基于声音听诊器的心肺音降噪方法及系统与流程
本发明涉及电子听诊器及其收集心肺音数据处理,尤其是一种基于声音听诊器的心肺音降噪方法及系统。
背景技术:
1、心血管疾病被公认为全世界死亡的主要原因,全球约三分之一的死亡与心血管有关。除了临床表现外,特定的临床检查结果还可以帮助治疗和预防心血管病,其最初可能表现为肺部病变,因此,准确的心肺听诊对于建立准确的诊断至关重要。
2、传统的心肺音数据降噪算法对于简单噪音环境能到达5-10db的信噪比增益,比如只包括固定噪声、突发噪声的环境,但是面临更复杂的环境,包括混杂人声、室外机动车等多种噪音源的复杂环境效果没有特别好的改善,对于真实诊所的听诊器使用情况都会影响心肺音数据的收集效果,直接导致医生无法给出诊断结果,从而会极大降低诊所医生的听诊器产品使用体验。
技术实现思路
1、本发明针对上述问题,提供一种基于声音听诊器的心肺音降噪方法及系统,相比噪音数据和传统方法信噪比有了明显提升。
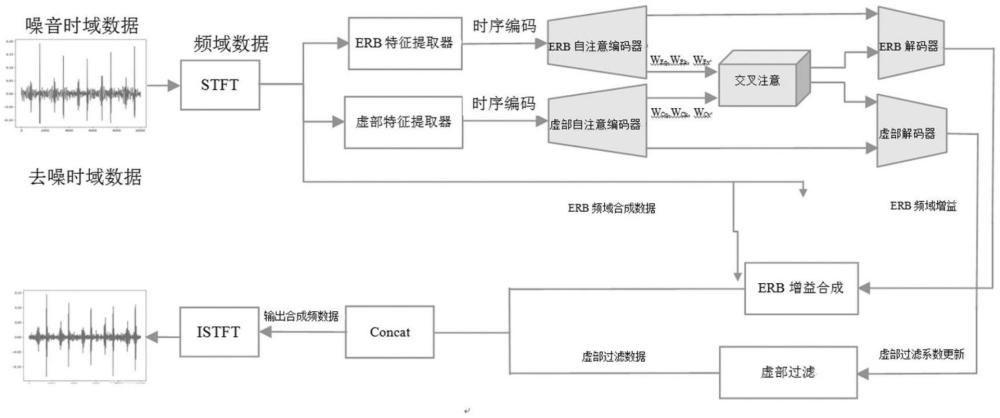
2、为此,本发明采取如下技术方案:基于声音听诊器的心肺音降噪方法,通过采集模块采集心肺音,通过模数转换器转换为数字形式并进行存储,其特征在于对存储的心肺音数据通过传统时频降噪处理和深度学习算法降噪处理,所述的深度学习算法降噪处理包括干净的心肺音数据集和噪声数据集构建:
3、干净的心肺音数据集包括自收集数据、开源心音数据集和开源肺音数据集,所述的自收集数据包括在夜晚环境下(实际监测诊所环境音量20db以下)听诊器采集的心肺音数据(每个不超过30s)和在白天环境下(实际监测诊所环境音量40db以下)听诊器采集的心肺音数据(每个不超过30s)1万多条,总时间超过100小时,实际采集数据来源各类人群;
4、所述的噪声数据集包括两部分,一部分是在白天噪声环境下听诊器采集的真实诊所环境噪声和夜晚环境下听诊器收集到的环境声音数据,总时间超过50小时,另一部分是在开源数据集audioset和freesound中挑选多个不同类别音频通过扬声器播放给听诊器记录,总时间超过20小时;
5、带噪音的心肺音数据通过干净的心肺音数据和噪声数据集随机合成而得到,将得到数据集进行降噪和除杂音处理,步骤如下:
6、(1)将合成的带噪音心肺音数据和干净的心肺音数据按照训练、测试和验证比例进行划分;
7、(2)每条数据进行短时傅里叶变换(stft),短时窗口为20ms,最低频率为50hz,overlap为50%,得到数据的频域数据(包括频域图的实部和虚部数据);
8、(3)对频域数据通过erb等效矩形带宽(equivalent rectangular bandwidth)特征提取器和虚部特征(complex feature)提取器进行提取;
9、(4)对步骤3中提取的数据分别通过erb自注意编码器和虚部自注意解码器进行时序编码,编码器的输入为erb特征+时序特征(虚数特征+时序特征),时序特征按照短时帧窗口的顺序进行时序位置编码;
10、(5)进行交叉注意,交叉注意是把erb编码器和虚部解码器关联起来,从而学习频谱的实部和虚部特征的时序特征相关性的参数矩阵;
11、(6)将erb编码和虚部编码通过解码器的数据进行合成和过滤,并拼接成输出数据的频域数据;
12、(7)将频域表示的信号重新转换回时域表示,得到去噪的声频数据。
13、作为优选,所述步骤(4)中自注意编码器的自注意力函数为erb特征+时序特征(虚数特征+时序特征)的嵌入查询和一组键值对映射到输出,其中q、k、v(查询、键、值)都是自身嵌入向量矩阵,d为嵌入向量维度大小,t为矩阵操作,自注意力计算公式如下:
14、
15、作为优选,所述步骤(1)中将合成的噪音心肺音数据和干净的心肺音数据总共按照70%/15%/15%的训练、测试和验证比例进行划分。
16、作为优选,自收集心肺音数据来源7人,年龄结构分布如下:20岁以下下1人,20岁-40岁2人,40岁以上4人。
17、作为优选,所述的传统时频降噪处理方法如下:
18、(a)将听诊器收集的心肺音数据进行分帧为每帧160个采样点(采样率最高为44100hz),然后计算每帧的能量和(幅度平方和),进行离散傅里叶变换(fft),包含256个点的函数值,同时计算能量谱、幅度谱、对数能量谱和对数幅度谱,根据这些数据进行噪声谱估计;
19、(b)接下来每帧的先验和后验snr,所谓先验snr是纯净信号功率谱与噪声功率谱的比值(理想值),而后验snr是带噪信号功率谱与噪声功率谱的比值,使用上一帧计算的先验snr(估计值)和瞬时snr进行平滑的结果作为先验snr的结果,利用算好的snr更新lrt(likelihood rate test,似然比检验)均值特征、频谱平坦度和频谱差异度三个特征;
20、(c)计算语音和噪声的概率,并更新噪声谱;
21、(d)最后维纳滤波计算,通过计算的信噪概率,得到当前帧的实部和虚部修正系数(频域),通过ifft(傅里叶逆变换)和帧合成操作得到最好的降噪声音数据。
22、本发明还公开了一种基于声音听诊器的心肺音降噪系统,其特征在于包括心肺听诊器声音信号采集模块和声音信号处理降噪模块,所述的声音信号处理降噪模块根据上述的方法进行降噪和去除杂音。
23、作为优选,所述的心肺听诊器声音信号采集模块包括发射器和接收器,所述的发射器包括前端电路、传感器模块、微控制器、wifi模块和pc连接模块,所述的前端电路包括信号采集和预处理电路:传感器模块包括带两个隔膜的麦克风和压电传感器,听诊器隔膜检测声音信号,然后将其传输到麦克风内的另一个隔膜然后再传到压电传感器。
24、作为优选,所述的预处理电路由初级放大电路,滤波电路和二次放大电路组成。
25、本发明通过干净的心肺音数据集和噪声数据集合成得到带噪音的心肺音数据,再将带噪音的心肺音数据和干净的心肺音数据进行训练、测试和验证,通过采用传统和深度学习模型的算法对声音信号进行进一步的降噪和去除杂音,相比噪音数据和传统方法信噪比有了明显提升,能够应对更为复杂的外界环境进行心肺音提取。
技术特征:
1.基于声音听诊器的心肺音降噪方法,通过采集模块采集心肺音,通过模数转换器转换为数字形式并进行存储,其特征在于对存储的心肺音数据通过传统时频降噪处理和深度学习算法降噪处理,所述的深度学习算法降噪处理过程包括干净的心肺音数据集和噪声数据集构建:
2.根据权利要求1所述的基于声音听诊器的心肺音降噪方法,其特征在于所述步骤(4)中自注意编码器的自注意力函数为erb特征+时序特征(虚数特征+时序特征)的嵌入查询和一组键值对映射到输出,其中q、k、v(查询、键、值)都是自身嵌入向量矩阵,d为嵌入向量维度大小,t为矩阵操作,自注意力计算公式如下:
3.根据权利要求1所述的基于声音听诊器的心肺音降噪方法,其特征在于所述步骤(1)中将合成的噪音心肺音数据和干净的心肺音数据总共按照70%/15%/15%的训练、测试和验证比例进行划分。
4.根据权利要求1所述的基于声音听诊器的心肺音降噪方法,其特征在于自收集心肺音数据来源7人,年龄结构分布如下:20岁以下下1人,20岁-40岁2人,40岁以上4人。
5.根据权利要求1或2所述的基于声音听诊器的心肺音降噪方法,其特征在于所述的传统时频降噪处理方法如下:
6.一种基于声音听诊器的心肺音降噪系统,其特征在于包括心肺听诊器声音信号采集模块和声音信号处理降噪模块,所述的声音信号处理降噪模块根据权利要求1-5任一所述的方法进行降噪和去除杂音。
7.根据权利要求6所述的一种基于声音听诊器的心肺音降噪系统,其特征在于所述的心肺听诊器声音信号采集模块包括发射器和接收器,所述的发射器包括前端电路、传感器模块、微控制器、wifi模块和pc连接模块,所述的前端电路包括信号采集和预处理电路:传感器模块包括带两个隔膜的麦克风和压电传感器,听诊器隔膜检测声音信号,然后将其传输到麦克风内的另一个隔膜然后再传到压电传感器。
8.根据权利要求7所述的一种基于声音听诊器的心肺音降噪系统,其特征在于所述的预处理电路由初级放大电路,滤波电路和二次放大电路组成。
技术总结
本发明涉及基于声音听诊器的心肺音降噪方法及系统。传统的心肺音数据降噪算法在面临复杂环境下表现不佳导致医生无法给出准确诊断结果。本发明通过采集模块采集心肺音,通过模数转换器转换为数字形式并进行存储,再对存储的心肺音数据通过传统时频降噪处理和深度学习算法降噪处理,深度学习算法降噪处理包括干净的心肺音数据集和噪声数据集构建,带噪音的心肺音数据通过干净的心肺音数据和噪声数据集随机合成而得到,将得到数据集进行降噪和除杂音处理。本发明通过采用传统和深度学习模型的算法对声音信号进行进一步的降噪和去除杂音,相比噪音数据和传统方法信噪比有了明显提升,能够应对更为复杂的外界环境进行心肺音提取。
技术研发人员:黄浩,李志宇,梁大盛,叶硕,杨帆,张凯
受保护的技术使用者:杭州长济医疗科技有限公司
技术研发日:
技术公布日:2025/1/16
- 还没有人留言评论。精彩留言会获得点赞!