一种基于改进TOPSIS算法的稳态负载识别方法与流程
一种基于改进topsis算法的稳态负载识别方法
技术领域
1.本发明涉及非侵入式负载识别监测领域,具体涉及一种基于改进topsis算 法的稳态负载识别方法。
背景技术:
2.为设计研发新一代智能电表,实现用户家庭中大容量负荷的用电信息采集与 控制,电力公司迫切的需要改变如今电力系统的监管模式,提高监管效率。通过 将非侵入式负载识别模块嵌入到智能电表中,能够使电力公司获得更详细的用电 信息数据,从而在能源管理,电力系统维护,居民用电服务等方面产生重要作用, 为智能电网的建设提供助力。
3.为了实现智能电表下的非侵入式负载识别,现有的负载识别技术通常采用两 种方式。一种是采用多层神经网络并结合遗传算法和暂态能量的变化对用电设备 进行识别,这种方法借助深度学习,识别精度高,但都存在预训练过程,需要很 高的计算量,难以适用于一些轻量化的设备。另一种通过特征量与特征库模板进 行最大相似度分析来对用电设备进行识别,大大减少了计算花费,但也存在特征 信息利用不足,识别准确率不高的问题。
4.本文提出的一种基于改进topsis算法的稳态负载识别方法,采用特征匹配 的方法寻找最优解,避免了深度学习计算量高的问题。另一方面,基于topsis 算法的原理,其对于特征数量不敏感,增加特征类型并不会增大开销,同时使用 改进的组合赋权方法,充分发掘特征信息,提高识别精度,对于智能电表关于非 侵入式负载识别的开发具有很强的现实意义。
技术实现要素:
5.本发明的目的在于提供一种基于改进topsis算法的稳态负载识别方法,便 于集成在非侵入式负载采集设备上进行实时居民用电监测。为智能电表的用电节 能诊断、用电安全隐患辨识、电器性能评价等应用提供了技术基础。
6.实现本发明的技术方案为基于改进topsis算法的稳态负载识别方法,包括 以下步骤:
7.步骤1:获取一段时间负载稳定工作时的基本电气数据;
8.步骤2:根据电器数据以及基本的电气特征计算公式计算相应的特征值,并 建立负载特征库;
9.步骤3:将待测负载的稳态特征与步骤2所得特征库通过相似度计算公式求 取相似度贴合系数,得到相似度贴合矩阵a;
10.步骤4:在步骤3中的相似度贴合矩阵a的基础上,按照改进组合赋权公式 计算各稳态特征在负载识别中所占据的权重ωj;
11.步骤5:对步骤3中所得相似度贴合矩阵进行归一化处理,得归一化矩阵r;
12.步骤6:将步骤4所计算得到的权重系数与步骤5计算的归一化矩阵相乘, 得到带权贴合系数矩阵v;
13.步骤7:对步骤6计算的带权贴合系数矩阵使用topsis决策算法进行最优 理想解匹配,得到负载相似度接近指数序列di;
14.步骤8:根据相似度接近指数判断决策结果。
15.进一步地,所述步骤1中,基本的电气数据可以包括负载稳态工作电流有效 值、电压有效值、电流各次谐波、电压与电流的相位差。
16.进一步地,所述步骤2中电气特征值包括电流有效值、电压与电流的比值 (伏安比)、电流三次谐波、电流五次谐波、电流谐波畸变、有功功率;
17.其中电流谐波畸变thd和有功功率p的计算公式为:
[0018][0019]
p=uicosα
[0020]
其中ik为第k次谐波电流,i1为基波电流,ik为总的谐波电流含量;u为电 压有效值,i为电流有效值,α为电压与电流对应的绝对相位差。
[0021]
进一步地,所述步骤2中负载特征库的形式为矩阵形式,行表示可能出现的 负载类型,即样本种类,列表示特征类型,即每种样本对应的特征值,用d
ij
表示。
[0022]
进一步地,所述步骤3相似度贴合系数为a
ij
,所有的相似度贴合系数构成 了相似度贴合矩阵a,其相似度计算公式为:
[0023]aij
=|d
0-d
ij
|
1/2
[0024]
其中d0为待测负载对应的特征值。
[0025]
进一步地,所述步骤4中的改进组合赋权公式为独立性权重法与变异系数法 相结合的组合赋权法,组合方式采取线性加权合成的方法;
[0026]
其中独立性权重法的计算公式为:
[0027][0028][0029]
其中ri为复相关系数,xi为第i个特征值向量,为xi的最优线性组合,为xi的均值,pi为对应权重系数;
[0030]
变异系数法的计算公式为:
[0031][0032][0033]
其中μj和σj为第j个特征在所有样本下的均值和方差,vj为变异系数,qj为对应的权重系数;
[0034]
其中组合权重系数ωj的计算公式为:
[0035]
ωj=λpj+(1-λ)qj[0036]
其中λ为比例因子;
[0037]
进一步地,所述步骤5中的归一化操作的计算公式为:
[0038][0039]
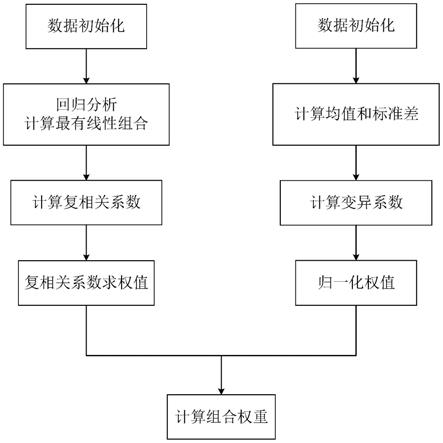
其中k为特征库样本数,n为特征库特征数;
[0040]
进一步地,所述步骤7的具体方法为:
[0041]
步骤7.1:在步骤6所得到的带权贴合系数矩阵v中,对每一个特征即每一 列求其正理想解x
+
和负理想解x-,分别为该列中的最大值和最小值:
[0042][0043][0044]
其中k为行数,n为列数,和分别为每一列 的最大和最小值;
[0045]
步骤7.2:计算各负载组合到正负理想解的综合距离s
+
和s-:
[0046][0047][0048]
步骤7.3:计算每种负载组合到正负理想解的相对接近指数di,该指数越大, 表明与待测负载越接近:
[0049][0050]
进一步地,所述步骤8中需设定一个相似度接近指数阈值,对于高于该阈值 的相似度接近指数,数值最大的对应样本即为判决的负载类型;若全部低于阈值 则视为判断失败,无匹配样本。
[0051]
本发明与现有技术相比,其显著优点为:
[0052]
(1)本发明使用非侵入式的方式进行负载识别,可以直接嵌入在智能电表 系统中,更加灵活方便,不需要中断设备供电,易于被用户接受,节省开支;
[0053]
(2)使用负载特征与特征库进行样本匹配的方式来进行判断,避免了深度 学习方式下样本数据的训练,减少了计算量,使其能够嵌入于轻量化的智能电表 等采集终端中,且特征库和辨识算法能够在线自动升级,便于电力公司等的维护;
[0054]
(3)使用基于独立性权重法和变异系数法的改进组合赋权方法对topsis算 法中权重进行计算,在多特征的基础上充分发掘特征信息,在轻量化计算条件下 保证足够的识别精度。
附图说明
[0055]
图1是本发明基于独立性权重法和变异系数法的改进组合赋权算法的流程 示意图;
[0056]
图2是本发明基于改进topsis算法的稳态负载识别方法流程示意图;
[0057]
图3是本发明使用topsis算法计算相似度接近指数的具体流程图。
具体实施方式
[0058]
下面结合说明书附图对本发明做进一步的说明
[0059]
如图1~图3,一种基于改进topsis算法的稳态负载识别方法,具体步骤如 下:
[0060]
步骤1:由独立性权重法计算权重。
[0061]
步骤1.1:数据初始化。将每种特征在不同负载样本下的相似度贴合系数作 为一个向量,有n种特征,即有n个向量。
[0062]
步骤1.2:回归分析,计算最优线性组合。对于每一个特征值向量xi,其余 剩下的所有特征值向量,总体上存在一个线性表示来近似xi,记为即称为xi的最优线性组合。一般可以使用最小二乘法来求最优线性组合,如下式(1)所 示得到
[0063][0064]
步骤1.3:计算复相关系数。计算每一个特征值向量对于其他特征值向量的 复相关系数ri,计算公式为(2):
[0065][0066]
其中ri为复相关系数,xi为第i个特征值向量,为xi的最优线性组合,为xi的均值。
[0067]
步骤1.4:计算权值。由1.3得到复相关系数列表r,对其中的每一个元素按 照式(3)归一化即可得到每一种特征所占的权重。
[0068][0069]
步骤2:由变异系数法计算权重。
[0070]
步骤2.1:数据初始化。获取相似度贴合矩阵。
[0071]
步骤2.2:计算均值和标准差。计算每一特征样本在所有负载样本下的均值 μj和标准差σj,其中j表示特征库中的第j种特征,具体的计算公式为(4):
[0072][0073]
步骤2.3:计算变异系数。计算第j项特征的变异系数vj:
[0074][0075]
步骤2.4:计算权值。对变异系数进行归一化,从而得到各指标的权重wj:
[0076][0077]
步骤3:计算组合权重。将两种赋权方法所获取的权值进行组合,使用线性 加权合成的方法,得到组合权重wj,具体的公式如下:
[0078]
wj=λpj+(1-λ)qjꢀꢀ
(7)
[0079]
其中pj和qj分别为两种赋权法单独计算得出的权重,λ为比例因子。
[0080]
结合图2基于改进topsis算法的稳态负载识别方法的具体步骤如下:
[0081]
步骤1:获取电器数据。由智能电表或采集器获取居民用电一段时间的稳定 电气数据。
[0082]
步骤2:计算特征值,建立特征库。根据电器数据以及基本的电气特征计算 公式计算相应的特征值,通过一定量的实测数据建立负载特征库。
[0083]
负载特征包括电流有效值、电压与电流的比值(伏安比)、电流三次谐波、 电流五次谐波、电流谐波畸变、有功功率。
[0084]
其中电流谐波畸变thd和有功功率p的计算公式为:
[0085][0086]
p=ui cosα
ꢀꢀ
(9)
[0087]
其中ik为第k次谐波电流,i1为基波电流,ik为总的谐波电流含量;u为电 压有效值,i为电流有效值,α为电压与电流对应的绝对相位差。
[0088]
步骤3:计算相似度贴合系数,得到相似度贴合矩阵。相似度贴合系数为a
ij
, 所有的相似度贴合系数构成了相似度贴合矩阵a,其计算公式为:
[0089]aij
=|d
0-d
ij
|
1/2
ꢀꢀ
(10)
[0090]
其中d0为待测负载对应的特征值。
[0091]
步骤4:组合赋权法计算权重。具体的计算过程见图1详细说明。
[0092]
步骤5:归一化处理。将相似度贴合矩阵a通过归一化公式(11)处理,得 到归一化矩阵r,
[0093][0094]
其中k为特征库样本数,n为特征库特征数。
[0095]
步骤5:计算带权贴合系数矩阵。将贴合系数矩阵中的元素分别乘以对应的 特征权重系数,得到带权贴合系数矩阵v。
[0096]
步骤6:使用topsis算法得到相似度接近指数。具体的计算过程见图3详 细说明。
[0097]
步骤7:判断结果。设定一个相似度接近指数阈值,对于高于该阈值的相似 度接近指数,数值最大的对应样本即为判决的负载类型;若全部低于阈值则视为 判断失败,无匹配样本。
[0098]
结合图3使用topsis算法计算相似度接近指数的具体步骤如下:
[0099]
步骤1:初始化数据。导入带权贴合系数矩阵v。
[0100]
步骤2:计算正理想解和负理想解。在带权贴合系数矩阵中,每一个特征值 下所有负载样本中的最大值为正理想解x
+
,最小值为负理想解x-,
[0101][0102][0103]
其中k为行数,n为列数,和分别为每一列 的最大和最小值。
[0104]
步骤3:计算各负载样本到正负理想解的综合距离。到正理想解的距离记为 s
+
,到负理想解的距离记为s-,
[0105][0106][0107]
步骤4:计算相对接近指数。计算每种负载组合到正负理想解的相对接近指 数di,该指数越大,表明与待测负载越接近:
[0108]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1