一种基于大脑活动信息的自监督学习语音识别方法及系统与流程
本发明涉及语音识别领域,具体涉及一种基于大脑活动信息的自监督学习语音识别方法及系统。
背景技术:
1、随着能源互联网的快速发展,电网领域的工作形式发生着翻天覆地的变化,语音识别技术在电网领域中被广泛使用。目前电网领域采用的大多数语音识别模型是基于无监督学习的,这种方式降低了数据标记量,但往往需要大量训练数据,这在电网领域中往往难以达到。
2、近几年随着技术的发展,自监督学习的加入为语音处理领域带来了革命性的变化,其产生的模型可以通过对抗学习、聚类等方法从未标记的样本数据中提取有效、稳健的通用特征。但是目前大多数研究只局限于理论方面,实际应用较少,尤其是针对电网领域内的研究和应用就更加稀少,尚不能推广应用。
3、因此,亟需一种针对电网领域训练数据量不足情况下的语音识别方法。
技术实现思路
1、发明目的:本发明旨在提供一种基于大脑活动信息的自监督学习语音识别方法及系统,用以解决基于无监督学习的语音识别算法在训练数据量不足的情况下所导致的语音识别效果差的问题。
2、技术方案:本发明公开了一种基于大脑活动信息的自监督学习语音识别方法,包括以下步骤:
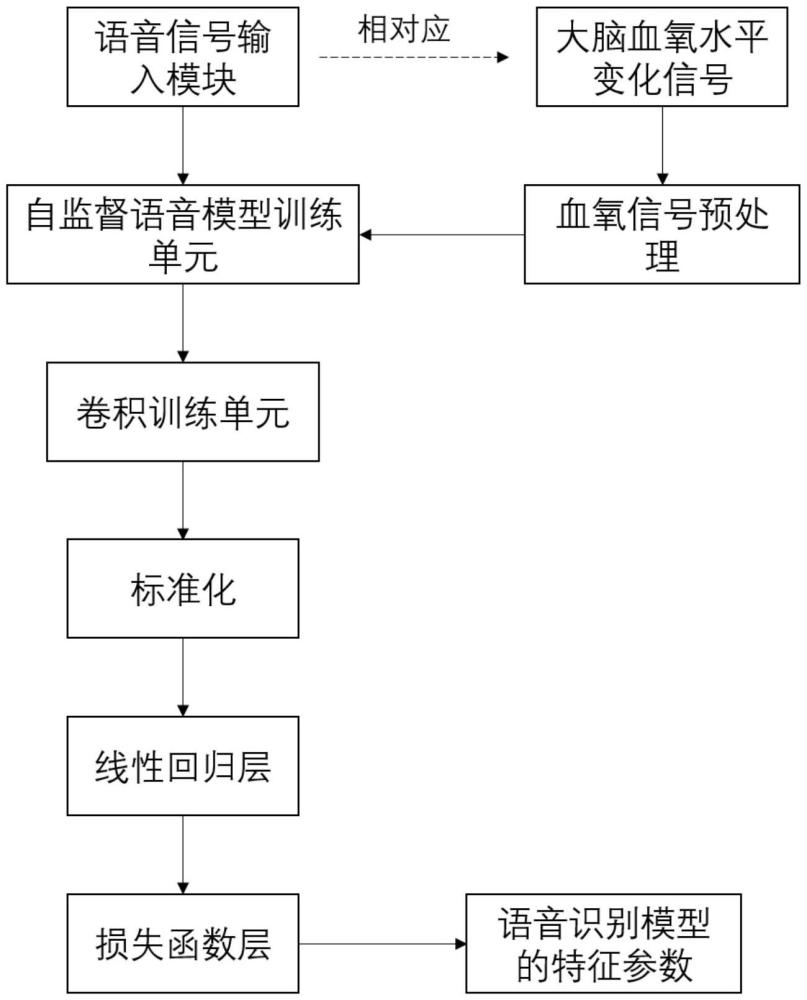
3、步骤1、收集语音信号,扫描与所述语音信号同时产生的大脑血氧水平变化信号,该大脑血氧水平变化信号即代表大脑活动信息;
4、步骤2、建立自监督语音识别模型训练单元,对收集到的语音信号和大脑活动信息进行初步的语音识别模型训练,得到输出结果y,所述自监督语音识别模型训练单元包括复合卷积层、transformer层和线性投影层;
5、步骤3、建立卷积训练单元与标准化层,由卷积训练单元对所述输出结果y进行卷积操作,再通过标准化层对卷积操作后的y进行标准化;
6、步骤4、建立线性回归层与损失函数层,通过线性回归层对语音信号与大脑血氧水平变化信号进行线性建模,构建自监督语音识别模型数据集z;通过损失函数层对自监督语音识别模型数据集z进行训练,得到训练完成的自监督语音识别模型的特征参数z*;
7、步骤5、输出训练完成的自监督语音识别模型的特征参数z*,得到训练完成的自监督语音识别模型,利用该模型对收集的待识别的语音信号进行识别。
8、进一步的,步骤1所述语音信号由麦克风阵列获取,所述大脑血氧水平变化信号由功能性磁共振成像扫描仪扫描得到,每一个语音信号对应一个与其同时产生的大脑血氧水平变化信号。
9、进一步的,步骤2将所述语音信号与代表大脑活动信息的血氧水平变化信号共同作为输入信号,输入至自监督语音模型训练单元,处理过程为,
10、首先通过多层的复合卷积层和transformer层获得输入信号的上下文表示c,
11、然后通过线性投影层投影到输出层y,用公式表示为:
12、y=lm,nc
13、其中,lmn表示一个m×n的矩阵,m和n分别为设定的训练单元的大小。
14、进一步的,步骤3卷积训练单元对所述输出结果y进行卷积操作后,再进行批归一化处理,设定批次大小t,将卷积操作后的y平均分为若干组小批量数据集x,对每一组小批量数据集x计算该数据集的均值μb和方差用公式表示为:
15、
16、
17、其中,xi是该组小批量数据集中第i个数据点的值,t是该组小批量数据集的大小。
18、进一步的,将所述若干组小批量数据集x进行规范化处理,公式表示为:
19、
20、其中,x(k)是小批量数据集x中的数据点;∈是一个很小的自然数,避免分母为零;x中各数据点x(k)经规范化处理得到的组合成规范化数据集
21、进一步的,步骤3中所述对y进行标准化操作采用的是z-score标准化,用公式表示为:
22、
23、其中s表示数据集的大小,xmean是数据集的均值,standard deviatio是数据集的标准差,yz是经过标准化处理后的y。
24、进一步的,步骤4中所述线性回归层上设有线性回归函数,通过该线性回归函数对语音信号与大脑血氧水平变化信号进行线性建模,构建自监督语音识别模型数据集z,所述线性回归函数表示为:
25、
26、其中,xz是自监督语音识别模型数据集z中的数据点。
27、进一步的,所述损失函数为smooth-l1正则化均方误差函数,用公式表示为:
28、
29、进一步的,在此损失函数的基础上,添加l2正则化项进行模型参数的训练,用公式表示为:
30、
31、其中,λ是预设置的超参数,经损失函数训练完成后得到自监督语音识别模型的特征参数z*。
32、本发明还公开了一种基于大脑活动信息的自监督学习语音识别系统,包括:
33、输入层,用以收集语音信号,扫描与所述语音信号同时产生的大脑血氧水平变化信号;
34、模型训练单元,用以对收集到的语音信号和大脑活动信息进行初步的语音识别模型训练;
35、卷积训练单元,用以对自监督语音模型训练单元的输出结果进行卷积操作;
36、标准化层,用以对卷积训练单元的输出结果进行标准化;
37、线性回归层,用以预测语音信号与大脑血氧水平变化信号间的响应关系;
38、损失函数层,用以训练自监督语音识别模型参数;
39、输出层,用以输出训练完成的自监督语音识别模型的特征参数;
40、自监督语音识别模型,用以实现语音信号的识别。
41、有益效果:本发明提供了一种基于大脑活动信息的自监督学习语音识别方法及系统,与现有技术相比,本发明通过建立神经编码模型,将与语音信号相对应的大脑活动信息融入语音识别模型的特征参数的训练过程中,在低信噪比的情况下比其他语音模型有更好的泛化能力。通过完善传统的语音识别模型的识别效果,本发明得以更好地适应电网领域的工作场景。
42、本发明解决了以往无监督学习的语音识别模型的识别效果差的问题,是一种针对电网领域训练数据量不足的情况下的语音识别方法。
技术特征:
1.一种基于大脑活动信息的自监督学习语音识别方法,其特征在于,具体包括以下步骤:
2.根据权利要求1所述的自监督学习语音识别方法,其特征在于,步骤1所述语音信号由麦克风阵列获取,所述大脑血氧水平变化信号由功能性磁共振成像扫描仪扫描得到,每一个语音信号对应一个与其同时产生的大脑血氧水平变化信号。
3.根据权利要求1所述的自监督学习语音识别方法,其特征在于,步骤2将所述语音信号与代表大脑活动信息的血氧水平变化信号共同作为输入信号,输入至自监督语音模型训练单元,处理过程为,
4.根据权利要求1所述的自监督学习语音识别方法,其特征在于,步骤3卷积训练单元对所述输出结果y进行卷积操作后,再进行批归一化处理,设定批次大小t,将卷积操作后的y平均分为若干组小批量数据集x,对每一组小批量数据集x计算该数据集的均值μb和方差用公式表示为:
5.根据权利要求4所述的自监督学习语音识别方法,其特征在于,将所述若干组小批量数据集x进行规范化处理,公式表示为:
6.根据权利要求5所述的自监督学习语音识别方法,其特征在于,步骤3中所述对y进行标准化操作采用的是z-score标准化,用公式表示为:
7.根据权利要求6所述的自监督学习语音识别方法,其特征在于,步骤4中所述线性回归层上设有线性回归函数,通过该线性回归函数对语音信号与大脑血氧水平变化信号进行线性建模,构建自监督语音识别模型数据集z,所述线性回归函数表示为:
8.根据权利要求7所述的自监督学习语音识别方法,其特征在于,所述损失函数为smooth-l1正则化均方误差函数,用公式表示为:
9.据权利要求8所述的自监督学习语音识别方法,其特征在于,在此损失函数的基础上,添加l2正则化项进行模型参数的训练,用公式表示为:
10.一种基于大脑活动信息的自监督学习语音识别系统,其特征在于,包括:
技术总结
本发明公开了一种基于大脑活动信息的自监督学习语音识别方法及系统,包括以下步骤:将语音信号数据和与之相对应的大脑活动信息,输入自监督语音模型训练单元进行模型训练;通过线性回归函数预测当前语音信号与大脑血氧水平变换信号间的响应关系,优化模型参数。本发明通过建立神经编码模型,利用与语音对应的大脑活动信息,提升自监督学习模型的训练效果,解决现有电网领域中,基于无监督学习的语音识别算法在训练数据量不足和低信噪比的情况下,语音识别效果差的问题。
技术研发人员:候聪颖,王召,程聪,冯宁钧,戴志伟
受保护的技术使用者:国电南瑞科技股份有限公司
技术研发日:
技术公布日:2025/2/20
- 还没有人留言评论。精彩留言会获得点赞!