一种双声道到多声道的上混方法、装置、存储介质及设备与流程
本申请属于蓝牙音频编解码,特别是涉及一种双声道到多声道的上混方法、装置、存储介质及设备。
背景技术:
1、由于lc3编解码具有较低延迟、较高的音质和编码增益以及在蓝牙领域无专利费的技术优势,受到了广大厂商越来越多的关注。
2、目前蓝牙音箱比较普及,除了欣赏立体声,人们更希望能提高沉浸感。5.1声道环绕声是使用比较广泛的音频格式,因其能提供较好的用户体验。然而,使用蓝牙音箱播放5.1声道的音源有如下挑战:
3、(1)如果音源是5.1声道格式的,那么其应用在蓝牙音箱的数据流为:蓝牙发射端,5.1声道音源->解码为6个声道的pcm信号->对每一个声道进行音频编码(如lc3编码)->将编码后的音频信号发射出去;蓝牙接收端,接受6个声道的音频信号->解码->使用蓝牙音箱播放。不足之处在于空中传输的码率较高,如果每个声道使用124kbps的推荐码率压缩,则空中的总码率为744kbps,虽然对于le audio来说也不是问题,但过高的码率不但会导致音频出现卡顿问题,还会对周围的其他设备造成干扰,对蓝牙的射频前端来说是一大挑战。
4、(2)5.1声道格式的音源偏少,网络上比较的流行的音源以双声道为主,然而,双声道音源的体验感较差,尤其是沉浸感不足。
5、现有的双声道上混到多声道技术中,pca(principal component analysis,主成分分析)使用较多,在杜比环绕声解码器中也有使用,但由于多声道信号间的相关、非线性关系的时变特性,使用pca生成的环绕声与原始的环绕声差别较大,上混音频的空间感和沉浸感不足。
技术实现思路
1、针对现有技术中存在的上述技术问题,本申请提供了一种双声道到多声道的上混方法、装置、存储介质及设备,通过采用深度学习,在蓝牙接收端实现了双声道到多声道的上混,增强了用户的沉浸感,从而提高了用户体验。
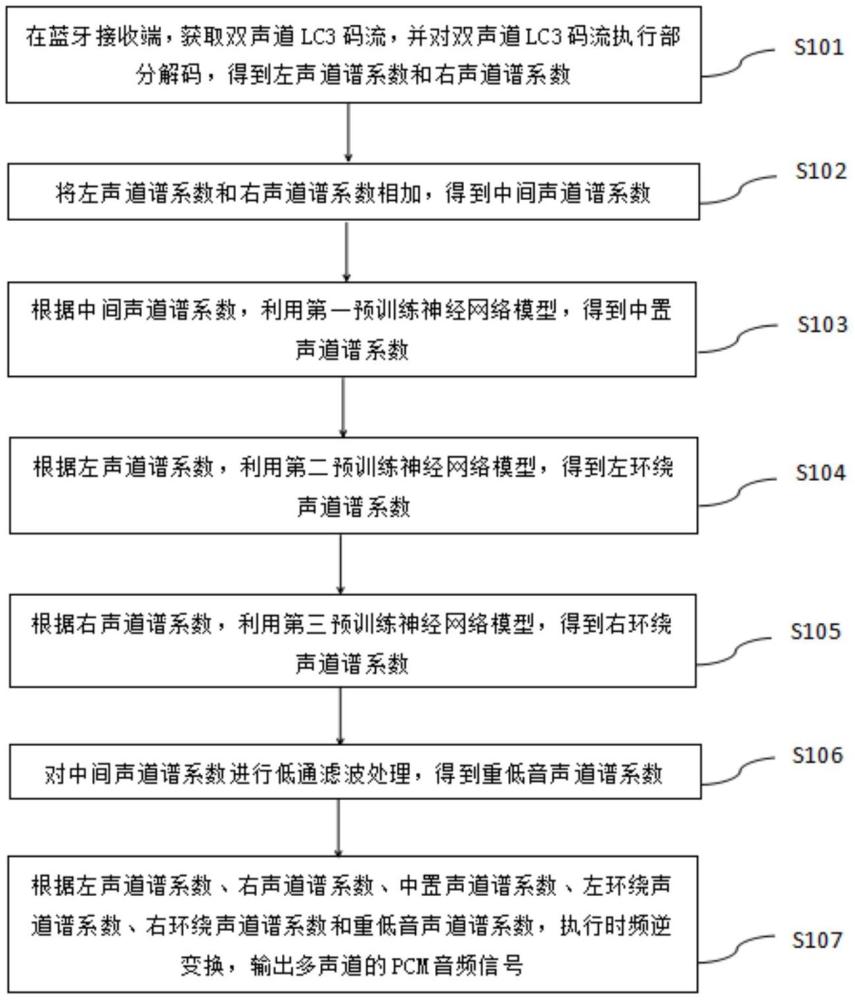
2、为了实现上述目的,本申请采用的第一个技术方案是:提供一种双声道到多声道的上混方法,包括:在蓝牙接收端,获取双声道lc3码流,并对双声道lc3码流执行部分解码,得到左声道谱系数和右声道谱系数;将左声道谱系数和右声道谱系数相加,得到中间声道谱系数;根据中间声道谱系数,利用第一预训练神经网络模型,得到中置声道谱系数;根据左声道谱系数,利用第二预训练神经网络模型,得到左环绕声道谱系数;根据右声道谱系数,利用第三预训练神经网络模型,得到右环绕声道谱系数;对中间声道谱系数进行低通滤波处理,得到重低音声道谱系数;以及根据左声道谱系数、右声道谱系数、中置声道谱系数、左环绕声道谱系数、右环绕声道谱系数和重低音声道谱系数,执行时频逆变换,输出多声道的pcm音频信号。
3、本申请采用的第二个技术方案是:提供一种双声道到多声道的上混装置,包括:用于在蓝牙接收端,获取双声道lc3码流,并对双声道lc3码流执行部分解码,得到左声道谱系数和右声道谱系数的模块;用于将左声道谱系数和右声道谱系数相加,得到中间声道谱系数的模块;用于根据中间声道谱系数,利用第一预训练神经网络模型,得到中置声道谱系数的模块;用于根据左声道谱系数,利用第二预训练神经网络模型,得到左环绕声道谱系数的模块;用于根据右声道谱系数,利用第三预训练神经网络模型,得到右环绕声道谱系数的模块;用于对中间声道谱系数进行低通滤波处理,得到重低音声道谱系数的模块;以及用于根据左声道谱系数、右声道谱系数、中置声道谱系数、左环绕声道谱系数、右环绕声道谱系数和重低音声道谱系数,执行时频逆变换,输出多声道的pcm音频信号的模块。
4、本申请采用的第三个技术方案是:提供一种计算机可读存储介质,其存储有计算机指令,其中计算机指令被操作以执行方案一中的双声道到多声道的上混方法。
5、本申请采用的第四个技术方案是:提供一种计算机设备,其包括处理器和存储器,存储器存储有计算机指令,其中处理器操作计算机指令以执行方案一中的双声道到多声道的上混方法。
6、本申请技术方案可以达到的有益效果是:本申请的技术方案既可以应用于低功耗蓝牙,也可以应用于经典蓝牙,通过利用现有的时频变换和重叠相加技术,避免了算法延时的增加;采用深度学习,在蓝牙接收端,对于原始音源为5.1声道的,只需要以双声道码率进行传输,可以节省空中传输的码率,减少对无线环境的干扰;对于原始音源为双声道的,实现双声道到多声道的上混,增强了用户的沉浸感。
技术特征:
1.一种双声道到多声道的上混方法,其特征在于,包括:
2.如权利要求1所述的双声道到多声道的上混方法,其特征在于,所述根据所述中间声道谱系数,利用第一预训练神经网络模型,得到中置声道谱系数,包括:
3.如权利要求1所述的双声道到多声道的上混方法,其特征在于,所述根据所述左声道谱系数,利用第二预训练神经网络模型,得到左环绕声道谱系数,包括:
4.如权利要求1所述的双声道到多声道的上混方法,其特征在于,所述根据所述右声道谱系数,利用第三预训练神经网络模型,得到右环绕声道谱系数,包括:
5.如权利要求1所述的双声道到多声道的上混方法,其特征在于,所述第一预训练神经网络模型、所述第二预训练神经网络模型和所述第三预训练神经网络模型的训练过程,包括:
6.如权利要求5所述的双声道到多声道的上混方法,其特征在于,所述对所述双声道立体声进行特征提取,得到双声道特征,包括:
7.如权利要求5所述的双声道到多声道的上混方法,其特征在于,所述对所述训练用多声道环绕声进行特征提取,得到多声道特征,包括:
8.一种双声道到多声道的上混装置,其特征在于,包括:
9.一种计算机可读存储介质,其存储有计算机指令,其中所述计算机指令被操作以执行权利要求1-7任一项所述的一种双声道到多声道的上混方法。
10.一种计算机设备,其包括处理器和存储器,所述存储器存储有计算机指令,其中所述处理器操作所述计算机指令以执行权利要求1-7任一项所述的一种双声道到多声道的上混方法。
技术总结
本申请公开了一种双声道到多声道的上混方法、装置、存储介质及设备,属于蓝牙音频编解码技术领域,该方法包括获取双声道LC3码流,并对其执行部分解码,得到左、右声道谱系数;将左、右声道谱系数相加,得到中间声道谱系数;根据中间声道谱系数,利用第一预训练神经模型得到中置声道谱系数;根据左声道谱系数,利用第二预训练神经模型得到左环绕声道谱系数;根据右声道谱系数,利用第三预训练神经模型得到右环绕声道谱系数;对中间声道谱系数低通滤波得到重低音声道谱系数;根据左声道谱系数、右声道谱系数、中置声道谱系数、左环绕声道谱系数、右环绕声道谱系数和重低音声道谱系数,执行时频逆变换,输出多声道的音频。本申请增强了用户的沉浸感。
技术研发人员:李强,王凌志,叶东翔,朱勇
受保护的技术使用者:百瑞互联集成电路(上海)有限公司
技术研发日:
技术公布日:2024/6/18
- 还没有人留言评论。精彩留言会获得点赞!