基于声音克隆的数字人口唇训练方法、装置、设备及介质与流程
本发明属于人工智能,尤其涉及一种基于声音克隆的数字人口唇训练方法、装置、设备及介质。
背景技术:
1、目前,在对数字人进行口唇训练时,大多是把实际人物的视频当作训练素材,从实际人物的视频中提取音频与人脸信息,进而对数字人进行口唇训练。然而,随着人们对数字人定制化要求日益攀升,呈现出“千人千面”的需求日益膨胀,仅仅依靠现有的这些素材,已然无法满足实际需求了。此外,在进行数字人合成时,虽然可以借助声音生成口唇动作,可却只能依赖现实中数量有限的视频资料,难以挖掘出个体在不同情绪状态下的口唇形态,使得数字人口唇训练的准确率不高。
2、鉴于此,如何提高数字人口唇训练的准确率,是一个亟待解决的技术问题。
技术实现思路
1、本发明提供一种基于声音克隆的数字人口唇训练方法、装置、设备及介质,以解决现有的数字人口唇训练的准确率不高的技术问题。
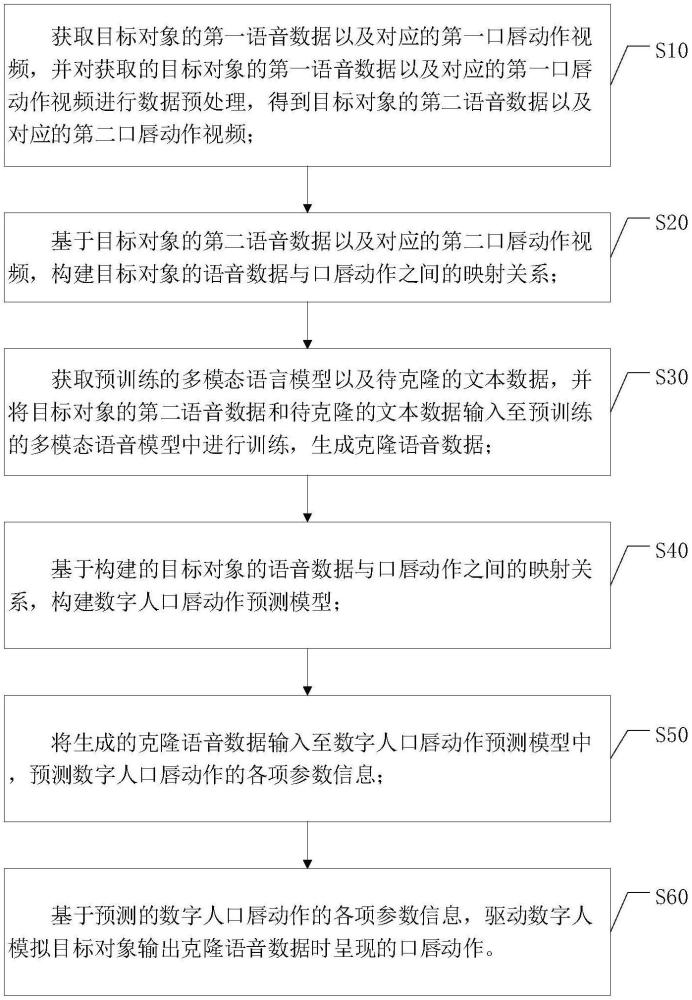
2、第一方面,本发明提供了一种基于声音克隆的数字人口唇训练方法,包括:
3、获取目标对象的第一语音数据以及对应的第一口唇动作视频,并对获取的目标对象的第一语音数据以及对应的第一口唇动作视频进行数据预处理,得到目标对象的第二语音数据以及对应的第二口唇动作视频;
4、基于目标对象的第二语音数据以及对应的第二口唇动作视频,构建目标对象的语音数据与口唇动作之间的映射关系;
5、获取预训练的多模态语音模型以及待克隆的文本数据,并将目标对象的第二语音数据和待克隆的文本数据输入至预训练的多模态语音模型中进行训练,生成克隆语音数据;
6、基于构建的目标对象的语音数据与口唇动作之间的映射关系,构建数字人口唇动作预测模型;
7、将生成的克隆语音数据输入至数字人口唇动作预测模型中,预测数字人口唇动作的各项参数信息;
8、基于预测的数字人口唇动作的各项参数信息,驱动数字人模拟目标对象输出克隆语音数据时呈现的口唇动作。
9、第二方面,本发明提供了一种基于声音克隆的数字人口唇训练装置,所述装置用于实现如上述第一方面所述的基于声音克隆的数字人口唇训练方法,包括:
10、处理模块,用于获取目标对象的第一语音数据以及对应的第一口唇动作视频,并对获取的目标对象的第一语音数据以及对应的第一口唇动作视频进行数据预处理,得到目标对象的第二语音数据以及对应的第二口唇动作视频;
11、第一构建模块,用于基于目标对象的第二语音数据以及对应的第二口唇动作视频,构建目标对象的语音数据与口唇动作之间的映射关系;
12、训练模块,用于获取预训练的多模态语音模型以及待克隆的文本数据,并将目标对象的第二语音数据和待克隆的文本数据输入至预训练的多模态语音模型中进行训练,生成克隆语音数据;
13、第二构建模块,用于基于构建的目标对象的语音数据与口唇动作之间的映射关系,构建数字人口唇动作预测模型;
14、预测模块,用于将生成的克隆语音数据输入至数字人口唇动作预测模型中,预测数字人口唇动作的各项参数信息;
15、驱动模块,用于基于预测的数字人口唇动作的各项参数信息,驱动数字人模拟目标对象输出克隆语音数据时呈现的口唇动作。
16、第三方面,本发明提供了一种计算机设备,包括存储器、处理器以及存储在存储器中并可在处理器上运行的计算机程序,处理器执行计算机程序时实现上述基于声音克隆的数字人口唇训练方法的步骤。
17、第四方面,本发明提供了一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被处理器执行时实现上述基于声音克隆的数字人口唇训练方法的步骤。
18、上述基于声音克隆的数字人口唇训练方法、装置、设备及介质所实现的方案中,可以通过客户端获取目标对象的第一语音数据以及对应的第一口唇动作视频,并对获取的目标对象的第一语音数据以及对应的第一口唇动作视频进行数据预处理,得到目标对象的第二语音数据以及对应的第二口唇动作视频;基于目标对象的第二语音数据以及对应的第二口唇动作视频,构建目标对象的语音数据与口唇动作之间的映射关系;获取预训练的多模态语音模型以及待克隆的文本数据,并将目标对象的第二语音数据和待克隆的文本数据输入至预训练的多模态语音模型中进行训练,生成克隆语音数据;基于构建的目标对象的语音数据与口唇动作之间的映射关系,构建数字人口唇动作预测模型;将生成的克隆语音数据输入至数字人口唇动作预测模型中,预测数字人口唇动作的各项参数信息;基于预测的数字人口唇动作的各项参数信息,驱动数字人模拟目标对象输出克隆语音数据时呈现的口唇动作,在本发明中,可以先将待克隆的文本数据输入至预训练的多模态语音模型中进行训练,生成克隆语音数据,再将生成的克隆语音数据输入至数字人口唇动作预测模型中,预测数字人口唇动作的各项参数信息,最后,根据预测的数字人口唇动作的各项参数信息,驱动数字人模拟目标对象输出克隆语音数据时呈现的口唇动作,有效地提高了数字人口唇训练的准确率。
技术特征:
1.一种基于声音克隆的数字人口唇训练方法,其特征在于,包括:
2.根据权利要求1所述的基于声音克隆的数字人口唇训练方法,其特征在于,所述对获取的目标对象的第一语音数据以及对应的第一口唇动作视频进行数据预处理,得到目标对象的第二语音数据以及对应的第二口唇动作视频,包括
3.根据权利要求1所述的基于声音克隆的数字人口唇训练方法,其特征在于,构建目标对象的语音数据与口唇动作之间的映射关系,包括:
4.根据权利要求3所述的基于声音克隆的数字人口唇训练方法,其特征在于,所述将目标对象的语音数据和待克隆的文本数据输入至预训练的多模态语音模型中进行训练,生成克隆语音数据,包括:
5.根据权利要求4所述的基于声音克隆的数字人口唇训练方法,其特征在于,所述将所述目标特征信息输入至预训练的多模态语音模型中进行训练,生成克隆语音数据,包括:
6.根据权利要求1所述的基于声音克隆的数字人口唇训练方法,其特征在于,将生成的克隆语音数据输入至数字人口唇动作预测模型中,预测数字人口唇动作的各项参数信息,包括:
7.根据权利要求4所述的基于声音克隆的数字人口唇训练方法,其特征在于,所述方法还包括:
8.一种基于声音克隆的数字人口唇训练装置,其特征在于,所述装置用于实现如权利要求1-7任一项所述的基于声音克隆的数字人口唇训练方法,包括:
9.一种计算机设备,包括存储器、处理器以及存储在所述存储器中并可在所述处理器上运行的计算机程序,其特征在于,所述处理器执行所述计算机程序时实现如权利要求1至7任一项所述的基于声音克隆的数字人口唇训练方法的步骤。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如权利要求1至7任一项所述的基于声音克隆的数字人口唇训练方法的步骤。
技术总结
本发明属于人工智能技术领域,公开了一种基于声音克隆的数字人口唇训练方法、装置、设备及介质,所述方法包括:获取预训练的多模态语音模型以及待克隆的文本数据,并将目标对象的第二语音数据和待克隆的文本数据输入至预训练的多模态语音模型中进行训练,生成克隆语音数据;基于构建的目标对象的语音数据与口唇动作之间的映射关系,构建数字人口唇动作预测模型;将生成的克隆语音数据输入至数字人口唇动作预测模型中,预测数字人口唇动作的各项参数信息;基于预测的数字人口唇动作的各项参数信息,驱动数字人模拟目标对象输出克隆语音数据时呈现的口唇动作。本发明有效的提高了数字人口唇训练的准确率。
技术研发人员:陈欣
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2025/3/3
- 还没有人留言评论。精彩留言会获得点赞!