基于近地高光谱数据和集成模型的油菜氮磷钾养分诊断方法与流程
本发明涉及作物养分亏缺快速检测和人工智能应用领域,具体涉及一种基于近地高光谱数据和集成模型的油菜氮磷钾养分诊断方法。
背景技术:
油菜是我国第一大油料作物,菜籽油占国产油料作物产油量的57.2%,在我国食用油供给中占有重要地位。近半个世纪以来,我国油菜生产迅速发展,大量研究表明氮肥、磷肥、钾肥的合理施用对油菜的增产效果十分显著。实时、精准地监测作物养分状况,特别是宏观尺度下的氮、磷、钾等主要养分的状况,对辅助政府职能部门决策、指导农户生产、提高作物的产量和品质具有重要意义。
基于高光谱的农作物养分诊断方法,能够在不破坏作物的基础上,通过提取农作物在养分丰缺下的光谱响应实现大范围农田全面、快速的营养诊断。然而,不同养分丰缺下的农作物光谱特征响应有很多相似之处,比如氮和钾素严重缺乏都会导致叶绿素含量降低进而导致红波段反射率提升、氮和磷素的缺乏都会使叶面积增长缓慢进而导致近红外波段反射率下降等。
因此,目前光谱养分诊断研究主要针对一种营养元素进行缺或不缺的识别,尚未提出增强不同养分状况下的农作物光谱响应区分度,以实现不同养分胁迫的区分、提高养分诊断精度的方法。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供了一种基于近地高光谱数据和集成模型的油菜氮磷钾养分诊断方法;该方法基于近地高光谱数据,挖掘对油菜不同养分亏缺状况敏感的冠层特征光谱波段,并通过集成多个模型的方式将选择的冠层特征光谱波段进行变换,增强其在不同养分亏缺下的特征区分度,实现对油菜氮、磷、钾养分状况进行无损诊断的方法。
为实现上述目的,本发明所设计一种基于近地高光谱数据和集成模型的油菜氮磷钾养分诊断方法,包括以下步骤:
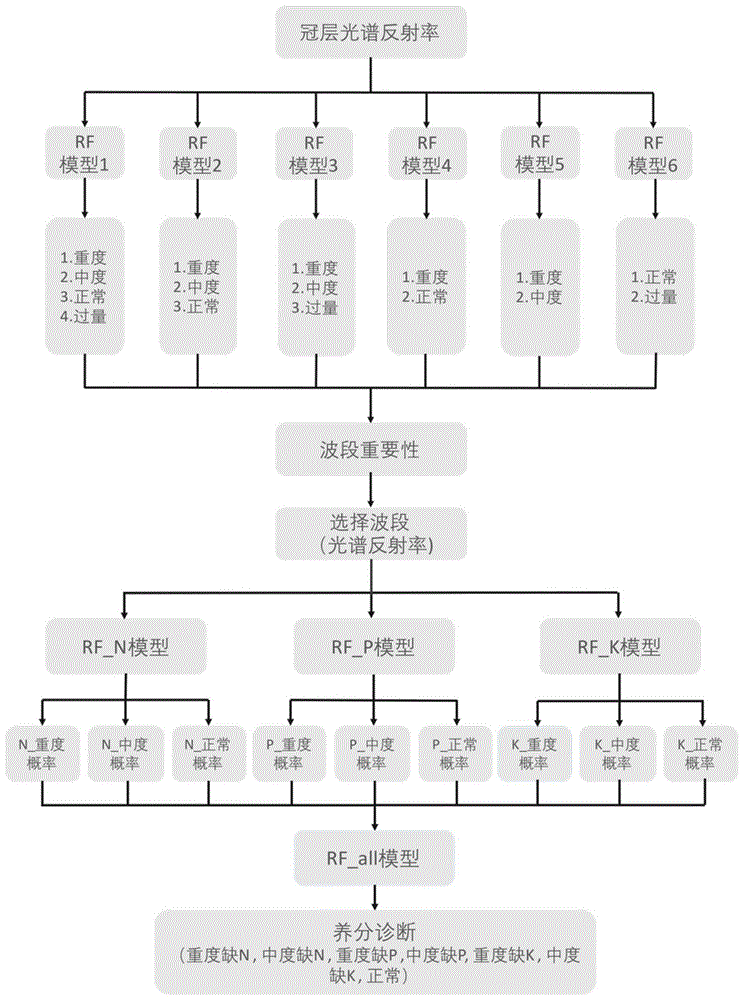
1)建立不同油菜养分状况下的冠层高光谱反射率数据子集
a.采集待测区域油菜冠层近地高光谱数据并形成集合,将采集到的冠层高光谱反射率数据集与待测区域油菜养分状况进行映射,
b.再将冠层高光谱反射率数据分为氮、磷、钾三组施肥养分元素;
c.根据当地土壤理化参数,每组养分元素的施肥处理按施肥梯度分为重度缺乏处理、中度缺乏处理、正常处理和过量施肥处理的四个养分状况;
d.将每组内的冠层高光谱反射率数据与养分状况进行匹配,每个养分状况下的冠层高光谱反射率数据子集作为一个数据亚组;
2)优化冠层高光谱反射率数据
a.将冠层高光谱反射率数据以间隔性重采样,删除噪声波段;
b.计算每个数据亚组的所有冠层光谱中各个波段的反射率均值和标准差,并逐一检查每条光谱,剔除含有异常波段的光谱;
3)每个养分元素均构建六个随机森林分类模型,利用构建的模型进行六次养分丰缺状况的分类
a.将每个养分元素中的多个数据亚组进行组合(将上述每个养分元素数据中的多个数据亚组分别抽取其中的四个亚组、三个亚组、两个亚组进行组合),生成每个养分元素的六个不同数据集,六个数据集分别为:
(1)数据集1为重度缺乏处理亚组、中度缺乏处理亚组、过量处理亚组、正常处理亚组的组合,
(2)数据集2为重度缺乏处理亚组、中度缺乏处理亚组、正常处理亚组的组合,
(3)数据集3为重度缺乏处理亚组、过量处理亚组、正常处理亚组的组合,
(4)数据集4为重度缺乏处理亚组、正常处理亚组的组合,
(5)数据集5为中度处理亚组、正常处理亚组的组合,
(6)数据集6为过量处理亚组、正常处理亚组的组合;
b.分别利用每个养分元素的六个不同数据集构建六个随机森林分类模型,分类类别与所利用的数据集中的养分状况相同,在建立每个随机森林分类模型时对两个参数ntree和mtry进行调整以达到最佳的分类总体精度;
4)计算每个波段对该养分元素丰缺诊断的重要性分值
针对每个养分元素,利用每个构建的随机森林分类模型进行养分丰缺状况的分类后得到冠层高光谱数据中的每个波段的重要性(variableimportance,vi)和分类总精度,计算每次分类结果中冠层高光谱所有波段的重要性的均值(μ)和方差(σ),并对每个波段的重要性进行归一化,得到归一化后的波段重要性(vi’):
式中,vi′为归一化后的波段重要性,vi为冠层高光谱数据中的每个波段的重要性,
每次分类结果中冠层高光谱所有波段的重要性的均值(μ)和方差(σ);
5)筛选对每个养分元素的丰缺敏感的特征波段
针对每个养分元素中六个数据集进行六次养分丰缺状况的分类后得到的每个特征波段的归一化重要性进行加权求和,权重为对应的每次分类总精度(wi),求得每个特征波段的贡献度总分(score):
式中,score为每个特征波段的贡献度总分,wi为对应的每次分类总精度,vi′为归一化后的波段重要性;
针对每个养分元素选取10个贡献度总分最高的光谱波段作为对该养分元素亏缺敏感的诊断特征波段,其余予以剔除;
6)利用筛选的特征波段重新建立每个养分元素的丰缺状况分类模型
分别利用筛选出的每个养分元素丰缺敏感的10个重要特征波段,重新建立用于养分诊断的随机森林分类模型,并且每次建立随机森林分类模型均需对ntree和mtry参数校正,校正依据以分类总精度最佳为宜;
7)利用三个养分元素丰缺状况分类模型生成新的概率特征因子
a.针对氮、磷、钾每个养分元素,从每条冠层高光谱数据中选取步骤5)筛选出的对每个养分元素亏缺敏感的波段并利用步骤6)建立的每个养分元素的丰缺状况分类模型对其进行分类判别,得到每条光谱数据被分到各个类别的概率值,
b.然后将所有的概率值组成了新的特征,将作为最终区分氮、磷、钾养分丰缺状况的特征因子;
8)利用新生成的概率特征因子构建随机森林分类模型,获得氮、磷、钾养分亏缺状况的诊断结果;
利用新生成的概率特征因子构建新的随机森林分类模型(建立随机森林分类模型需对ntree和mtry参数校正,校正依据以分类总精度最佳为宜),确定新生成的概率特征因子属于重度缺氮、轻度缺氮、重度缺磷、轻度缺磷、重度缺钾、轻度缺钾、正常施肥的哪一个类别,即完成了氮、磷、钾养分亏缺状况的诊断。
进一步地,所述步骤1)的第c小步中,每组养分元素中四个处理亚组如下:
①氮组处理过程中,磷肥施用量为90千克/公顷、钾肥施用量为120千克/公顷,均为正常施用量,同时做病虫害管理防治工作;其中,
重度缺氮处理的氮肥用量为0千克/公顷,
中度缺氮处理的氮肥用量为75-90千克/公顷,
正常处理的氮肥用量为150-180千克/公顷,
过度施氮处理的氮肥用量为225-270千克/公顷;
②磷组处理过程中,氮肥施用量为180千克/公顷、钾肥施用量为120千克/公顷,均为正常施用量,同时做病虫害管理防治工作;其中
重度缺磷处理的磷肥用量为0千克/公顷,
中度缺磷处理的磷肥用量为30-45千克/公顷,
正常处理的磷肥用量为90千克/公顷,
过量施磷处理为磷肥用量135-180千克/公顷;
③钾组处理过程中,氮肥施用量为180千克/公顷、磷肥施用量为90千克/公顷,均为正常施用量,同时做病虫害管理防治工作;其中,
重度缺钾处理的钾肥用量为0千克/公顷,
中度缺钾处理的钾肥用量为60-75千克/公顷,
正常处理的钾肥用量为120千克/公顷,
过量施钾处理的钾肥用量为135-180千克/公顷。
再进一步地,所述步骤2)的第b小步中,剔除含有异常波段的光谱的具体步骤:
当某条光谱的某个波段反射率大于均值+/-两倍标准差的值时,则将该条光谱的这个波段标记为异常波段;
若该条光谱数据异常波段的个数大于等于20个时,则将该条光谱数据从数据亚组中剔除。
再进一步地,所述步骤3)第b小步中,ntree的取值范围为100-1000,步长为100,mtry的取值范围为3-10,步长为1。
再进一步地,所述步骤6)中,建立用于养分诊断的随机森林分类模型具体步骤如下:
i利用筛选的10个对氮养分丰缺敏感的重要特征波段,建立能够区分重度缺氮、轻度缺氮、正常施肥的随机森林分类模型;
ii利用筛选的10个对磷养分丰缺敏感的重要特征波段,建立能够区分重度缺磷、轻度缺磷、正常施肥的随机森林分类模型;
iii利用筛选的10个对钾养分丰缺敏感的重要特征波段,建立能够区分重度缺钾、轻度缺钾、正常施肥的随机森林分类模型。
再进一步地,所述步骤7)第a小步,每条光谱数据被分到各个类别的概率值有九个,获得方法如下:
i选用对氮养分亏缺敏感的10个重要特征波段的光谱数据,输入针对氮养分训练得到的随机森林分类模型,获得每条光谱数据被分为重度缺氮、轻度缺氮、正常施肥的概率值;
ii选用对磷养分亏缺敏感的10个重要特征波段的光谱数据,输入针对磷养分训练得到的随机森林分类模型,获得每条光谱被分为重度缺磷、轻度缺磷、正常施肥的概率值;
iii选用对钾养分亏缺敏感的10个重要特征波段的光谱数据,输入针对钾养分训练得到的随机森林分类模型,获得每条光谱数据被分为重度缺钾、轻度缺钾、正常施肥的概率值。
本发明的有益效果:
(1)基于近地高光谱数据,设计了特征波段筛选方法,降低了高光谱数据的信息维度,简化了处理过程,提高了处理速度。
(2)通过构建集成模型将原始特征光谱转换为新的概率特征,新的概率特征明显增强了不同养分状态下的油菜光谱特征的区分度,有效的提高了估测模型的精度,为油菜氮、磷、钾养分的遥感诊断提供了较为实用可靠的科学方法。
附图说明
图1是一种基于近地高光谱数据和集成模型的油菜氮磷钾养分诊断方法的流程图;
图2是一种基于近地高光谱数据和集成模型的油菜氮磷钾养分诊断方法得到的新的概率特征(b)与原始的光谱反射率特征(a)的对比图;
具体实施方式
下面结合具体实施例对本发明作进一步的详细描述,以便本领域技术人员理解。
利用psr+3500便携式地物光谱仪(spectralevolution,haverhill,ma,usa)采集冬油菜越冬期试验小区养分处理数据集和近地高光谱数据集,光谱范围为400nm至2500nm,光谱分辨率为1nm。应在晴朗、无风的天气,于上午11:00至下午1:00间采集光谱数据。采集数据时将光纤探头置于油菜冠层上方1米处。每个试验小区采集3-5条光谱。本发明于2013年至2019年期间,在湖北省武汉市、武穴市、沙洋市共开展13个冬油菜养分丰缺大田试验,供试品种为华油杂9号和华油杂62号,每个实验的养分梯度设置均有不同,目的在于广泛地获取不同养分丰缺状况的高光谱数据集,共采集910条油菜冠层光谱数据,其中30%的数据作为独立测试数据集,用于检验和比较本发明的集成方法和常用方法的诊断精度;
利用如图1所示的方法流程利用近地高光谱数据构建集成模型对上述油菜进行氮磷钾养分亏缺诊断方法
步骤1:建立不同油菜养分状况下的冠层高光谱反射率数据子集
步骤1.1:将采集到的油菜冠层高光谱反射率数据与待测区域油菜养分状况进行映射;
步骤1.2:再讲冠层高光谱反射率数据分为氮、磷、钾三组施肥养分元素;
步骤1.3:根据当地土壤理化参数,每组养分元素的施肥处理按施肥梯度分为重度缺乏处理、中度缺乏处理、正常处理和过量施肥处理的四个养分状况;重度缺氮处理为氮肥用量0千克/公顷、中度缺氮处理为氮肥用量75-90千克/公顷、过量施氮处理为氮肥用量225-270千克/公顷、重度缺磷处理为磷肥用量0千克/公顷、中度缺磷处理为磷肥用量30-45千克/公顷、过量施磷处理为磷肥用量135-180千克/公顷、重度缺钾处理为钾肥用量0千克/公顷、中度缺钾处理为钾肥用量60-75千克/公顷、过量施钾处理为钾肥用量135-180千克/公顷、正常施肥处理为氮肥用量150-180千克/公顷、磷肥用量90千克/公顷、钾肥用量120千克/公顷;
步骤1.4:将每组内的冠层高光谱反射率数据与养分状况进行匹配,每个养分状况下的冠层高光谱反射率数据子集作为一个数据亚组,共七个亚组,分别为重度缺氮亚组、中度缺氮亚组、重度缺磷亚组、中度缺磷亚组、重度缺钾亚组、中度缺钾亚组和正常施肥亚组;
步骤2:优化冠层高光谱反射率数据
步骤2.1:将1nm分辨率光谱数据平均为10nm分辨率光谱数据,删除噪声波段(小于400nm,1800-2000nm,大于2300nm的波段);
步骤2.2:计算每个亚组数据的所有冠层光谱中各个波段光谱均值和标准差,并逐一检查每条光谱,如果某条光谱的某个波段反射率大于均值+/-两倍标准差的值,则将该条光谱的这个波段标记为异常波段,若某条光谱数据异常波段大于等于20个,则将该条光谱数据剔除;
步骤3:将每个营养元素中的多个亚组数据进行组合,生成六个不同的数据集,分别利用六个不同的数据集训练养分诊断模型,根据模型得出的输入波段特征重要性计算每个波段特征的分值,针对每个营养元素选取分值最高的十个重要特征波段作为对该营养元素丰缺敏感的特征波段,建模方法选择了随机森林分类算法,随机森林分类模型利用python3.5实现,主要利用了sklearn0.19.2机器学习框架;
步骤3.1:将每个养分元素中的多个数据亚组进行组合(将上述每个养分元素数据中的多个数据亚组分别抽取其中的四个亚组、三个亚组、两个亚组进行组合),生成每个养分元素的六个不同数据集,六个数据集分别为:
(1)数据集1为重度缺乏处理亚组、中度缺乏处理亚组、过量处理亚组、正常处理亚组的组合,
(2)数据集2为重度缺乏处理亚组、中度缺乏处理亚组、正常处理亚组的组合,
(3)数据集3为重度缺乏处理亚组、过量处理亚组、正常处理亚组的组合,
(4)数据集4为重度缺乏处理亚组、正常处理亚组的组合,
(5)数据集5为中度处理亚组、正常处理亚组的组合,
(6)数据集6为过量处理亚组、正常处理亚组的组合;
步骤3.2:分别利用每个养分元素的六个不同数据集构建六个随机森林分类模型,分类类别与所利用的数据集中的养分状况相同,在建立每个随机森林分类模型时对两个参数ntree和mtry进行调整,其中ntree的取值范围为100-1000,步长为100,mtry的取值范围为3-10,步长为1,校正依据为以训练集分类总精度最佳为宜;
步骤4:计算每个波段对该养分元素丰缺诊断的重要性分值
针对每个养分元素,利用每个构建的随机森林分类模型进行养分丰缺状况的分类后得到冠层高光谱数据中的每个波段的重要性(variableimportance,vi)和分类总精度,计算每次分类结果中冠层高光谱所有波段的重要性的均值(μ)和方差(σ),并对每个波段的重要性进行归一化,得到归一化后的波段重要性(vi’):
式中,vi'为归一化后的波段重要性,vi为冠层高光谱数据中的每个波段的重要性,
每次分类结果中冠层高光谱所有波段的重要性的均值(μ)和方差(σ);
步骤5:筛选对每个养分元素的丰缺敏感的特征波段
针对每个养分元素中六个数据集进行六次养分丰缺状况的分类后得到的每个特征波段的归一化重要性进行加权求和,权重为对应的每次分类总精度(wi),求得每个特征波段的贡献度总分(score):
式中,score为每个特征波段的贡献度总分,wi为对应的每次分类总精度,为归一化后的波段重要性;
针对每个营养元素选取10个贡献度总分最高的光谱波段作为该养分元素亏缺敏感的诊断特征波段,其余予以剔除;筛选出的10个对氮养分丰缺敏感的特征波段是:640,2070,650,2000,680,690,630,660,670,2020nm;筛选出的10个对磷养分丰缺敏感的特征波段是:1120,910,2000,2040,810,1090,760,690,680,1420nm;筛选出的10个对钾养分丰缺敏感的特征波段是:2100,2260,2030,2040,530,2290,680,2070,650,2080;
步骤6:利用筛选的特征波段重新建立每个养分元素的丰缺状况分类模型
分别利用筛选出的每个养分元素丰缺敏感的10个重要特征波段,重新建立用于养分诊断的随机森林分类模型,具体步骤如下:
i利用筛选的10个对氮养分丰缺敏感的重要特征波段,建立能够区分重度缺氮、轻度缺氮、正常施肥的随机森林分类模型;
ii利用筛选的10个对磷养分丰缺敏感的重要特征波段,建立能够区分重度缺磷、轻度缺磷、正常施肥的随机森林分类模型;
iii利用筛选的10个对钾养分丰缺敏感的重要特征波段,建立能够区分重度缺钾、轻度缺钾、正常施肥的随机森林分类模型。
并且每次建立随机森林分类模型均需对ntree和mtry参数校正,其中ntree的取值范围为100-1000,步长为100,mtry的取值范围为3-10,步长为1,校正依据为以训练集分类总精度最佳为宜,保存校正完成的最佳养分诊断模型为下一步养分亏缺诊断备用;
步骤7:利用三个养分元素丰缺状况分类模型生成新的概率特征因子
步骤7.1:针对氮、磷、钾每个养分元素,从每条冠层高光谱数据中选取步骤5筛选出的对每个养分元素亏缺敏感的波段并利用步骤6建立的每个养分元素的丰缺状况分类模型对其进行分类判别,得到每条光谱数据被分到各个类别的概率值,共计九个概率值,获得方法如下:
i选用对氮养分亏缺敏感的10个重要特征波段的光谱数据,输入针对氮养分训练得到的随机森林分类模型,获得每条光谱数据被分为重度缺氮、轻度缺氮、正常施肥的概率值;
ii选用对磷养分亏缺敏感的10个重要特征波段的光谱数据,输入针对磷养分训练得到的随机森林分类模型,获得每条光谱被分为重度缺磷、轻度缺磷、正常施肥的概率值;
iii选用对钾养分亏缺敏感的10个重要特征波段的光谱数据,输入针对钾养分训练得到的随机森林分类模型,获得每条光谱数据被分为重度缺钾、轻度缺钾、正常施肥的概率值。
步骤7.2:然后将所有的概率值组成了新的特征,将作为最终区分氮、磷、钾养分丰缺状况的特征因子;
步骤8:利用新生成的概率特征因子构建随机森林分类模型,获得氮、磷、钾养分亏缺状况的诊断结果;
利用新生成的概率特征因子构建新的随机森林分类模型(建立随机森林分类模型需对ntree和mtry参数校正,其中ntree的取值范围为100-1000,步长为100,mtry的取值范围为3-10,步长为1,校正依据以分类总精度最佳为宜;),确定新生成的概率特征因子属于重度缺氮、轻度缺氮、重度缺磷、轻度缺磷、重度缺钾、轻度缺钾、正常施肥的哪一个类别,即完成了氮、磷、钾养分亏缺状况的诊断;
在实施例中方法的结果与另外三种常用的诊断方法进行了对比,常用的方法包括单一随机森林分类模型、支持向量机分类模型、人工神经网络分类模型。所有模型均利用本方法筛选出的特征波段的反射率进行油菜养分诊断,并利用相同的独立测试数据集对模型进行精度评价,计算分类混淆矩阵、总体精度、kappa系数;不同方法的比较结果见表1;可以看到本实施例在各类评价指标上都体现出了较好的性能,其中总精度相对于单一的随机森林分类模型提高了16.74%,kappa系数提高了0.20;总精度相对于支持向量机分类模型提高了18.91%,kappa系数提高了0.20;总精度相对于人工神经网络分类模型提高了36.20%,kappa系数提高了0.40;特别是大大提高了对中度缺氮、中度缺钾、重度缺钾的诊断准确率,例如中度缺钾的用户精度从0.00%提高到87.50%,重度缺钾和中度缺钾的生产精度和用户精度在支持向量机和人工神经网络分类模型中均为0.00%,实施例中方法均有明显提高,其中证明了本发明的方法科学性和合理性。
表1本发明的集成方法(a),单一随机森林分类模型(b),支持向量机分类模型(c),人工神经网络分类模型(d)对油菜氮、磷、钾养分诊断的混淆矩阵和诊断精度对比。
(a)本发明的集成方法总精度:80.09%;kappa系数:0.75
(b)单一随机森林分类模型总精度:63.35%;kappa系数:0.55
(c)支持向量机分类模型总精度:61.99%;kappa系数:0.55
(d)人工神经网络分类模型总精度:43.89%;kappa系数:0.35
其它未详细说明的部分均为现有技术。尽管上述实施例对本发明做出了详尽的描述,但它仅仅是本发明一部分实施例,而不是全部实施例,人们还可以根据本实施例在不经创造性前提下获得其他实施例,这些实施例都属于本发明保护范围。
- 还没有人留言评论。精彩留言会获得点赞!