基于上下文信息的方言变体语音识别模型训练方法及系统与流程
本发明涉及语音识别,特别是涉及一种基于上下文信息的方言变体语音识别模型训练方法及系统。
背景技术:
1、目前,语音识别技术是近年来得到广泛应用的一种自然语言处理技术,它允许计算机识别和理解人类语言的口头表达。然而,方言对于自动语音识别(automatic speechrecognition,asr)系统而言,存在一些独特的挑战,方言在发音、词汇和语法上均与广泛应用于大众的普通话存在显著的差异。因此,传统的asr系统通常难以准确识别各种方言,现有技术有待改进。
技术实现思路
1、本发明提供一种基于上下文信息的方言变体语音识别模型训练方法及系统,解决传统的asr系统难以准确识别各种方言的问题。
2、为解决上述技术问题,本发明第一方面提供一种基于上下文信息的方言变体语音识别模型训练方法,包括:
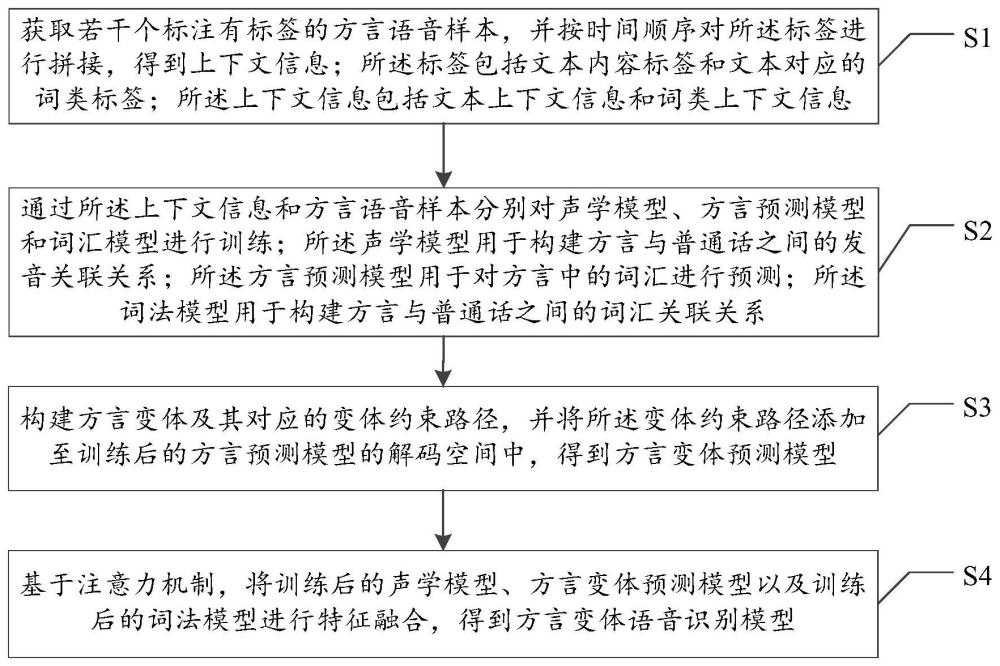
3、获取若干个标注有标签的方言语音样本,并按时间顺序对所述标签进行拼接,得到上下文信息;所述标签包括文本内容标签和文本对应的词类标签;所述上下文信息包括文本上下文信息和词类上下文信息;
4、通过所述上下文信息和方言语音样本分别对声学模型、方言预测模型和词法模型进行训练;所述声学模型用于构建方言与普通话之间的发音关联关系;所述方言预测模型用于对方言中的词汇进行预测;所述词法模型用于构建方言与普通话之间的词汇关联关系;
5、构建方言变体及其对应的变体约束路径,并将所述变体约束路径添加至训练后的方言预测模型的解码空间中,得到方言变体预测模型;
6、基于注意力机制,将训练后的声学模型、方言变体预测模型以及训练后的词法模型进行特征融合,得到方言变体语音识别模型。
7、进一步地,所述通过所述上下文信息和方言语音样本分别对声学模型、方言预测模型和词法模型进行训练,包括:
8、通过所述方言语音样本及其对应的文本内容标签对所述声学模型进行有监督训练,得到训练后的声学模型;
9、通过所述文本上下文信息对所述方言预测模型进行自回归预测训练,得到训练后的方言预测模型;
10、通过所述词类上下文信息和所述方言语音样本及其对应的词类标签对词法模型进行训练,得到训练后的词法模型。
11、进一步地,所述有监督训练的训练准则通过下式表示:
12、
13、式中,lsupervised为声学模型的损失函数;x为方言语音样本;y为文本内容标签;p(x)为方言语音样本的分布函数;θt为第t次迭代训练时的声学模型参数;为文本内容标签的输出概率;a(·)用于增强方言语音样本中的频谱数据。
14、进一步地,所述方言预测模型的训练准则通过下式表示:
15、
16、式中,为方言预测模型的损失函数;q(y)为文本内容标签的分布函数;yi为方言语音样本第i个位置的文本内容标签;y<i为文本上下文信息;φt为第t次迭代训练时的方言预测模型参数;为下一个词汇的预测概率。
17、进一步地,所述词法模型的训练准则通过下式表示:
18、
19、式中,为词法模型的损失函数;q(z)为词类标签的分布函数;zi为方言语音样本第i个位置文本的词类标签;z<i为词类上下文信息;ψi为第t次迭代训练时的词法模型参数;为下一个词的词性预测概率。
20、进一步地,所述构建方言变体及其对应的变体约束路径,并将所述变体约束路径添加至训练后的方言预测模型的解码空间中,得到方言变体预测模型,包括:
21、基于方言变体的先验知识,建立所述方言变体的同义替换列表,并根据所述同义替换列表构建变体约束路径;
22、将所述变体约束路径添加至训练后的方言预测模型的解码空间中,得到约束方言预测模型;
23、对所述约束方言预测模型进行采样,生成若干个方言变体的预测结果并对所述文本上下文信息进行更新;
24、通过更新后的所述文本上下文信息对所述约束方言预测模型进行训练,得到所述方言变体预测模型。
25、进一步地,所述基于注意力机制,将训练后的声学模型、方言变体预测模型以及训练后的词法模型进行特征融合,得到方言变体语音识别模型,包括:
26、在训练后的声学模型的网络层中添加交叉注意力机制模块,将所述方言变体预测模型以及训练后的词法模型的输出层特征送入每一层的注意力机制模块中,并通过所述声学模型的损失函数进行调节,得到融合后的方言变体语音识别模型。
27、本发明第二方面提供一种基于上下文信息的方言变体语音识别模型训练系统,包括:
28、数据获取模块,用于获取若干个标注有标签的方言语音样本,并按时间顺序对所述标签进行拼接,得到上下文信息;所述标签包括文本内容标签和文本对应的词类标签;所述上下文信息包括文本上下文信息和词类上下文信息;
29、模型训练模块,用于通过所述上下文信息和方言语音样本分别对声学模型、方言预测模型和词法模型进行训练;所述声学模型用于构建方言与普通话之间的发音关联关系;所述方言预测模型用于对方言中的词汇进行预测;所述词法模型用于构建方言与普通话之间的词汇关联关系;
30、路径约束模块,用于构建方言变体及其对应的变体约束路径,并将所述变体约束路径添加至训练后的方言预测模型的解码空间中,得到方言变体预测模型;
31、特征融合模块,用于基于注意力机制,将训练后的声学模型、方言变体预测模型以及训练后的词法模型进行特征融合,得到方言变体语音识别模型。
32、本发明第三方面提供一种电子设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如上述第一方面中任意一项所述的基于上下文信息的方言变体语音识别模型训练方法。
33、本发明第四方面提供一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如上述第一方面中任意一项所述的基于上下文信息的方言变体语音识别模型训练方法。
34、与现有技术相比,本发明实施例的有益效果在于:
35、本发明提供一种基于上下文信息的方言变体语音识别模型训练方法及系统,其中方法包括获取若干个标注有标签的方言语音样本,并按时间顺序对所述标签进行拼接,得到上下文信息;通过所述上下文信息和方言语音样本分别对声学模型、方言预测模型和词法模型进行训练;构建方言变体及其对应的变体约束路径,并将所述变体约束路径添加至训练后的方言预测模型的解码空间中,得到方言变体预测模型;基于注意力机制,将训练后的声学模型、方言变体预测模型以及训练后的词法模型进行特征融合,得到方言变体语音识别模型。本发明通过对上下文信息的利用,使得asr系统能够更好地理解方言变体中的语音变化和语境信息,提升了方言变体的语音识别准确性,从而可以为方言语音识别应用带来更为可靠和高效的解决方案。
技术特征:
1.一种基于上下文信息的方言变体语音识别模型训练方法,其特征在于,包括:
2.根据权利要求1所述的一种基于上下文信息的方言变体语音识别模型训练方法,其特征在于,所述通过所述上下文信息和方言语音样本分别对声学模型、方言预测模型和词法模型进行训练,包括:
3.根据权利要求2所述的一种基于上下文信息的方言变体语音识别模型训练方法,其特征在于,所述有监督训练的训练准则通过下式表示:
4.根据权利要求3所述的一种基于上下文信息的方言变体语音识别模型训练方法,其特征在于,所述方言预测模型的训练准则通过下式表示:
5.根据权利要求4所述的一种基于上下文信息的方言变体语音识别模型训练方法,其特征在于,所述词法模型的训练准则通过下式表示:
6.根据权利要求2所述的一种基于上下文信息的方言变体语音识别模型训练方法,其特征在于,所述构建方言变体及其对应的变体约束路径,并将所述变体约束路径添加至训练后的方言预测模型的解码空间中,得到方言变体预测模型,包括:
7.根据权利要求3所述的一种基于上下文信息的方言变体语音识别模型训练方法,其特征在于,所述基于注意力机制,将训练后的声学模型、方言变体预测模型以及训练后的词法模型进行特征融合,得到方言变体语音识别模型,包括:
8.一种基于上下文信息的方言变体语音识别模型训练系统,其特征在于,包括:
9.一种电子设备,其特征在于,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如权利要求1至7中任意一项所述的基于上下文信息的方言变体语音识别模型训练方法。
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行如权利要求1至7中任意一项所述的基于上下文信息的方言变体语音识别模型训练方法。
技术总结
本发明涉及语音识别技术领域,公开了一种基于上下文信息的方言变体语音识别模型训练方法及系统,其中方法包括获取若干个标注有标签的方言语音样本,并按时间顺序对所述标签进行拼接,得到上下文信息;通过所述上下文信息和方言语音样本分别对声学模型、方言预测模型和词法模型进行训练;构建方言变体及其对应的变体约束路径,并将所述变体约束路径添加至训练后的方言预测模型的解码空间中,得到方言变体预测模型;基于注意力机制,将训练后的声学模型、方言变体预测模型以及训练后的词法模型进行特征融合,得到方言变体语音识别模型。本发明充分利用上下文信息,通过生成方言变体的可能选项来辅助系统识别,提升方言变体的语音识别准确性。
技术研发人员:苏立伟,刘振华,谭火超,陈海燕,吴石松,梁飞令,毛莉萍,李兰芳,杨英勃,曾晓锋,简冬琳,冼文祥,石世玉,彭若馨,李静
受保护的技术使用者:广东电网有限责任公司
技术研发日:
技术公布日:2024/6/18
- 还没有人留言评论。精彩留言会获得点赞!