基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法与流程
本发明涉及轧制工艺,具体为基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法。
背景技术:
1、金属材料在工业生产中广泛应用,而冷连轧技术是金属材料加工领域的重要环节之一。冷连轧是指在常温下通过多道次的轧制,将金属坯料压制成所需尺寸的工业生产过程。在冷连轧过程中,轧制力是一个重要的物理参数,它直接影响着轧制质量和工艺效率。准确预测轧制力对于优化工艺参数、提高生产效率、降低生产成本具有至关重要的意义。
2、传统的轧制力预测方法主要基于经验模型或者数学建模,如多元线性回归、支持向量机等。这些方法通常需要大量的数据样本作为训练集,然后通过拟合数据和模型参数来预测轧制力。然而,传统方法存在一些局限性:
3、1.数据需求量大:传统方法通常需要大量的中心化数据进行训练和拟合,这意味着需要收集和存储大量的轧制过程数据,增加了数据管理和处理的成本。
4、2.计算复杂度高:对于复杂的金属加工过程,传统方法往往需要复杂的数学模型和计算算法来处理,计算复杂度较高,导致预测效率低下。
5、3.数据隐私安全性差:传统方法通常需要集中式数据处理,将数据集中存储在一处进行模型训练和预测。这种方式存在数据隐私泄露的风险,一旦数据被非法获取或泄露,将会对企业的商业利益和竞争优势造成严重影响。
技术实现思路
1、本发明提出了基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,应用本方案可以实现对轧制力的准确预测,同时保障数据隐私。
2、为解决上述技术问题,本发明的技术方案如下:
3、一种基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,包括以下步骤:
4、步骤1:对冷连轧轧制数据集利用最大相关最小冗余技术对冷连轧轧制数据进行特征选择,以筛选出最具代表性与预测价值的特征集;
5、步骤2:通过堆叠leaky-relu rbm和改进自适应学习率的加权对比散度对筛选后的特征数据进行深度信念网络的无监督预训练,以提高模型的泛化能力和学习效率;
6、步骤3:在深度信念网络顶部集成偏最小二乘回归(plsr)层,构建特征与轧制力标签之间的高效映射关系,以便有效地捕捉特征与标签之间的复杂非线性关系;
7、步骤4:针对模型在预训练和微调过程中可能出现的过拟合问题,本发明在对比散度算法的误差计算和微调阶段的损失函数中引入了l2正则化。有效控制了模型的复杂度,提高了泛化能力;
8、步骤5:利用反向微调算法对深度信念网络进行微调,优化模型参数,最小化预测目标与实际输出之间的误差;
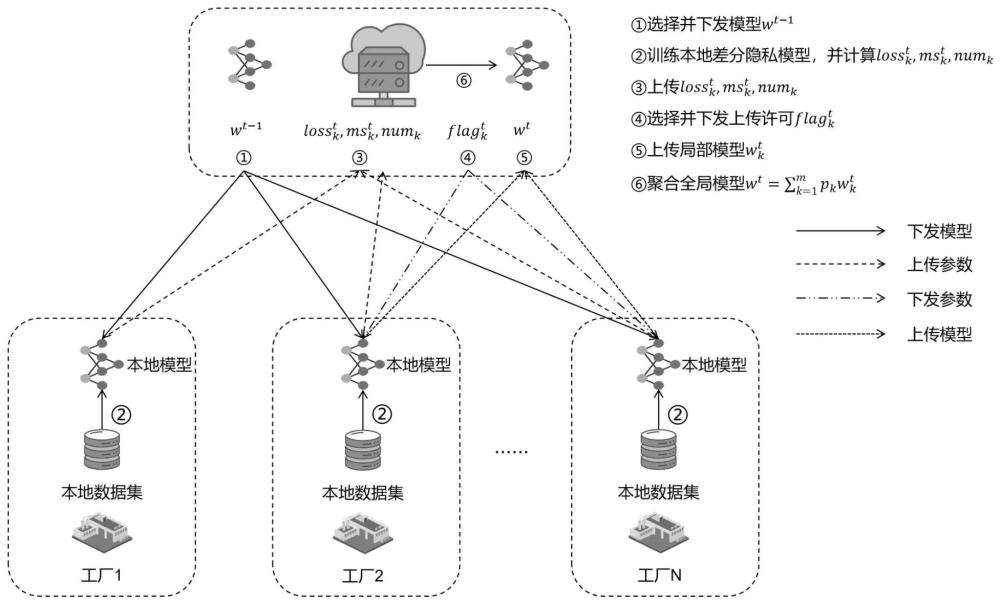
9、步骤6:在联邦学习环境中,将改进后的深度信念网络部署于各个冷轧工厂(作为客户端);
10、步骤7:为每个客户端引入动态梯度裁剪本地差分隐私,通过计算每个迭代中梯度的l2范数,并选取历史梯度l2范数的p百分位数作为当前迭代的裁剪阈值,并依据数据的敏感度和客户端的隐私需求调整隐私保护强度,确保数据在参与联邦学习过程中的隐私安全。
11、步骤8:设计一种客户端选择机制和联邦加权聚合机制,通过利用局部客户端上传的模型训练损失值以及与全局模型的余弦距离来选取前u%的局部客户端参与服务器聚合;
12、作为本方案的进一步优化,特征选择通过最大相关最小冗余技术选取与冷连轧轧制力预测相关的特征,并确保所选特征集合的最大相关性和最小冗余性。特征选择与降维处理采用的技术包括但不限于互信息分析和最大相关最小冗余(mrmr)算法,以确保选取的特征能够有效提高模型的预测精度。
13、作为本方案的进一步优化,深度信念网络的无监督预训练过程包括堆叠leaky-relu rbm和引入自适应学习率的加权对比散度,以提高模型的鲁棒性和泛化能力。堆叠的leaky-relu rbm通过调整隐藏层节点的数量、学习率以及其他超参数,实现对不同数据分布的自适应学习,增强模型对复杂数据特征的提取能力。
14、作为本方案的进一步优化,在深度信念网络顶部集成偏最小二乘回归(plsr)层,构建特征与轧制力标签之间的高效映射关系,以便有效地捕捉特征与标签之间的复杂非线性关系。plsr层的引入旨在优化特征与标签之间的映射,通过最小化特征集与标签集之间的均方误差,提高预测模型的准确性和泛化能力。
15、作为本方案的进一步优化,动态梯度裁剪本地差分隐私通过计算梯度的l2范数并选取历史梯度l2范数的p百分位数作为裁剪阈值来实现隐私保护功能,保护用户敏感信息的同时提高模型的鲁棒性和隐私保护水平。
16、作为本方案的进一步优化,联邦学习框架下的客户端选择机制和联邦聚合机制通过损失值和余弦距离相结合来选择参与服务器聚合的局部客户端,以提高模型的收敛速度和预测性能。客户端选择机制基于客户端模型损失和与全局模型的相似度(通过余弦距离度量),选择损失最小且与全局模型差异较小的前u%客户端。加权聚合算法考虑了客户端的数据量、模型质量以及训练进度,采用动态权重分配机制,确保全局模型更新能够公正地反映所有选中客户端的学习成果。
17、该方法首先通过最大相关最小冗余技术对轧制数据进行特征选择,然后利用堆叠leaky-relu rbm和改进自适应学习率的加权对比散度进行深度信念网络的无监督预训练。接着,在深度信念网络顶部设置plsr层,实现特征与标签的映射,并在对比散度算法的误差计算和微调阶段的损失函数中引入了l2正则化,最后,通过反向微调技术最小化特征集与标签集之间的损失。在联邦学习框架下,将改进后的深度信念网络部署为本地模型,并设计了一种客户端选择机制和联邦加权聚合机制,利用局部客户端上传的模型训练损失值以及与全局模型的余弦距离来选取前u%的局部客户端参与服务器聚合。同时,为每个客户端引入了动态梯度裁剪本地差分隐私,通过计算每个迭代中梯度的l2范数,并选取历史梯度l2范数的p百分位数作为当前迭代的裁剪阈值,实现隐私保护功能。
18、针对传统方法的局限性,近年来,随着深度学习和数据隐私保护技术的发展,人们开始尝试将深度学习模型应用于轧制力预测领域,并探索采用分布式计算和隐私保护技术来解决数据隐私问题。深度学习模型具有强大的表征能力和泛化能力,可以自动学习和提取数据的高级特征,从而更好地预测轧制力。而分布式计算和隐私保护技术则可以保证数据的安全性和隐私性,避免了数据泄露的风险。
19、因此,本发明将深度信念网络和联邦学习技术相结合,提出了一种新型的轧制力预测方法。该方法通过分布式计算和模型聚合,实现了对多个冷连轧工厂数据的高效利用,同时通过差分隐私技术保护了数据的隐私安全性。这一方法不仅提高了轧制力预测的准确性和效率,也有效解决了数据隐私泄露的问题,具有广阔的应用前景和市场价值。
技术特征:
1.基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,其特征在于,所述方法如下:
2.根据权利要求1所述的基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,其特征在于,在筛选特征集中,特征选择通过最大相关最小冗余技术选取与冷连轧轧制力预测相关的特征,并确保所选特征集合的最大相关性和最小冗余性。特征选择与降维处理采用的技术包括但不限于互信息分析和最大相关最小冗余算法,以确保选取的特征能够有效提高模型的预测精度。
3.根据权利要求1所述的基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,其特征在于,在所述训练特征数据中,深度信念网络的无监督预训练过程包括堆叠leaky-relu rbm和引入自适应学习率的加权对比散度,堆叠的leaky-relu rbm通过调整隐藏层节点的数量、学习率以及其他超参数,实现对不同数据分布的自适应学习,增强模型对复杂数据特征的提取能力。
4.根据权利要求1所述的基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,其特征在于,在构建映射关系中,在深度信念网络顶部集成偏最小二乘回归层,构建特征与轧制力标签之间的高效映射关系,以便有效地捕捉特征与标签之间的复杂非线性关系。plsr层的引入旨在优化特征与标签之间的映射,通过最小化特征集与标签集之间的均方误差,提高预测模型的准确性和泛化能力。
5.根据权利要求1所述的基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,其特征在于,在模型优化中,动态梯度裁剪本地差分隐私通过计算梯度的l2范数并选取历史梯度l2范数的p百分位数作为裁剪阈值来实现隐私保护功能,保护用户敏感信息的同时提高模型的鲁棒性和隐私保护水平。
6.根据权利要求1所述的基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,其特征在于,在网络部署中,联邦学习框架下的客户端选择机制和联邦聚合机制通过损失值和余弦距离相结合来选择参与服务器聚合的局部客户端,以提高模型的收敛速度和预测性能。客户端选择机制基于客户端模型损失和与全局模型的相似度,选择损失最小且与全局模型差异较小的前u%客户端。加权聚合算法考虑了客户端的数据量、模型质量以及训练进度,采用动态权重分配机制。
7.根据权利要求1所述的基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,其特征在于,
技术总结
本发明公布了一种基于深度信念网络与联邦学习的隐私保护冷连轧轧制力预测方法,首先,通过最大相关最小冗余技术对轧制数据进行特征选择。然后,构建改进后的深度信念网络轧制力预测模型,利用Leaky‑ReLU RBM和自适应学习率加权对比散度算法进行无监督预训练,在深度信念网络顶部设置PLSR层,反向微调最小化特征集与标签集之间的损失。最后,在联邦学习框架下,设计了一种客户端选择机制和联邦加权聚合机制,利用局部客户端上传的模型训练损失值以及与全局模型的余弦距离选取前u%的局部客户端参与服务器聚合,通过计算局部客户端在每个迭代中的历史梯度L2范数的p百分位数作为当前迭代的裁剪阈值,实现局部客户端的动态梯度裁剪本地化差分隐私功能。
技术研发人员:杨新法,李晓阳,朴春慧,侯艳波,王晨
受保护的技术使用者:石家庄洋旺机电技术有限公司
技术研发日:
技术公布日:2024/7/18
- 还没有人留言评论。精彩留言会获得点赞!