一种基于多模型集成的鸟声识别方法
本发明涉及鸟声识别,具体涉及一种基于多模型集成的鸟声识别方法。
背景技术:
1、在鸟类声学监测领域,分析鸟类叫声是了解其行为、健康状况及生态环境变化的重要手段,广泛应用于生态研究、保护区监测和鸟类行为学研究。目前,特征融合和深度学习等技术逐渐被应用于鸟声识别任务中,如多维特征融合算法和卷积神经网络等。尽管特征融合方法在特征提取方面增强了数据的表征能力,但也可能引入更多噪音,增加风险,从而导致识别准确率的降低。现有技术中,特征融合方法虽然提高了数据表征能力,但可能引入额外噪音,导致识别准确率降低。同时,单一深度学习模型在处理鸟声的多样性和复杂性方面存在局限,难以全面捕捉鸟声的丰富特征,从而影响识别性能。
技术实现思路
1、发明目的:本发明的目的是提供一种基于多模型集成的鸟声识别方法,在通过引入多模型集成策略,解决现有鸟声识别技术中的识别准确率较低的问题。
2、技术方案:本发明所述的一种基于多模型集成的鸟声识别方法,包括以下步骤:
3、(1)获取鸟声信号并对对数据进行预处理;
4、(2)结合梅尔频率倒谱系数、短时傅里叶变换和分贝转换特征提取方法,从鸟声数据中提取出关键特征;
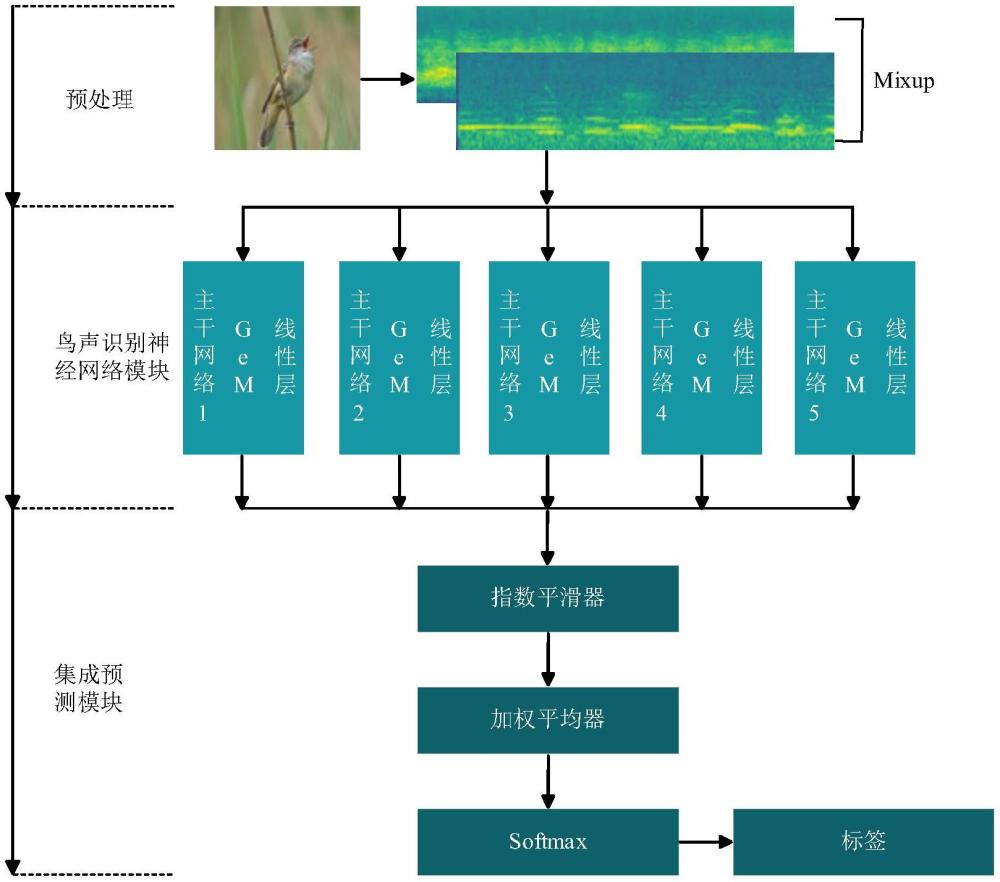
5、(3)使用多个改进后的预训练卷积神经网络模型分别进行训练;每个卷积神经网络模型具有不同的结构或参数设置,以捕捉鸟声的不同特征;
6、(4)使用指数平滑方法与加权平滑方法设计集成模块,将多个训练好的卷积神经网络模型进行集成;将各个模型的输出结果融合;
7、(5)对集成后的模型进行综合性能评估。
8、进一步的,步骤(1)中,预处理包括音频信号的去噪、归一化处理及分段操作;将预处理后的数据将切分成适当长度的音频片段。
9、进一步的,步骤(2)中,将处理后的鸟声信号变换,数据形式由向量转为复数矩阵,其中,复数矩阵表示在不同时间和频率上的信号强度;将复数矩阵通过一组梅尔滤波器进行卷积;提取梅尔滤波器输出的对数,将输出按照时间轴堆叠在一起,形成一个二维矩阵;其中,矩阵的横轴表示时间,纵轴表示梅尔滤波器的频率,每个元素代表对应时间和频率上的能量值;使用db转换对二维矩阵进行后处理,将频率值转换为分贝值。
10、进一步的,步骤(3)具体如下:使用5个改进后的预训练卷积神经网络模型分别进行训练,包括:tf_efficientnetv2_s_in21k模型、引入se模块的seresnext50_32x4d模型、引入了cspn结构的cspdarknet53模型、引入了eca模块的eca_nfnet_l0模型、利用残差连接结构的resnet34模型;其中,在对这5个预训练卷积神经网络模型进行训练前,对模型进行调整改进。
11、进一步的,对模型进行调整改进具体如下:首先,通过梅尔频谱转换和db转换,将原始鸟声音频转换为频谱图;引入了mixup操作以增加数据多样性;然后再预训练模型后添加可学习的gem池化层,捕捉提取鸟声音频特征;其中,gem的输出是通过对特征图每个通道上的元素进行幂平均计算得到的。
12、进一步的,引入了mixup操作以增加数据多样性具体如下:在鸟声音频内部应用mixup,将单个鸟声音频在数据预处理阶段分割成多个等长的子片段,然后对这些子片段进行线性插值;接着,随机选择两个不同的鸟声音频进行同样的mixup操作;其中,线性插值对象是来自两个不同鸟声音频的子片段。
13、进一步的,步骤(4)具体如下:预测模块接收来自五个鸟声识别神经网络模型的输出,并整合成一组数据,随后输入指数平滑器;然后加权平均器接收指数平滑器的输出作为输入,并根据五个模型在测试集上的表现进行权重赋值;最后通过对加权平均器的输出进行softmax转换,获得最终的识别结果。
14、本发明所述的一种基于多模型集成的鸟声识别系统,包括:
15、预处理模块:用于获取鸟声信号并对对数据进行预处理,包括音频信号的去噪、归一化处理及分段操作,以确保数据质量和一致性。预处理后的数据将被切分成适当长度的音频片段,确保数据的有效性。
16、提取模块:用于结合梅尔频率倒谱系数、短时傅里叶变换和分贝转换特征提取方法,从鸟声数据中提取出关键特征;
17、训练模块:用于使用多个改进后的预训练卷积神经网络模型分别进行训练,每个卷积神经网络模型具有不同的结构或参数设置,以捕捉鸟声的不同特征。
18、集成模块:用于使用指数平滑方法与加权平滑方法设计集成模块,将多个训练好的卷积神经网络模型进行集成;将各个模型的输出结果融合;
19、评估模块:用于对集成后的模型进行综合性能评估。
20、本发明所述的一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述计算机程序被加载至处理器时实现任一项所述的一种基于多模型集成的鸟声识别方法。
21、本发明所述的一种存储介质,所述存储介质存储有计算机程序,所述计算机程序被处理器执行时实现任一项所述的一种基于多模型集成的鸟声识别方法。
22、有益效果:与现有技术相比,本发明具有如下显著优点:通过采用基于多模型集成的策略,显著提高了鸟声识别的准确率。相比于现有技术中的单一模型或特征融合方法,本发明的多模型集成策略能够充分利用多个模型的优势,综合其识别结果,克服了单一模型在处理鸟声复杂性和多样性方面的局限性。经过验证,本发明所采用的多模型集成方法能够有效减少识别过程中的误差,提高识别的稳定性和可靠性,从而显著提升了鸟声识别的总体准确率。
技术特征:
1.一种基于多模型集成的鸟声识别方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于多模型集成的鸟声识别方法,其特征在于,步骤(1)中,预处理包括音频信号的去噪、归一化处理及分段操作;将预处理后的数据将切分成适当长度的音频片段。
3.根据权利要求1所述的一种基于多模型集成的鸟声识别方法,其特征在于,步骤(2)中,将处理后的鸟声信号变换,数据形式由向量转为复数矩阵,其中,复数矩阵表示在不同时间和频率上的信号强度;将复数矩阵通过一组梅尔滤波器进行卷积;提取梅尔滤波器输出的对数,将输出按照时间轴堆叠在一起,形成一个二维矩阵;其中,矩阵的横轴表示时间,纵轴表示梅尔滤波器的频率,每个元素代表对应时间和频率上的能量值;使用db转换对二维矩阵进行后处理,将频率值转换为分贝值。
4.根据权利要求1所述的一种基于多模型集成的鸟声识别方法,其特征在于,步骤(3)具体如下:使用5个改进后的预训练卷积神经网络模型分别进行训练,包括:tf_efficientnetv2_s_in21k模型、引入se模块的seresnext50_32x4d模型、引入了cspn结构的cspdarknet53模型、引入了eca模块的eca_nfnet_l0模型、利用残差连接结构的resnet34模型;其中,在对这5个预训练卷积神经网络模型进行训练前,对模型进行调整改进。
5.根据权利要求4所述的一种基于多模型集成的鸟声识别方法,其特征在于,对模型进行调整改进具体如下:首先,通过梅尔频谱转换和db转换,将原始鸟声音频转换为频谱图;引入了mixup操作以增加数据多样性;然后再预训练模型后添加可学习的gem池化层,捕捉提取鸟声音频特征;其中,gem的输出是通过对特征图每个通道上的元素进行幂平均计算得到的。
6.根据权利要求5所述的一种基于多模型集成的鸟声识别方法,其特征在于,引入了mixup操作以增加数据多样性具体如下:在鸟声音频内部应用mixup,将单个鸟声音频在数据预处理阶段分割成多个等长的子片段,然后对这些子片段进行线性插值;接着,随机选择两个不同的鸟声音频进行同样的mixup操作;其中,线性插值对象是来自两个不同鸟声音频的子片段。
7.根据权利要求1所述的一种基于多模型集成的鸟声识别方法,其特征在于,步骤(4)具体如下:预测模块接收来自五个鸟声识别神经网络模型的输出,并整合成一组数据,随后输入指数平滑器;然后加权平均器接收指数平滑器的输出作为输入,并根据五个模型在测试集上的表现进行权重赋值;最后通过对加权平均器的输出进行softmax转换,获得最终的识别结果。
8.一种基于多模型集成的鸟声识别系统,其特征在于,包括:
9.一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,其特征在于,所述计算机程序被加载至处理器时实现根据权利要求1-7任一项所述的一种基于多模型集成的鸟声识别方法。
10.一种存储介质,所述存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现根据权利要求1-7任一项所述的一种基于多模型集成的鸟声识别方法。
技术总结
本发明公开了一种基于多模型集成的鸟声识别方法,包括以下步骤:(1)获取鸟声信号并对对数据进行预处理;(2)结合梅尔频率倒谱系数、短时傅里叶变换和分贝转换特征提取方法,从鸟声数据中提取出关键特征;(3)使用多个改进后的预训练卷积神经网络模型分别进行训练;每个卷积神经网络模型具有不同的结构或参数设置,以捕捉鸟声的不同特征;(4)使用指数平滑方法与加权平滑方法设计集成模块,将多个训练好的卷积神经网络模型进行集成;将各个模型的输出结果融合;(5)对集成后的模型进行综合性能评估;本发明显著提升了鸟声识别的总体准确率。
技术研发人员:臧强,马刚,吴文宇,还红华,刘云平,龚毅光,范志勇
受保护的技术使用者:南京信息工程大学
技术研发日:
技术公布日:2025/3/3
- 还没有人留言评论。精彩留言会获得点赞!