用于视野遮挡的自动驾驶行为决策方法
本发明属于自动驾驶行为决策方法,具体涉及用于视野遮挡的自动驾驶行为决策方法。
背景技术:
1、自动驾驶视野遮挡场景的研究方法主要从车联网和车路协同等角度出发,车联网和车路协同的方法虽然可以通过网络的通信间接让自动驾驶汽车全面感知周围环境,但是在决策研究中,首先就是要解决信息传输的实时性和安全性等问题,除此之外,车路协同依靠路基传感器所获取环境信息与周围车辆进行通信,但是该方法存在大量基础设施建设与维护以及海量视野遮挡场景存在的随机性等问题。
2、另一方面,在自动驾驶行为决策研究中,基于规则映射的方法是最经典且易部署的,但是由于规则是研究者预先设定,所以在以往的应用中常常出现过于保守的驾驶策略,反而极大降低通行效率。其次,知识推理和基于价值的决策模型也广泛应用于自动驾驶领域中,但是这两种方法都存在“黑盒”问题,且前者必须预先建立强大的知识库。
技术实现思路
1、本发明的目的是提供用于视野遮挡的自动驾驶行为决策方法,能够提高自动驾驶车辆在面对视野遮挡的潜在危险场景决策的可靠度和效率。
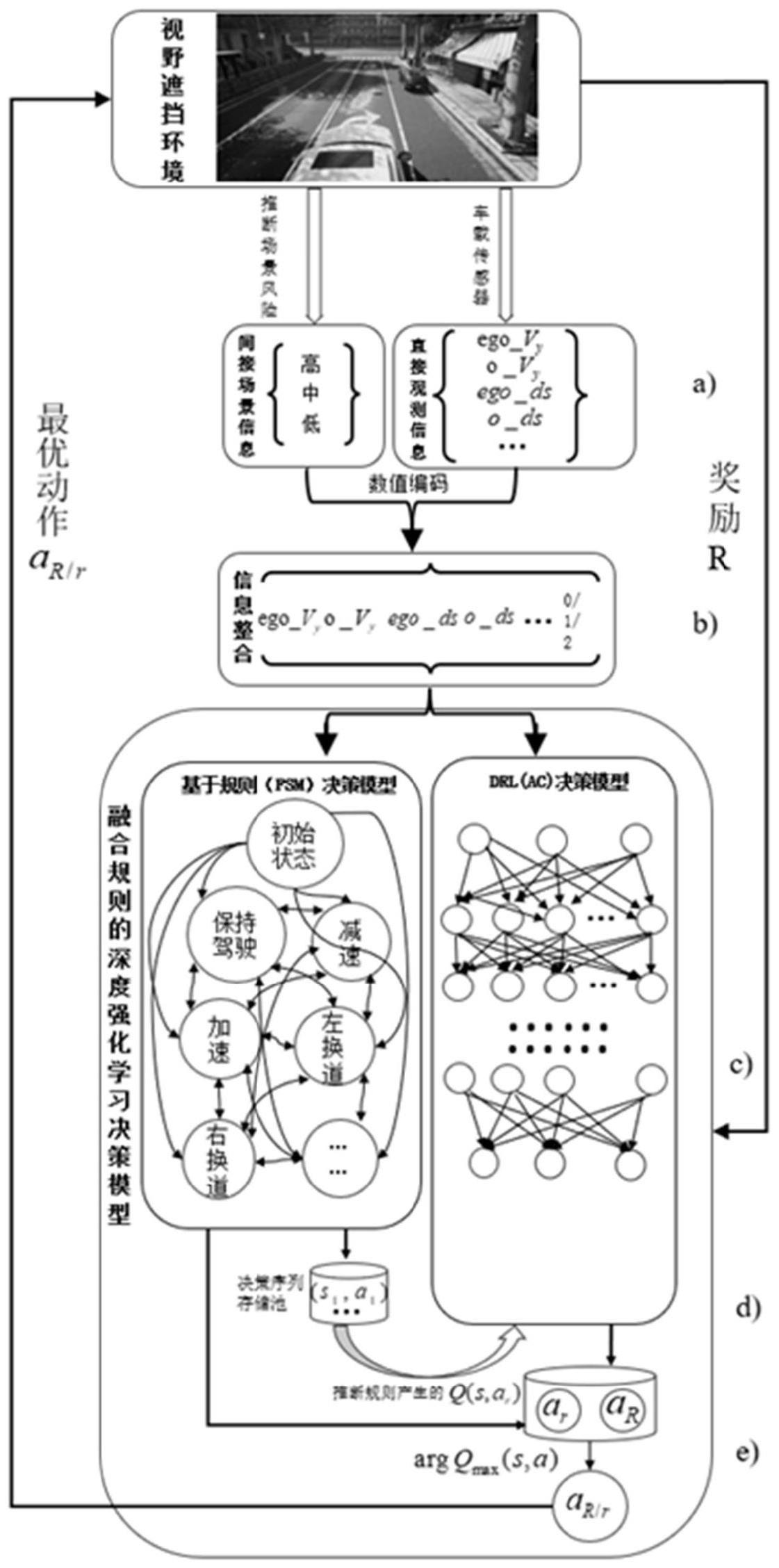
2、本发明采用的技术方案是,用于视野遮挡的自动驾驶行为决策方法,具体按照以下步骤:
3、步骤1、获取场景信息;
4、步骤2、获取时间、位置信息及场景元素信息推断得到视野遮挡场景的潜在风险;
5、步骤3、将所述步骤1与步骤2获取的数据融合;
6、步骤4、产生基于规则映射的决策方案;
7、步骤5、产生基于深度强化学习模型的决策方案与驾驶行为;
8、步骤6、最优驾驶决策的选择。
9、本发明的技术特征还在于,
10、步骤1具体为:通过车载传感器和计算实时获取自车与自车被遮挡视野的障碍物的距离,速度和加速度信息。
11、步骤3中将步骤1中直接观测值和数值编码后的虚拟观测值进行整合。
12、步骤4具体为:通过建立的有限状态机决策模型,将驾驶的决策分为多种状态,建立状态触发条件和状态转移函数,根据步骤3的融合信息,快速触发映射为驾驶状态,并由状态转移函数产生驾驶动作。
13、步骤5具体为:通过预先训练好的sac模型进以及步骤3的信息产生驾驶策略,并输出具体的驾驶动作行为。
14、步骤6具体为:通过已经推断的动作价值函数q(s,a)选择qr(s,ar)和qr(s,ar)中值最优的动作,其中s表示某时刻环境状态,a表示此刻环境状态对应智能体所做的动作;ar表示深度强化学习决策模型做出的动作;ar表示基于fsm决策模型做出的动作。
15、本发明的有益效果是,
16、1)本发明从单车智能的角度出发,解决了自动驾驶汽车对城市交通视野遮挡潜在危险交通场景行为决策问题,相较于车联网和车路协同解决方案依赖网络稳定性和路基设备的问题具有更好的泛化性和实用性;
17、2)本发明在基于价值的深度强化学习决策模型的基础上结合fsm构建一种基于深度强化学习与规则融合的面向自动驾驶视野遮挡潜在危险交通场景的决策方法,该方法相较于单独决策模型既解决了决策单一且策略保守问题,又提升深度强化学习决策的可靠性;
18、3)本发明通过挖掘视野遮挡场景中的非直接观测信息,将其与直接观测信息进行数值编码的方式作为决策方法的输入,相较于单独以直接观测值作为输入的深度强化学习决策模型具有更好的收敛性和决策的准确性。
技术特征:
1.用于视野遮挡的自动驾驶行为决策方法,其特征在于,具体按照以下步骤实施:
2.根据权利要求1所述的用于视野遮挡的自动驾驶行为决策方法,其特征在于,所述步骤1具体为:通过车载传感器和计算实时获取自车与自车被遮挡视野的障碍物的距离,速度和加速度信息。
3.根据权利要求1所述的用于视野遮挡的自动驾驶行为决策方法,其特征在于,所述步骤3中将步骤1中直接观测值和数值编码后的虚拟观测值进行整合。
4.根据权利要求1所述的用于视野遮挡的自动驾驶行为决策方法,其特征在于,所述步骤4具体为:通过建立的有限状态机决策模型,将驾驶的决策分为多种状态,建立状态触发条件和状态转移函数,根据步骤3的融合信息,快速触发映射为驾驶状态,并由状态转移函数产生驾驶动作。
5.根据权利要求1所述的用于视野遮挡的自动驾驶行为决策方法,其特征在于,所述步骤5具体为:通过预先训练好的sac模型进以及步骤3的信息产生驾驶策略,并输出具体的驾驶动作行为。
6.根据权利要求1所述的用于视野遮挡的自动驾驶行为决策方法,其特征在于,所述步骤6具体为:通过已经推断的动作价值函数q(s,a)选择qr(s,ar)和qr(s,ar)中值最优的动作,其中,s表示某时刻环境状态,a表示此刻环境状态对应智能体所做的动作;ar表示深度强化学习决策模型做出的动作;ar表示基于fsm决策模型做出的动作。
技术总结
本发明公开了用于视野遮挡的自动驾驶行为决策方法,具体按照以下步骤:步骤1、获取场景信息;步骤2、获取时间、位置信息及场景元素信息推断得到视野遮挡场景的潜在风险;步骤3、将所述步骤1与步骤2获取的数据融合;步骤4、产生基于规则映射的决策方案;步骤5、产生基于深度强化学习模型的决策方案与驾驶行为;步骤6、最优驾驶决策的选择。本发明通过挖掘视野遮挡场景中的非直接观测信息,将其与直接观测信息进行数值编码的方式作为决策方法的输入,相较于单独以直接观测值作为输入的深度强化学习决策模型具有更好的收敛性和决策的准确性。
技术研发人员:周劲草,张国伟,傅卫平,李睿,杨世强
受保护的技术使用者:西安理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!