要性度量,shap能够解释模型预测的结果。其核心思想在于通过对特征值的排列组合进行分配,计算每个特征对预测结果的贡献度。shap不仅考虑了特征之间的交互作用,还能够提供对模型预测的解释性。在本发明的实施过程中,shap可作为进行解释评价前的衡量特征贡献度的依据。
技术实现思路
0、
技术实现要素:
1、在解释性评估的领域,现有研究主要侧重于评估xai方法的效果,以确定适用于特定场景的解释方法。这可能导致对提升xai方法性能的过度关注,忽视了数据集自身的特征以及训练模型对解释效果的潜在影响。在特定xai方法下,选择适当的特征提取方法和模型对提高解释效果同样具有重要意义。基于此,本发明提出了一种基于客观评价的方法,避免用户主观观点对解释效果的影响的同时,专注于评估不同特征提取方法生成的语谱图本身以及训练时采用的网络模型对解释效果的质量。
2、本发明采用shap这一模型无关的解释方法对声音样本进行特征再处理,理论上适用于所有黑盒模型。本发明的应用场景限定为声音语谱图,结合了语谱图时间和频域特性,设计了一种合理且有效的解释评价方法。主要创新点包括以下两个方面:
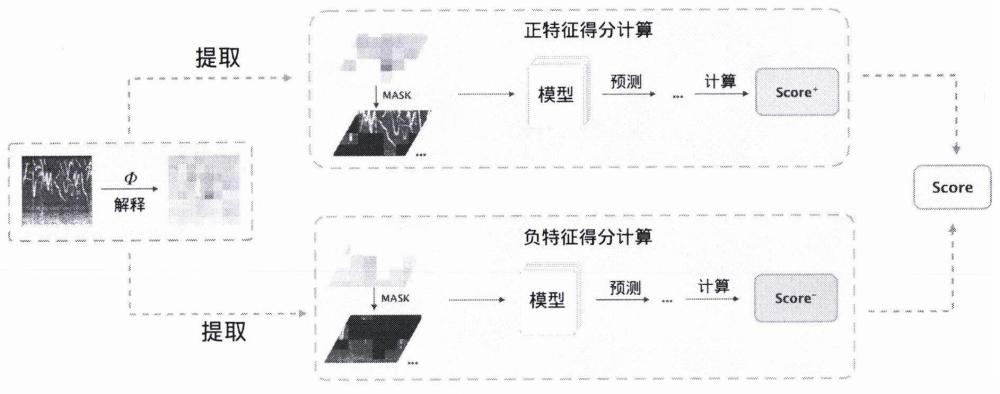
3、1.提出了适用于声音识别的可解释性评价方法ai-score(acoustic spectrograminterpretability score)。该方法将模型的解释结果作为输入,通过特征再处理、二次预测以及相关的计算工作,生成正负两方面有效性的评分指标,最终综合为一个解释评分。
4、2.利用此方法,可以比较不同音频特征提取方法以及在模型训练时采用不同深度神经网络的解释效果。同时,还可以分析不同解释设定参数对解释效果的影响。
技术特征:
1.一种基于语谱图的声音识别的可解释评价方法,分为音频预处理与特征提取、模型训练、模型解释、模型评价四部分,其特征在于:音频预处理与特征提取包含以下三个步骤:
2.根据权利要求1所述的一种基于语谱图的声音识别的可解释评价方法,其特征在于:所述音频预处理与特征提取的步骤(3)中,对音频转化为语谱图的特征提取方法不作限制。支持的方法包括但不限于mel谱图、cqt变换、傅里叶变换等。
3.根据权利要求1所述的一种基于语谱图的声音识别可解释评价方法,其特征在于:所述模型评价的步骤(6)中,特征集划分的方法具体为:
4.根据权利要求1所述的一种基于语谱图的声音识别的可解释评价方法,其特征在于:所述模型评价的步骤(7)中,计算score+的方法具体为:
5.根据权利要求1所述的一种基于语谱图的声音识别的可解释评价方法,其特征在于:所述模型评价的步骤(7)中,计算score-的方法具体为:
技术总结
本发明提出了一种基于语谱图的声音识别的可解释性评价方法AI‑SCORE,属于声音识别和人工智能可解释领域;该方法将模型的解释结果作为输入,通过经过特征处理、二次预测以及相关计算工作,产生正负两方面有效性的评分指标,最终将这些指标综合为一个全面的解释评分,以评估模型的可解释性;本发明旨在于评估声音识别中不同特征提取方法和神经网络的解释效果,以帮助决策者更准确地选择最合适的特征提取方法和网络模型,从而加强用户对于声音识别系统的信任度。
技术研发人员:袁伟伟,卢宁,关东海
受保护的技术使用者:南京航空航天大学
技术研发日:
技术公布日:2024/4/29
- 还没有人留言评论。精彩留言会获得点赞!