语音生成方法、装置、电子设备及计算机可读存储介质与流程
本申请涉及互联网,特别是涉及一种语音生成方法、装置、电子设备及计算机可读存储介质。
背景技术:
1、tts(text to speech,文本转语音)技术作为一种能够将文本信息转化为语音的技术,已被广泛应用于各种领域,比如在游戏领域中通过将游戏指南、导航信息和剧情对话转化为语音,可以实现更加直观的引导效果和更加自然的玩家与npc之间的交流,提升游戏体验。
2、相关技术中,在基于tts技术进行文本信息的转化时,可以使用如支持向量机、朴素贝叶斯等得机器学习算法来分析文本的情感,并生成相应的语音;或者,还可以使用cnn(convolutional neural networks,卷积神经网络)、rnn(recurrent neural network,循环神经网络)、lstm(long short-term memory,长短期记忆网络)或transformers(变压器网络)等深度学习模型来提取文本的情感特征,使用语音合成技术将情感特征转化为语音。
3、在实现相关技术的过程中,申请人发现相关技术至少存在以下问题:
4、采用机器学习算法和深度学习模型的情感文本转语言方案需要大量的标注数据进行训练,且通过单纯挖掘文本的情感信息容易忽略语音本身所蕴含的情感信息,在一定程度上影响了情感控制的效果,难以准确地识别和处理文本中的情感信息,也无法适应多样化的情感表达需求。
技术实现思路
1、有鉴于此,本申请提供了一种语音生成方法、装置、电子设备及计算机可读存储介质。
2、依据本申请第一方面,提供了一种语音生成方法,该方法包括:
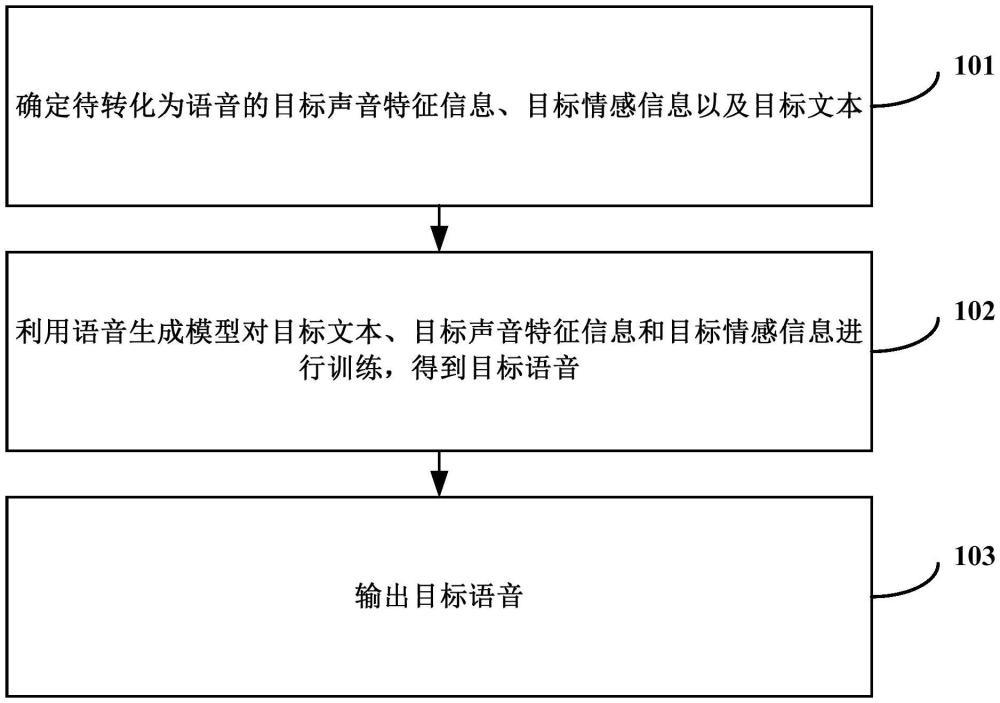
3、确定待转化为语音的目标声音特征信息、目标情感信息以及目标文本;
4、利用语音生成模型对所述目标文本、所述目标声音特征信息和所述目标情感信息进行训练,得到目标语音;其中所述语音生成模型是基于样本文本对应的音素持续时长以及样本语音对应的样本语音特征信息对训练模型训练得到;所述样本语音特征信息包括以下至少一项:样本声音特征信息和样本情感信息;
5、输出所述目标语音。
6、依据本申请第二方面,提供了一种语音生成装置,该装置包括:
7、确定模块,用于确定待转化为语音的目标声音特征信息、目标情感信息以及目标文本;
8、训练模块,用于利用语音生成模型对所述目标文本、所述目标声音特征信息和所述目标情感信息进行训练,得到目标语音;其中所述语音生成模型是基于样本文本对应的音素持续时长以及样本语音对应的样本语音特征信息对训练模型训练得到;所述样本语音特征信息包括以下至少一项:样本声音特征信息和样本情感信息;
9、输出模块,用于输出所述目标语音。
10、依据本申请第三方面,提供了一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面中任一项所述方法的步骤。
11、依据本申请第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面中任一项所述的方法的步骤。
12、借由上述技术方案,本申请提供的一种语音生成方法、装置、电子设备及计算机可读存储介质,本申请确定待转化为语音的目标声音特征信息、目标情感信息以及目标文本,利用基于样本文本对应的音素持续时长以及样本语音对应的样本语音特征信息对训练模型训练得到的语音生成模型对目标文本、目标声音特征信息和目标情感信息进行训练,得到目标语音,输出目标语音,在构建语音生成模型的过程中不仅采用样本文本进行训练,还额外引入了描述语音特点的音素持续时长和样本语音特征信息同时进行监督训练,使得语音生成模型能够准确地识别和处理文本中的情感信息,在进行语音转化时可以生成较为自然的带有情感表达的特定说话人的高质量语音,实现较好的情感语音的生成效果,从而适应多样化的情感表达需求。
13、上述说明仅是本申请技术方案的概述,为了能够更清楚了解本申请的技术手段,而可依照说明书的内容予以实施,并且为了让本申请的上述和其它目的、特征和优点能够更明显易懂,以下特举本申请的具体实施方式。
技术特征:
1.一种语音生成方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述方法还包括:
3.根据权利要求2所述的方法,其特征在于,所述根据所述样本文本以及所述样本语音,确定所述样本文本中每个音素的音素持续时长,包括:
4.根据权利要求3所述的方法,其特征在于,所述对所述样本文本进行音素提取,得到所述样本文本对应的音素,包括:
5.根据权利要求2所述的方法,其特征在于,所述样本声音特征信息包括以下至少一项:基音信息和能量信息;
6.根据权利要求2所述的方法,其特征在于,所述基于每个所述音素的音素持续时长、所述样本声音特征信息以及所述样本情感信息,训练所述语音生成模,包括:
7.根据权利要求6所述的方法,其特征在于,所述采用所述样本声音特征信息和所述样本情感信息,对所述音素序列进行处理,得到音素高维向量,包括:
8.根据权利要求6所述的方法,其特征在于,所述基于预设的语言情感模型结构,对所述音素高维向量、每个所述音素的音素持续时长、所述样本声音特征信息以及所述样本情感信息进行频谱预测,得到预测频谱信息,包括:
9.根据权利要求6所述的方法,其特征在于,所述计算所述预测频谱信息与所述样本频谱信息之间的损失函数,包括:
10.一种语音生成装置,其特征在于,包括:
11.一种电子设备,包括存储器和处理器,所述存储器存储有计算机程序,其特征在于,所述处理器执行所述计算机程序时实现权利要求1至9中任一项所述方法的步骤。
12.一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至9中任一项所述的方法的步骤。
技术总结
本申请公开了一种语音生成方法、装置、电子设备及计算机可读存储介质,涉及互联网技术领域,在构建语音生成模型的过程中额外引入了描述语音特点的音素持续时长和样本语音特征信息同时进行监督训练,使得语音生成模型能够生成较为自然的带有情感表达的特定说话人的高质量语音。所述方法包括:确定待转化为语音的目标声音特征信息、目标情感信息以及目标文本;利用语音生成模型对目标文本、目标声音特征信息和目标情感信息进行训练,得到目标语音;其中语音生成模型是基于样本文本对应的音素持续时长以及样本语音对应的样本语音特征信息对训练模型训练得到;样本语音特征信息包括以下至少一项:样本声音特征信息和样本情感信息;输出目标语音。
技术研发人员:刘博翀,柳毅恒,刘炎,覃建策,陈邦忠
受保护的技术使用者:完美世界(北京)软件科技发展有限公司
技术研发日:
技术公布日:2024/11/21
- 还没有人留言评论。精彩留言会获得点赞!