本发明涉及dna数据存储领域,更具体地涉及一种用于大规模dna数据库随机读取的方法。
背景技术:
1、dna数据存储,是一种利用dna来存储数据的新兴技术,通过将二进制的信息数据与dna链上的碱基序列互相转化来得以实现。具体来说,dna信息存储首先通过编码将二进制信息转换为碱基序列,随后合成相应dna片段,再将大量dna片段进行物理封装形成一个dna数据库。需要读取信息时,通过随机读取从一个或多个dna数据库中找到包含特定文件信息的目标dna片段,再经过测序和解码将其恢复为二进制信息。dna数据存储具有存储密度高、存储时间长、耗能少、无需人工频繁维护、无需消耗日益减少的矿石和稀土资源等优点。
2、dna数据存储系统要走向应用,其存储容量和和存储密度必须进一步扩大。因此,需要在同一个dna数据库中存储尽可能多的文件,这也就意味着,单位体积dna数据库中的dna片段将会更多,也会越发混乱无序,dna数据库的读取将变得更为困难。
3、目前最先进的dna数据库随机访问方法是使用许多周期的pcr扩增所需文件相应的dna片段。具体实施方法为,在pcr的过程中选用与包含目标文件信息的dna片段对应的引物,在合成过程中存储同一文件不同部分的dna片段将会包含相同的dna引物片段。因此,经过多轮pcr之后,包含目标文件信息的dna片段数量将会大大超过其他dna片段。此时即可通过dna测序,结合概率统计学原理进行分析,得到包含目标文件的dna片段的碱基序列,进而通过数据解码恢复出目标文件。
4、然而,该技术仅适用于目前小容量的dna数据存储系统,对于日后的大规模dna数据存储系统,该技术存在以下问题限制了其应用范围:1)根据理论预测,上述dna数据库随机访问方法随着数据库规模的增加,测序效率会不断下降,最终失效,因为随着数据库规模的增加,即使经过多轮pcr,包含目标文件信息的dna片段数量也无法远超大量的非目标dna片段;2)pcr循环次数过多,还会导致非特异性产物数量的增加,向dna数据库中引入噪声数据,包含目标文件信息的dna片段不能够被轻易筛选出来进行测序的程度,无法顺利恢复目标文件。因此,面对日后的高容量dna数据存储系统,当前的dna数据库随机访问方法存在严重问题。
技术实现思路
1、本发明的目的是提供一种用于大规模dna数据库随机读取的方法,从而解决现有dna数据库随机访问技术存在的不适用大规模dna数据库、会引入噪声数据、无法准确读取、读取效率较低的问题。
2、为了解决上述技术问题,本发明采用以下技术方案:
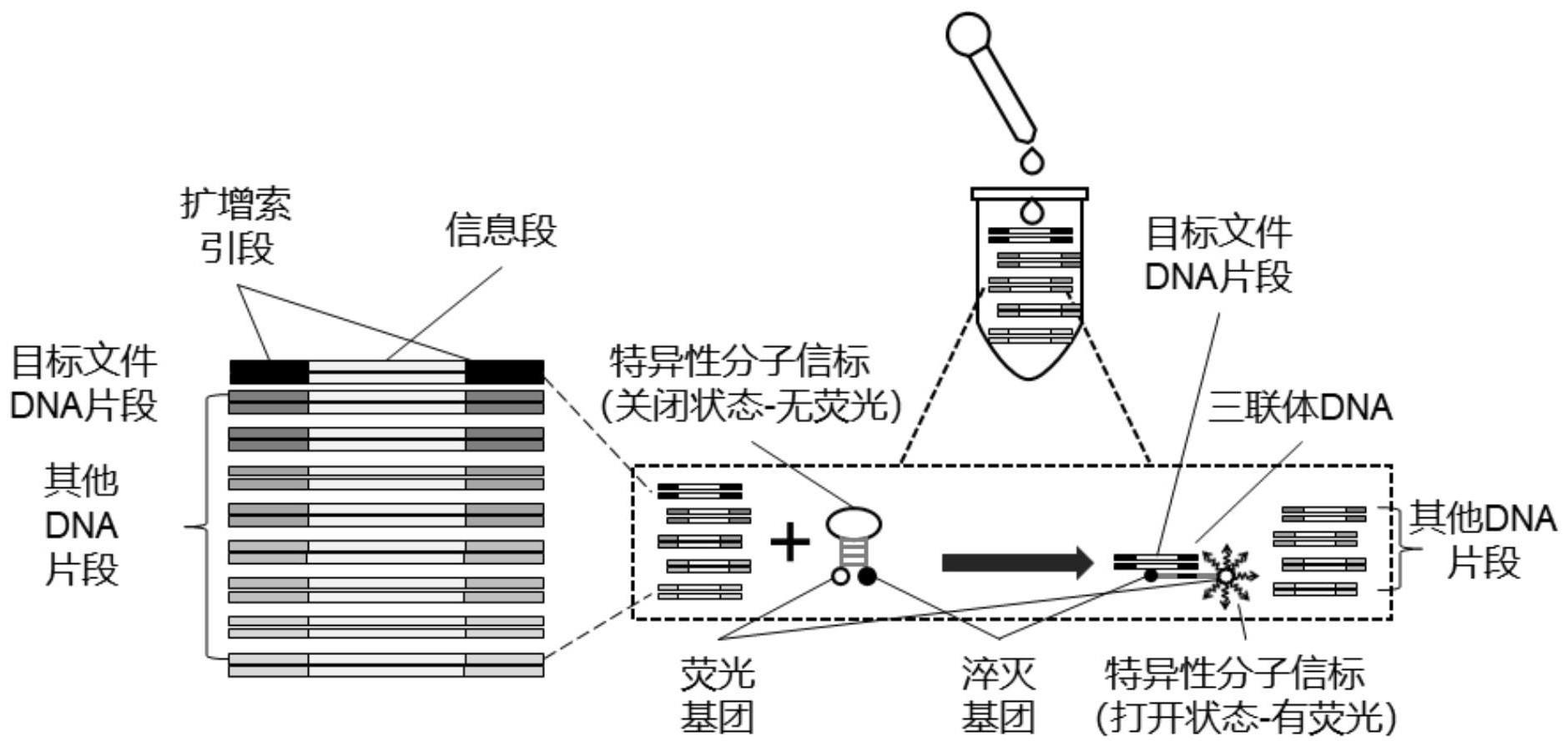
3、提供一种用于大规模dna数据库随机读取的方法,包括以下步骤:s1:提供包含若干dna双链的dna数据库,所述dna双链包括位于中间的存储信息序列以及位于两端的索引扩增序列;s2:提供一种特异性分子信标溶液,所述特异性分子信标包括位于中间的与所述dna双链上的索引扩增序列互补配对的寻址序列,以及分别位于两端的荧光基团和淬灭基团,此时荧光基团和淬灭基团彼此靠近不发出荧光;s3:将所述特异性分子信标溶液加入所述dna数据库中,所述特异性分子信标的寻址序列与所述目标dna的索引扩增序列发生匹配,形成包含目标dna的三联体dna,此时荧光基团和淬灭基团彼此远离发出荧光;s4:将步骤s3获得的混合溶液与分散相溶剂同时注入包含“t形管道”的液滴微流控芯片中,包含dna片段的连续相溶液在接口处受到所述分散相溶剂的对称剪切力形成微液滴,在荧光探头和电极的作用下,使含有目标dna的微液滴与不含目标dna的微液滴在“y字形”分叉口处分离,最终实现大规模dna数据库中目标dna的随机读取。
4、根据本发明的一个优选方案,当所述特异性分子信标上的荧光基团为6-fam、cy3、或6-hex时,淬灭基团为bhq-1。
5、根据本发明的另一优选方案,当所述特异性分子信标上的荧光基团为rox-610、quasar 670、或cy5时,淬灭基团为bhq-2。
6、根据本发明的一个优选方案,当所述dna双链采用水相溶剂溶解时,所述分散相溶剂为油相液体,可选自氟化油hfe7500或fc40。
7、根据本发明的一个优选方案,当所述dna数据库以dna单链的形式储存信息时,可预先将dna单链通过pcr程序形成dna双链,然后再进行目标dna的随机读取。
8、优选地,将dna单链加入含有与数据库匹配的扩增引物的标准pcr溶液中,该标准pcr溶液主要包含引物、tap dna聚合酶、dntp、盐离子、缓冲液等,将温度升温至45-60℃,持续30-60s,以促进引物与模板的结合,然后,将温度升至72℃,持续20-60s,该温度为dna聚合酶活性的最佳温度,在这个温度下杂交的引物被延伸,单链dna将变为双链dna。然后再采用本发明方法进行目标dna的随机读取即可。
9、优选地,步骤s4中,微液滴的大小以及生成速率,可以通过改变微管结构和两相流速比以及粘度比来进行调控。
10、优选地,步骤s4中,通过改变所述分散相溶剂的流速,可实现对微液滴间距的调控。
11、应当理解的是,由于特异性分子信标是一条寡核苷酸链(dna单链),目标dna是双链dna,包含两条寡核苷酸链,特异性分子信标与目标dna发生匹配,结合之后就变成了三联体或者说三链dna,因为其包含了三条寡核苷酸链。
12、与现有的多重pcr实现dna数据库的随机读取方法相比,本发明具有以下有益效果:
13、1)读取规模高:本发明方法通过特异性分子信标与目标dna片段形成三联体,从而发出荧光,实现特定dna片段的筛选与提取,无需使用pcr技术,突破了pcr技术使用次数上限,可在更大规模的dna数据库中实现应用;
14、2)准确性好:由于无需使用多重pcr,因此筛选过程中不会向dna数据库中引入噪声,增加了信息读取的准确性;
15、3)简单便捷:操作简单,大幅度减少人力物力与时间消耗。
16、综上所述,根据本发明提供的一种用于大规模dna数据库随机读取的方法,通过特异性分子信标与目标dna片段形成三联体,使目标dna片段发出荧光从而标记目标dna,再结合荧光液滴分选富集实现筛选,从而实现dna数据库随机访问的目标。本发明方法无需多重pcr,可应用于更大规模的dna数据存储系统,同时,筛选过程中不会向dna数据库中引入噪声,增加了信息读取的准确性,且操作简单,大幅度减少人力物力与时间消耗,在dna数据存储方面具有重要的应用价值和意义。
技术特征:1.一种用于大规模dna数据库随机读取的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的方法,其特征在于,当所述特异性分子信标上的荧光基团为6-fam、cy3、或6-hex时,淬灭基团为bhq-1。
3.根据权利要求1所述的方法,其特征在于,当所述特异性分子信标上的荧光基团为rox-610、quasar 670、或cy5时,淬灭基团为bhq-2。
4.根据权利要求1所述的方法,其特征在于,当所述dna双链采用水相溶剂溶解时,所述分散相溶剂为油相液体,可选自氟化油hfe7500或fc40。
5.根据权利要求1所述的方法,其特征在于,当所述dna数据库以dna单链的形式储存信息时,可预先将dna单链通过pcr程序形成dna双链,然后再进行目标dna的随机读取。
6.根据权利要求1所述的方法,其特征在于,步骤s4中,微液滴的大小以及生成速率,可以通过改变微管结构和两相流速比以及粘度比来进行调控。
7.根据权利要求1所述的方法,其特征在于,步骤s4中,通过改变所述分散相溶剂的流速,可实现对微液滴间距的调控。
技术总结本发明提供一种用于大规模DNA数据库随机读取的方法,包括步骤:S1:提供包含若干DNA双链的DNA数据库;S2:提供一种特异性分子信标溶液,特异性分子信标包括寻址序列,以及位于两端的荧光基团和淬灭基团;S3:将特异性分子信标溶液加入DNA数据库中,寻址序列与索引扩增序列发生匹配,形成包含目标DNA的三联体DNA;S4:将混合溶液与分散相溶剂同时注入芯片中,在荧光探头和电极的作用下,含有目标DNA的微液滴与不含目标DNA的微液滴分离,实现目标DNA的随机读取。本发明方法通过特异性分子信标与目标DNA片段形成三联体后发出荧光,无需多重PCR,即可从大规模的DNA数据库中实现特定信息的筛选与提取。
技术研发人员:王丽华,杨世佳,冯世伦,孙锐,赵建龙
受保护的技术使用者:祥符实验室
技术研发日:技术公布日:2024/1/14