一种基于支持向量机的音频分类方法
本发明涉及音频分类方法,尤其是一种基于支持向量机的音频分类方法。
背景技术:
1、目前,市面上的音频分析和歌唱评分软件大都采用频谱图分析方式,将音频转置而成的频谱图作为之后的分析对象。当程序接收到频谱图时,将该频谱图与原曲的频谱图进行比对,分析其差异性并得出结果,最终通过数据的可视化向用户展示。
2、而在现有技术中,是从视频网站上下载下来的男高音歌唱片段作为训练集,采用二值化(0或1)和三分化(0,1,2,分别代表有无和程度低)进行评分,之后输入到cnn卷积神经网络中进行处理,该技术方案对于美声评分的准确度为30%-40%之间,从而精确度较低。
技术实现思路
1、针对现有的技术问题,本发明提供一种基于支持向量机的音频分类方法。
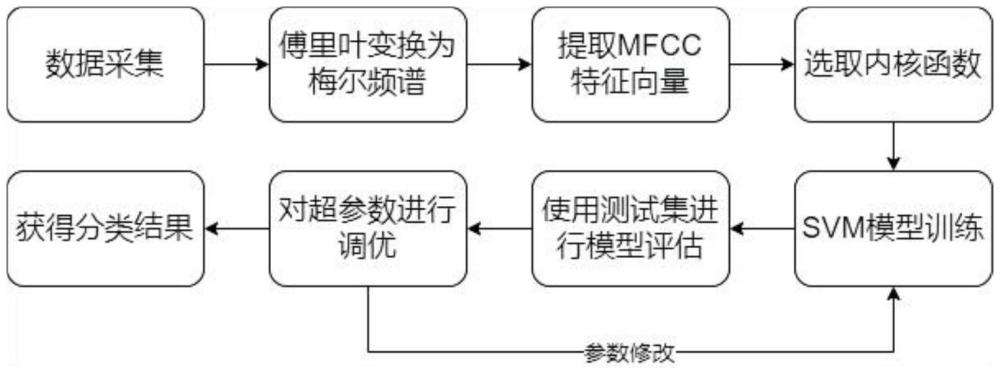
2、本发明所采用的技术方案是:一种基于支持向量机的音频分类方法,具体包括以下步骤:
3、步骤s01,将音频数据通过傅里叶变换后的频率信息映射到梅尔频率尺度,再将其转换成对数幅度谱,以获得接近人耳感知方式的频谱图;
4、步骤s02,将提取的mfcc特征向量x与对应的音频类别标签组成训练数据集;
5、步骤s03,将训练数据集输入svm算法,训练得到音频分类模型;
6、步骤s04,将新音频的mfcc特征向量输入模型,根据新数据点相对于学习的超平面的位置对新数据点进行分类预测,获得类别标签。
7、本发明进一步的设置为,将音频数据通过傅里叶变换后的频率信息映射到梅尔频率尺度,再将其转换成对数幅度谱,以获得接近人耳感知方式的频谱图,具体包括以下步骤:
8、步骤一,采用数字滤波器对音频信号进行降噪,消除背景噪声;
9、步骤二,对音频信号的幅度进行归一化处理,将信号幅度调整到统一范围;
10、步骤三,将预处理后的音频信号按固定长度分帧,每帧加上汉明窗,对每一帧的信号进行fft,转换到频域,得到频谱信息;
11、步骤四,将频谱映射到梅尔频率尺度,模拟人耳对不同频率的感知,对梅尔频率尺度上的功率谱取对数,得到对数能量谱,对对数能量谱进行离散余弦变换(dct),得到mfcc特征向量x。
12、本发明进一步的设置为,将训练数据集输入svm算法,训练得到音频分类模型,具体包括以下步骤:
13、步骤一,根据数据特性选择内核函数,将数据映射到更高维的空间,使其线性可分,使用径向基函数计算,具体如下:
14、k(x1,x2)=exp(-γ·||x1-x2||2)
15、式中:||x1-x2||2为可以被识别为两个特征向量之间的平方欧氏距离;
16、内核系数为:
17、
18、步骤二,训练过程中,svm会找到使边际,最大化的最佳超平面,得到模型文件。
19、本发明的有益效果是:本发明中,通过人工智能技术分析演唱者演唱音频的频谱图,不需要与原曲进行比较,适用范围更广,本发明中从十个技术指标的维度去评判演唱者的演唱水平,相较于之前的评分标准更为精确。
技术特征:
1.一种基于支持向量机的音频分类方法,其特征在于,具体包括以下步骤:
2.根据权利要求1所述的一种基于支持向量机的音频分类方法,其特征在于,将音频数据通过傅里叶变换后的频率信息映射到梅尔频率尺度,再将其转换成对数幅度谱,以获得接近人耳感知方式的频谱图,具体包括以下步骤:
3.根据权利要求2所述的一种基于支持向量机的音频分类方法,其特征在于,将训练数据集输入svm算法,训练得到音频分类模型,具体包括以下步骤:
技术总结
本发明涉及音频分类方法技术领域,具体公开了一种基于支持向量机的音频分类方法,具体包括以下步骤:步骤S01,将音频数据通过傅里叶变换后的频率信息映射到梅尔频率尺度,再将其转换成对数幅度谱,以获得接近人耳感知方式的频谱图;步骤S02,将提取的MFCC特征向量X与对应的音频类别标签组成训练数据集;步骤S03,将训练数据集输入SVM算法,训练得到音频分类模型;步骤S04,将新音频的MFCC特征向量输入模型,根据新数据点相对于学习的超平面的位置对新数据点进行分类预测,获得类别标签。通过人工智能技术分析演唱者演唱音频的频谱图,不需要与原曲进行比较,适用范围更广,相较于之前的评分标准更为精确。
技术研发人员:侯震一,范广宇,皮伟宁,罗代均,张天浩,陶致荣,姜尚格日乐,盛薪瑜,赵徐,叶柯杰,夏嘉璟,班晨希,张诣弢,张玉炎,陈佳星,张语桐
受保护的技术使用者:上海理工大学
技术研发日:
技术公布日:2025/4/10
- 还没有人留言评论。精彩留言会获得点赞!