基于音高调制的音频稀疏对抗攻击方法、装置、设备及介质
本发明涉及音频稀疏对抗攻击,具体涉及基于音高调制的音频稀疏对抗攻击方法、装置、设备及介质。
背景技术:
1、当前尽管深度神经网络在图像检测、目标跟踪和自动语音识别等不同领域中取得了很高的准确性,但当输入中加入小而强大的对抗性扰动时,其性能会显著下降。对抗性攻击这一重大安全威胁的出现引起了各研究领域的关注。对抗性攻击有可能通过扰乱人类无法察觉的良性样本,大大降低预训练深度神经网络的准确性。在asr领域中,大多数攻击者倾向于向音频中注入恶意扰动,以操纵asr系统,从而引发安全问题。
2、为了探讨音频对抗样本所带来的威胁,市面上已经制定了多种不同的方法。现有的攻击可以分为有目标攻击和无目标攻击。在无目标攻击的背景下,早期的研究工作旨在创建导致错误和随机转录的对抗样本。对于有目标攻击,carlini 和 wagner有效地扩展了他们基于迭代的方法,生成了有目标的对抗性音频样本,使asr系统将受到攻击的音频识别为预期的转录结果。随后,研究人员一直在努力提高有目标音频攻击的鲁棒性和隐蔽性。例如,qin 等人利用心理声学的听觉掩蔽原理设计了隐蔽、鲁棒且有目标的对抗性音频样本。这些攻击在先进的lingvo asr系统上达到了100%的成功率。liu等人在损失函数中应用了一种去噪方法,使噪声不可检测,这种方法为稀疏噪声生成设立了基础性基准。此外,yu等人优化了非噪声音频属性,以生成鲁棒且人耳难以察觉的对抗性样本,推动了音频对抗性研究的边界。
3、上述方法虽然有效地增强了音频攻击的不可感知性,但同时将对抗性噪声引入无声音频片段,无意中提高了可感知性。此外,由于音频识别固有的时间特征,在音频域内执行稀疏攻击提出了巨大的挑战。目前,优化技术仅达到了约25% 的噪声归零率。现有的音频攻击由于其在整个音频频谱中广泛分布的噪声,导致了更显著的扰动。这种方法涉及全面注入生成的噪声,增加了所产生的对抗样本的可察觉性——随着音频时长的增加,这种效果会更加明显。此外,目标语音中存在的无声片段会增强所插入噪声的可察觉性,就像在白纸上画黑线一样。现有研究表明,使用稀疏攻击需要在噪声搜索域中做出让步,导致生成的噪声相比于全局攻击策略有显著增加。
4、有鉴于此,提出本申请。
技术实现思路
1、本发明提供了一种基于音高调制的音频稀疏对抗攻击方法、装置、设备及介质,能至少部分的改善上述问题。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于音高调制的音频稀疏对抗攻击方法,其包括:
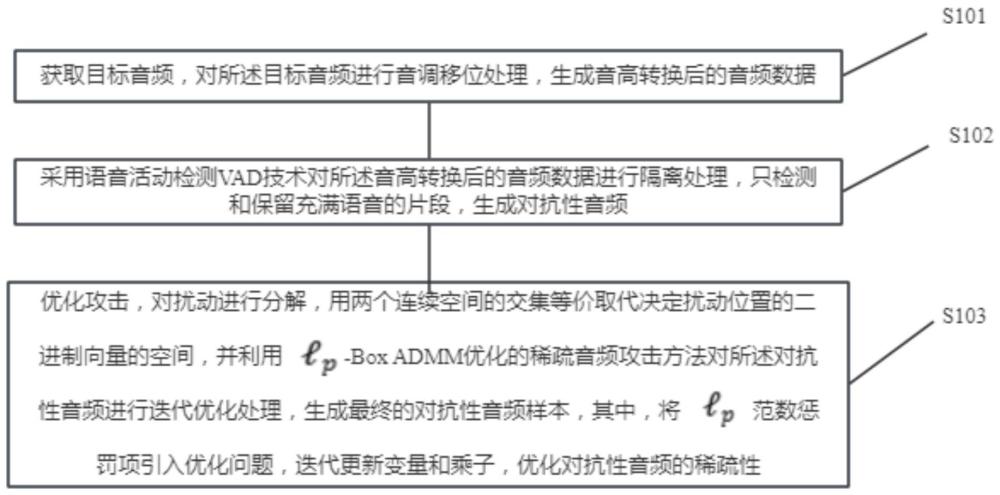
4、获取目标音频,对所述目标音频进行音调移位处理,生成音高转换后的音频数据;
5、采用语音活动检测vad技术对所述音高转换后的音频数据进行隔离处理,只检测和保留充满语音的片段,生成对抗性音频;
6、优化攻击,对扰动进行分解,用两个连续空间的交集等价取代决定扰动位置的二进制向量的空间,并利用-box admm优化的稀疏音频攻击方法对所述对抗性音频进行迭代优化处理,生成最终的对抗性音频样本,其中,将范数惩罚项引入优化问题,迭代更新变量和乘子,优化对抗性音频的稀疏性。
7、本发明还提供了一种基于音高调制的音频稀疏对抗攻击装置,其包括:
8、音调移位单元,用于获取目标音频,对所述目标音频进行音调移位处理,生成音高转换后的音频数据;
9、语音活动检测单元,用于采用语音活动检测vad技术对所述音高转换后的音频数据进行隔离处理,只检测和保留充满语音的片段,生成对抗性音频;
10、稀疏噪声生成单元,用于优化攻击,对扰动进行分解,用两个连续空间的交集等价取代决定扰动位置的二进制向量的空间,并利用-box admm优化的稀疏音频攻击方法对所述对抗性音频进行迭代优化处理,生成最终的对抗性音频样本,其中,将范数惩罚项引入优化问题,迭代更新变量和乘子,优化对抗性音频的稀疏性。
11、本发明还提供了一种基于音高调制的音频稀疏对抗攻击设备,包括存储器以及处理器,所述存储器内存储有计算机程序,所述计算机程序能够被所述处理器执行,以实现如上任意一项所述的基于音高调制的音频稀疏对抗攻击方法。
12、本发明还提供了一种计算机可读存储介质,存储有计算机程序,所述计算机程序能够被所述计算机可读存储介质所在设备的处理器执行,以实现如上任意一项所述的基于音高调制的音频稀疏对抗攻击方法。
13、综上,所述基于音高调制的音频稀疏对抗攻击方法的攻击流程如下:首先进行音调移位,将输入音频进行音调移位,以改变音频的频率并引发asr系统的初步误识别。之后使用语音活动检测识别音频中的活跃语音片段,生成二进制掩码以标识这些片段。然后进行稀疏噪声生成,其包含以下步骤:初始化:初始化扰动向量和掩码向量。扰动优化:固定掩码向量,通过梯度下降法优化扰动向量。掩码优化:固定扰动向量,通过-box admm算法优化掩码向量。迭代更新:交替优化扰动向量和掩码向量,直到生成的对抗性音频能够成功欺骗asr系统。最终将优化后的扰动向量与掩码向量相结合,生成最终的对抗性音频样本,使其能够有效攻击asr系统并且难以被人耳察觉。通过上述方法,实现了在保持对抗性音频可听性的同时,简化攻击过程并提高了对抗性噪声的隐蔽性和有效性。
14、所述基于音高调制的音频稀疏对抗攻击方法旨在增强自动语音识别(asr)系统的漏洞利用。通过对音频信号进行音高调整和使用声音活动检测(vad)技术并结合-boxadmm技术优化稀疏噪声的生成过程,本方法生成稀疏且难以察觉的对抗性噪声,从而提高攻击的隐蔽性和有效性。
技术特征:
1.一种基于音高调制的音频稀疏对抗攻击方法,其特征在于,包括:
2.根据权利要求1所述的基于音高调制的音频稀疏对抗攻击方法,其特征在于,获取目标音频,对所述目标音频进行音调移位处理,生成音高转换后的音频数据,具体为:
3.根据权利要求2所述的基于音高调制的音频稀疏对抗攻击方法,其特征在于,使用levenshtein距离作为评估指标,量化音调移位的效果,levenshtein距离越大,说明误导效果越好。
4.根据权利要求1所述的基于音高调制的音频稀疏对抗攻击方法,其特征在于,采用语音活动检测vad技术对所述音高转换后的音频数据进行隔离处理,只检测和保留充满语音的片段,生成对抗性音频,具体为:
5.根据权利要求4所述的基于音高调制的音频稀疏对抗攻击方法,其特征在于,优化攻击,对扰动进行分解,用两个连续空间的交集等价取代决定扰动位置的二进制向量的空间,具体为:
6.根据权利要求5所述的基于音高调制的音频稀疏对抗攻击方法,其特征在于,利用-box admm优化的稀疏音频攻击方法对所述对抗性音频进行迭代优化处理,具体为:
7.一种基于音高调制的音频稀疏对抗攻击装置,其特征在于,包括:
8.一种基于音高调制的音频稀疏对抗攻击设备,其特征在于,包括存储器以及处理器,所述存储器内存储有计算机程序,所述计算机程序能够被所述处理器执行,以实现如权利要求1至6任意一项所述的基于音高调制的音频稀疏对抗攻击方法。
9.一种计算机可读存储介质,其特征在于,存储有计算机程序,所述计算机程序能够被所述计算机可读存储介质所在设备的处理器执行,以实现如权利要求1至6任意一项所述的基于音高调制的音频稀疏对抗攻击方法。
技术总结
本发明提供了基于音高调制的音频稀疏对抗攻击方法、装置、设备及介质,包括:进行音调移位,将输入音频进行音调移位,以改变音频的频率并引发ASR系统的初步误识别;使用语音活动检测识别音频中的活跃语音片段,生成二进制掩码以标识这些片段;进行稀疏噪声生成;将优化后的扰动向量与掩码向量相结合,生成最终的对抗性音频样本,使其能够有效攻击ASR系统并且难以被人耳察觉。本发明实现了在保持对抗性音频可听性的同时,简化攻击过程并提高了对抗性噪声的隐蔽性和有效性。
技术研发人员:杜侠,谢旺泽,许奇臻,谢小竹,朱顺痣
受保护的技术使用者:厦门理工学院
技术研发日:
技术公布日:2024/8/13
- 还没有人留言评论。精彩留言会获得点赞!