一种语音情感识别方法、装置、设备及存储介质与流程
本申请涉及语音处理,尤其涉及一种语音情感识别方法、装置、设备及存储介质。
背景技术:
1、语音情感识别技术是人工智能领域的一个重要分支,它通过分析语音信号的音调、节奏、强度等特征,来识别说话人的情感状态。这项技术在智能语音客服、社交媒体监控、健康护理、教育等多个领域都有着广泛的应用前景。
2、在智能语音客服领域,情感识别技术的应用尤为显著。智能客服系统通过分析用户的语音,可以实时地识别出用户的情绪,比如愤怒、快乐、悲伤或焦虑等。这种能力使得客服系统不仅能够理解用户的字面意思,还能够感知用户的情绪需求,从而提供更加人性化的服务。例如,当系统识别到用户情绪激动时,可以自动调整回复的语气,使用更加温和和安抚的语言来回应用户,以平息用户的情绪。
3、然而,当前的语音情感识别技术还存在一些局限性。最主要的问题在于,大多数情感识别系统主要依赖于音频信号的分析,而忽略了文本内容和上下文环境对情感预测的重要性。语言的多义性和上下文的复杂性使得相同的一句话在不同的语境中可能表达出完全不同的情感色彩。例如,"你真棒"这句话在不同的情境下可能表示赞扬,也可能带有讽刺的意味。
4、因此,如何提供一种多尺度跨模态的语音情感识别方法、装置、设备及存储介质是本领域技术人员急需解决的。
技术实现思路
1、本申请提供了一种语音情感识别方法、装置、设备及存储介质,解决了当前情感识别系统主要依赖于音频信号的分析,而忽略了文本内容和上下文环境对情感预测的重要性,导致的语音情感识别有误的技术问题。
2、有鉴于此,本申请第一方面提供了一种语音情感识别方法,所述方法包括:
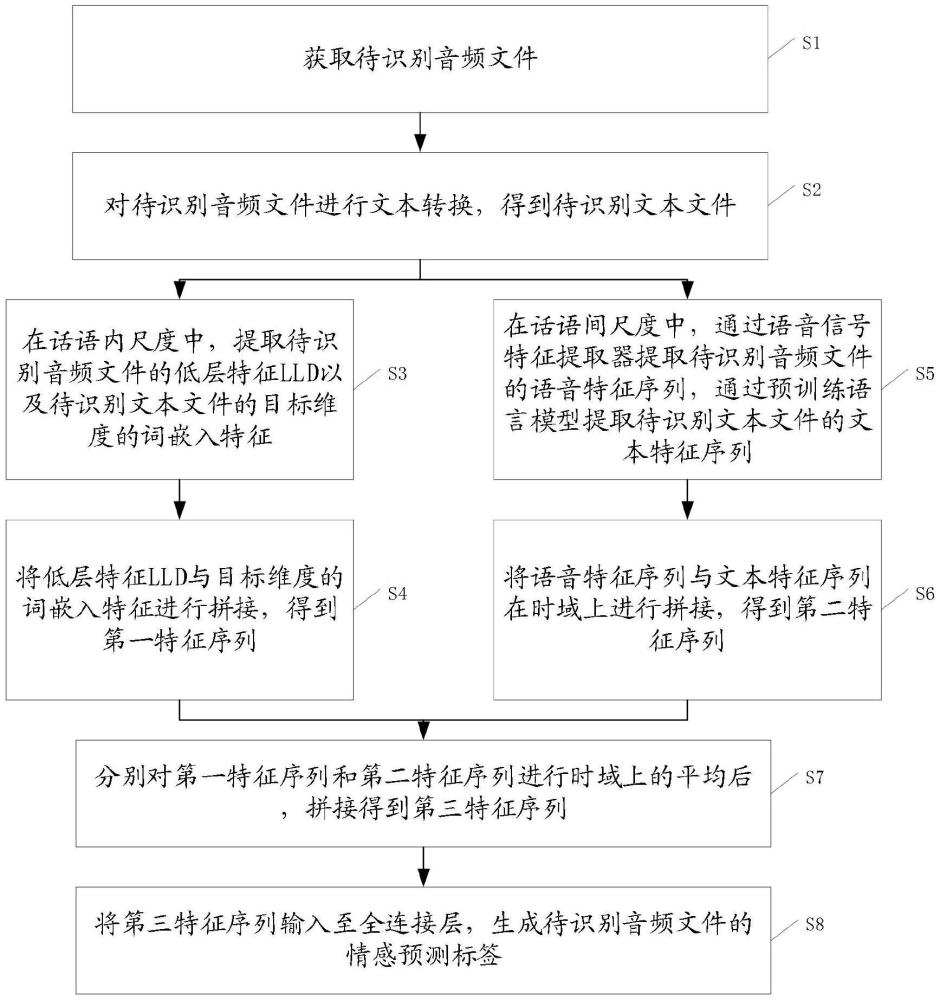
3、步骤s1、获取待识别音频文件;
4、步骤s2、对所述待识别音频文件进行文本转换,得到待识别文本文件;
5、步骤s3、在话语内尺度中,提取所述待识别音频文件的低层特征lld以及所述待识别文本文件的目标维度的词嵌入特征;
6、步骤s4、将所述低层特征lld与所述目标维度的词嵌入特征进行拼接,得到第一特征序列;
7、步骤s5、在话语间尺度中,通过语音信号特征提取器提取所述待识别音频文件的语音特征序列,通过预训练语言模型提取所述待识别文本文件的文本特征序列;
8、步骤s6、将所述语音特征序列与所述文本特征序列在时域上进行拼接,得到第二特征序列;
9、步骤s7、分别对所述第一特征序列和所述第二特征序列进行时域上的平均后,拼接得到第三特征序列;
10、步骤s8、将所述第三特征序列输入至全连接层,生成所述待识别音频文件的情感预测标签。
11、可选地,所述步骤s2之后,所述步骤s3之前还包括:
12、根据所述待识别文本文件,确定所述待识别音频文件的话语内尺度以及话语间尺度,所述话语内尺度为一个短句长度,所述话语间尺度为当前短句及其前后短句的长度。
13、可选地,所述步骤s3具体包括:
14、在话语内尺度中,以预设时间窗以及窗位移,通过音频处理库提取所述待识别音频文件的低层特征lld,所述低层特征lld包含16个第一特征以及第一特征的一阶差分;
15、在话语内尺度中,通过glove算法提取所述待识别文本文件的50维度的词嵌入特征。
16、可选地,所述步骤s4具体包括:
17、将包含16份第一特征以及第一特征的一阶差分的所述低层特征lld与所述50维度的词嵌入特征进行拼接,得到每个时间步上的82维的第一特征序列;
18、基于自注意力机制对所述第一特征序列进行权重分配。
19、可选地,所述步骤s5具体包括:
20、在话语间尺度中,通过语音信号特征提取器提取所述待识别音频文件中每个时间步内当前短句及其前后短句的768维的语音特征序列,通过预训练语言模型提取所述待识别文本文件中每个时间步内当前短句及其前后短句的768维的文本特征序列。
21、可选地,所述步骤s6具体包括:
22、将所述768维的语音特征序列与所述768维的文本特征序列在时域上进行拼接,得到每个时间步1535维的第二特征序列;
23、将所述每个时间步1535维的第二特征序列经过隐单元个数为128,128的全连接层进行降维后,基于自注意力机制对所述第二特征序列进行权重分配。
24、可选地,所述步骤s8具体包括:
25、将所述第三特征序列输入至隐单元个数为128,64,分类数为4的全连接层,生成所述待识别音频文件中当前短句的情感预测标签。
26、本申请第二方面提供一种语音情感识别装置,所述装置包括:
27、获取单元,用于获取待识别音频文件;
28、转换单元,用于对所述待识别音频文件进行文本转换,得到待识别文本文件;
29、第一特征提取单元,用于在话语内尺度中,提取所述待识别音频文件的低层特征lld以及所述待识别文本文件的目标维度的词嵌入特征;
30、第一特征拼接单元,用于将所述低层特征lld与所述目标维度的词嵌入特征进行拼接,得到第一特征序列;
31、第二特征提取单元,用于在话语间尺度中,通过语音信号特征提取器提取所述待识别音频文件的语音特征序列,通过预训练语言模型提取所述待识别文本文件的文本特征序列;
32、第二特征拼接单元,用于将所述语音特征序列与所述文本特征序列在时域上进行拼接,得到第二特征序列;
33、第三特征拼接单元,用于分别对所述第一特征序列和所述第二特征序列进行时域上的平均后,拼接得到第三特征序列;
34、语音情感识别单元,用于将所述第三特征序列输入至全连接层,生成所述待识别音频文件的情感预测标签。
35、本申请第三方面提供一种语音情感识别设备,所述设备包括处理器以及存储器:
36、所述存储器用于存储程序代码,并将所述程序代码传输给所述处理器;
37、所述处理器用于根据所述程序代码中的指令,执行如上述第一方面所述的语音情感识别的方法的步骤。
38、本申请第四方面提供一种计算机可读存储介质,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行上述第一方面所述的方法。
39、从以上技术方案可以看出,本申请实施例具有以下优点:
40、本申请中,提供了一种语音情感识别方法、装置、设备及存储介质,通过对待识别音频文件对应的待识别文本文件分别进行话语间尺度以及话语内尺度的特征提取,理解当前短句及其前后短句的情感关系,进一步地准确对当前短句的语音情感识别,避免因上下文理解不当导致的情感识别有误的情况,解决了当前情感识别系统主要依赖于音频信号的分析,而忽略了文本内容和上下文环境对情感预测的重要性,导致的语音情感识别有误的技术问题。
技术特征:
1.一种语音情感识别方法,其特征在于,包括:
2.根据权利要求1所述的语音情感识别方法,其特征在于,所述步骤s2之后,所述步骤s3之前还包括:
3.根据权利要求2所述的语音情感识别方法,其特征在于,所述步骤s3具体包括:
4.根据权利要求3所述的语音情感识别方法,其特征在于,所述步骤s4具体包括:
5.根据权利要求4所述的语音情感识别方法,其特征在于,所述步骤s5具体包括:
6.根据权利要求5所述的语音情感识别方法,其特征在于,所述步骤s6具体包括:
7.根据权利要求6所述的语音情感识别方法,其特征在于,所述步骤s8具体包括:
8.一种语音情感识别装置,其特征在于,包括:
9.一种语音情感识别设备,其特征在于,所述设备包括处理器以及存储器:
10.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质用于存储程序代码,所述程序代码用于执行权利要求1-7任一项所述的语音情感识别方法。
技术总结
本申请公开了一种语音情感识别方法、装置、设备及存储介质,通过对待识别音频文件对应的待识别文本文件分别进行话语间尺度以及话语内尺度的特征提取,理解当前短句及其前后短句的情感关系,进一步地准确对当前短句的语音情感识别,避免因上下文理解不当导致的情感识别有误的情况,解决了当前情感识别系统主要依赖于音频信号的分析,而忽略了文本内容和上下文环境对情感预测的重要性,导致的语音情感识别有误的技术问题。
技术研发人员:张旭龙,王健宗,程宁,孙一夫
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/11/28
- 还没有人留言评论。精彩留言会获得点赞!