一种基于约束策略优化的纵向柔性安全驾驶规约方法
本发明涉及自动驾驶,具体是基于约束策略优化的纵向柔性安全驾驶规约方法。
背景技术:
1、随着高级自动驾驶辅助系统的日益普及,自动驾驶汽车的安全性问题已经成为研究界最为关注的核心议题之一。人们对自动驾驶技术具备较高的安全期望,但自动驾驶致命事故屡有发生,这导致了人们对自动驾驶技术的信任危机。其中,纵向安全事故的后果最为频繁及严重。现有的保护自动驾驶汽车纵向安全技术以自适应巡航控制最为著名,但是也存在着高速驾驶场景中的不够安全和不稳定性的误报警等问题,其中难以预测的过于紧急的制动问题最为致命,这难以取得用户的信任也潜在的违反了驾驶者的使用习惯,使得其无法提供可靠的自动驾驶汽车纵向安全性保护。
2、面对自动驾驶安全性问题,最近由mobileye提出了责任敏感安全模型(responsibility sensitive safety, rss),旨在将人类对安全驾驶的理念和事故责任的判定转化为数学模型,并作为决策控制的关键参数,提供柔性规约的约束。rss模型基于五个基本的安全常识,明确规定了自动驾驶汽车在横向和纵向的安全距离,以及在各种驾驶情境中的适当响应。该模型不仅区分了各类驾驶环境,例如道路的拓扑结构、交通信号、以及障碍物的遮挡情况,还细致考虑了其他交通参与者的潜在不当行为、行使优先权的情况及责任的具体划分。rss模型广泛应用于乘用车、商用车、共享出行车辆以及自动驾驶测试车辆。
3、通过这些细化的参数和定义,rss模型力求实现一种理想状态,即自动驾驶汽车绝不因自身原因主动引发碰撞或事故,rss模型的效果依赖于公式中预设置的参数,如果参数过高估计,则计算出的安全距离过大,极端情况下车辆由于始终无法满足安全距离,从而判断为危险态势,触发紧急响应。因此,根据真实驾驶数据集计算最优参数是应用rss的必要前提,以确保自动驾驶系统既安全又高效地运行。
4、现有的rss参数优化方法通常选择参数范围的中位值或采用启发式搜索,但这些方法难以实现参数选择到优化结果的最佳映射。尽管这些方法在优化rss模型参数方面取得了一定的成效,但在应用于自动驾驶时仍表现出过分保守或安全不足,参数难以兼顾行车安全性与高效性。
5、其次,当前rss参数优化设置方法主要依托仿真环境,尽管这种方法在一定程度上提供了参考依据,但现实驾驶场景复杂多变,这种方法难以完全反映真实的驾驶环境,导致其在实际应用中受到限制。
技术实现思路
1、本发明的目的在于提供基于约束策略优化的纵向柔性安全驾驶规约方法,以解决上述背景技术中提出的问题。
2、为实现上述目的,本发明提供如下技术方案:一种基于约束策略优化的纵向柔性安全驾驶规约方法,所述方法包括:
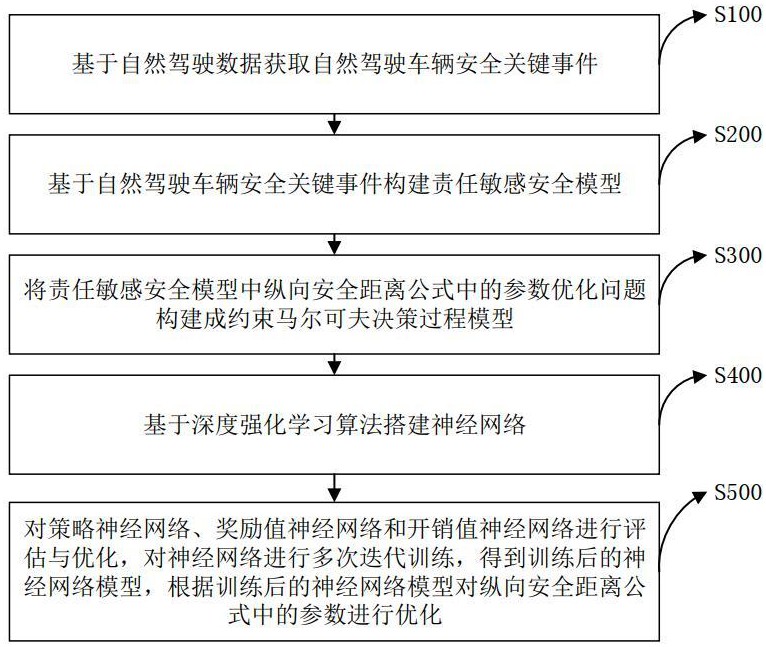
3、基于自然驾驶数据获取自然驾驶车辆安全关键事件;
4、基于自然驾驶车辆安全关键事件构建责任敏感安全模型;
5、将责任敏感安全模型中纵向安全距离公式中的参数优化问题构建成约束马尔可夫决策过程模型,将约束马尔可夫决策过程模型中的状态空间定义为前后两车的相对距离和相对速度的统计均值和标准差;行为空间定义为安全距离公式中待优化的参数,包括后车响应时间、前车最大减速度、后车最大加速度和后车最小减速度;
6、基于深度强化学习算法搭建神经网络,所述神经网络包括策略神经网络、奖励值神经网络和开销值神经网络;
7、对策略神经网络、奖励值神经网络和开销值神经网络进行评估与优化,对神经网络进行多次迭代训练,得到训练后的神经网络模型,根据训练后的神经网络模型对纵向安全距离公式中的参数进行优化。
8、作为本发明更进一步的方案,所述基于自然驾驶数据获取自然驾驶车辆安全关键事件步骤具体包括:
9、获取自然驾驶数据,所述自然驾驶数据包括运动学数据以及视频数据;
10、确定危险场景触发条件;
11、基于自然驾驶数据以及危险场景触发条件提取初始安全关键场景事件;
12、对初始安全关键场景事件进行筛选,生成最终的安全关键场景事件;
13、基于最终的安全关键场景事件提取运动学特征。
14、作为本发明更进一步的方案,所述将责任敏感安全模型中纵向安全距离公式中的参数优化问题构建成约束马尔可夫决策问题模型的步骤具体包括:
15、基于最小化碰撞时间积分的目标构建开销函数;
16、基于最小化保守性安全距离之和的目标构建奖励函数。
17、作为本发明更进一步的方案,所述开销函数设计为:
18、;
19、;
20、其中,表示每个安全关键事件中的低于某一阈值的持续时间,n是在每次策略更新过程中,每个回合内触发ttc低于阈值的事件次数;表示第个安全关键时期的值;为阈值;表示第个时期在时间的模拟步骤中的值;是两个模拟步骤之间的时间间隔。
21、作为本发明更进一步的方案,所述奖励函数设计为:
22、;
23、;
24、其中,代表第个时期的保守性测量;表示第个时期中大于的第个时刻;和分别表示最小合理距离和实际距离。
25、作为本发明更进一步的方案,所述对策略神经网络、奖励值神经网络和开销值神经网络进行评估与优化的步骤具体包括:
26、基于奖励函数以及开销函数确定期望回报与约束条件;
27、基于近似求解方法对策略神经网络进行更新;
28、对奖励值神经网络和开销值神经网络进行更新。
29、作为本发明更进一步的方案,所述基于奖励函数以及开销函数确定期望回报与约束条件的步骤包括:
30、对策略相对于开销函数的预期折扣回报进行定义;
31、确定策略相对于奖励函数的预期折扣回报进行确定;
32、确定满足约束条件的策略。
33、作为本发明更进一步的方案,策略相对于开销函数的预期折扣回报定义为:
34、;
35、表示策略相对于开销函数的预期折扣回报,为折扣因子。
36、
37、作为本发明更进一步的方案,策略相对于奖励函数的预期折扣回报表示为:
38、。
39、作为本发明更进一步的方案,满足所有开销约束的策略集:;
40、在策略约束集中能够最大化的策略:
41、。
42、与现有技术相比,本发明的有益效果是:通过在真实自然驾驶数据中设计危险场景触发条件,提取自然驾驶车辆的安全关键事件并统计事件特征,解决了当前责任敏感安全模型参数偏离实际场景设计导致难以实际使用的问题。采用深度强化学习方法优化参数,利用神经网络映射危险态势与参数设置之间的非线性复杂关系,解决了参数欠优化问题。在符合自然驾驶的安全关键场景中,该方法既能保持车辆纵向行驶安全,又能最大程度避免过于保守的估计导致的触发规约,实现了安全性与高效性的兼顾。
技术特征:
1.一种基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,所述方法包括:
2.根据权利要求1所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,所述基于自然驾驶数据获取自然驾驶车辆安全关键事件步骤具体包括:
3.根据权利要求1所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,所述将责任敏感安全模型中纵向安全距离公式中的参数优化问题构建成约束马尔可夫决策问题模型的步骤具体包括:
4.根据权利要求3所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,所述开销函数设计为:
5.根据权利要求3所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,所述奖励函数设计为:
6.根据权利要求1所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,所述对策略神经网络、奖励值神经网络和开销值神经网络进行评估与优化的步骤具体包括:
7.根据权利要求6所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,所述基于奖励函数以及开销函数确定期望回报与约束条件的步骤包括:
8.根据权利要求7所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,策略相对于开销函数的预期折扣回报定义为:
9.根据权利要求8所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,策略相对于奖励函数的预期折扣回报表示为:
10.根据权利要求9所述的基于约束策略优化的纵向柔性安全驾驶规约方法,其特征在于,满足所有开销约束的策略集:;
技术总结
本发明涉及自动驾驶技术领域,具体公开了一种基于约束策略优化的纵向柔性安全驾驶规约方法,包括基于自然驾驶数据获取自然驾驶车辆安全关键事件;将责任敏感安全模型中纵向安全距离公式中的参数优化问题构建成约束马尔可夫决策过程模型,基于深度强化学习算法搭建神经网络,对策略神经网络、奖励值神经网络和开销值神经网络进行评估与优化,通过在真实自然驾驶数据中设计危险场景触发条件,提取自然驾驶车辆的安全关键事件,解决了当前责任敏感安全模型参数偏离实际场景设计导致难以实际使用的问题,在符合自然驾驶的安全关键场景中,既能保持车辆纵向行驶安全,又能最大程度避免过于保守的估计导致的触发规约,实现了安全性与高效性的兼顾。
技术研发人员:郑程元,高镇海,赵睿,樊宇泽,郝予之
受保护的技术使用者:吉林大学
技术研发日:
技术公布日:2024/11/18
- 还没有人留言评论。精彩留言会获得点赞!