基于自训练的用于文本中的说话者识别的提取方法与流程
本公开通常涉及计算领域,并且更具体地涉及自然语言处理。
背景技术:
1、文本中的说话者识别旨在识别书籍等文本中每句话语的说话者。每句话语可以对应于单个说话者、多个说话者或未命名的说话者(例如,名词短语)。该任务可以分为诸如引文识别、命名实体识别、指代消除、候选说话者识别和基于特征的分类等多个子任务。
技术实现思路
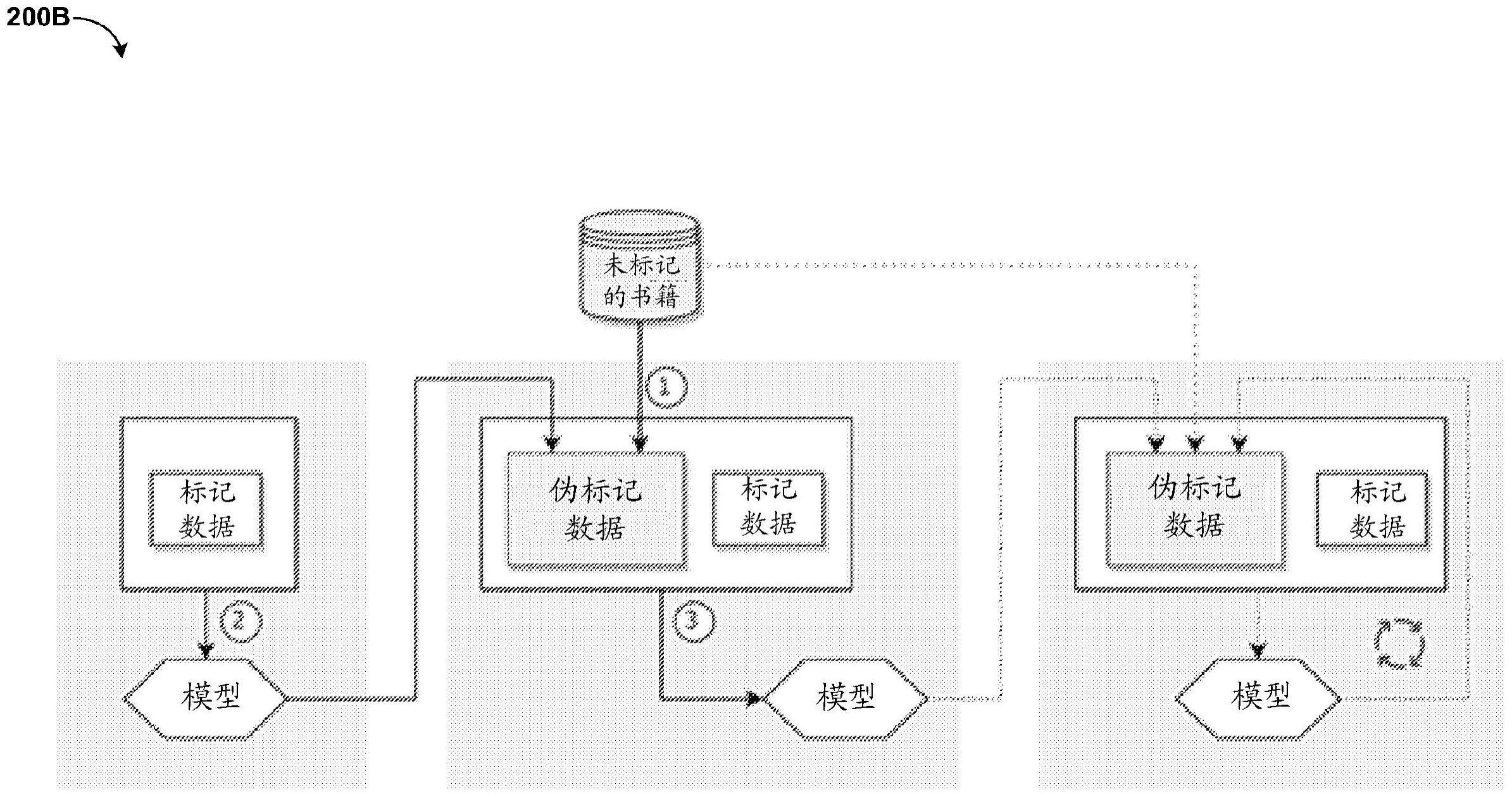
1、实施例涉及一种用于识别基于文本的作品中的说话者的方法、系统和计算机可读介质。根据一个方面,提供了一种用于识别基于文本的作品中的说话者的方法。该方法可以包括提取对应于一个或多个说话者的标记实例和未标记实例。基于该标记实例来推断提取的未标记实例的伪标签。基于推断的伪标签来标记该未标记实例中的一个或多个未标记实例。
2、根据另一个方面,提供了一种用于识别基于文本的作品中的说话者的计算机系统。该计算机系统可以包括一个或多个处理器、一个或多个计算机可读存储器、一个或者多个计算机可读有形存储设备、以及存储在一个或多个存储设备中的至少一个存储设备上的程序指令,该程序指令由该一个或多个处理器中的至少一个处理器经由该一个或多个存储器中的至少一个存储器执行,从而使得该计算机系统能够执行一种方法。该方法可以包括提取对应于一个或多个说话者的标记实例和未标记实例。基于该标记实例来推断提取的未标记实例的伪标签。基于推断的伪标签来标记该未标记实例中的一个或多个未标记实例。
3、根据又一个方面,提供了一种用于识别基于文本的作品中的说话者的计算机可读介质。该计算机可读介质可以包括一个或多个计算机可读存储设备和存储在一个或多个有形存储设备中的至少一个上的程序指令,该程序指令可由处理器执行。该程序指令可由用于执行方法的处理器执行,该方法可相应地包括:提取对应于一个或多个说话者的标记实例和未标记实例。基于该标记实例来推断提取的未标记实例的伪标签。基于推断的伪标签来标记该未标记实例中的一个或多个标记实例。
技术特征:
1.一种用于识别基于文本的作品中的说话者的方法,所述方法由处理器执行,包括:
2.根据权利要求1所述的方法,还包括:基于所述标记实例来训练第一模型。
3.根据权利要求2所述的方法,还包括:基于所述推断的伪标签和所述标记实例来训练第二模型。
4.根据权利要求3所述的方法,还包括:用所述第二模型来替换所述第一模型。
5.根据权利要求1所述的方法,其中,所述标记实例和所述未标记实例对应于说话者或引文。
6.根据权利要求1所述的方法,其中,所述标记实例和所述未标记实例对应于类令牌、包含话语的第一段文本中的令牌、分隔符令牌以及覆盖所述第一段文本的第二段文本中的令牌。
7.根据权利要求6所述的方法,其中,两个向量对应于每个令牌的估计概率,所述令牌是出现在所述第二段文本中的答案跨度的开始令牌或结束令牌。
8.一种用于识别基于文本的作品中的说话者的计算机系统,所述计算机系统包括:
9.根据权利要求8所述的计算机系统,还包括训练代码,被配置为使得所述一个或多个计算机处理器基于所述标记实例来训练第一模型。
10.根据权利要求9所述的计算机系统,还包括训练代码,被配置为使得所述一个或多个计算机处理器基于所述推断的伪标签和所述标记实例来训练第二模型。
11.根据权利要求10所述的计算机系统,还包括替换代码,被配置为使得所述一个或多个计算机处理器用所述第二模型来替换所述第一模型。
12.根据权利要求8所述的计算机系统,其中,所述标记实例和所述未标记实例对应于说话者或引文。
13.根据权利要求8所述的计算机系统,其中,所述标记实例和所述未标记实例对应于类令牌、包含话语的第一段文本中的令牌、分隔符令牌以及覆盖所述第一段文本的第二段文本中的令牌。
14.根据权利要求13所述的计算机系统,其中,两个向量对应于每个令牌的估计概率,所述令牌是出现在所述第二段文本中的答案跨度的开始令牌或结束令牌。
15.一种非暂时性计算机可读介质,其上存储有用于识别基于文本的作品中的说话者的计算机程序,所述计算机程序被配置为使得一个或多个计算机处理器执行以下操作:
16.根据权利要求15所述的计算机可读介质,其中,所述计算机程序还被配置为使得一个或多个计算机处理器基于所述标记实例来训练第一模型。
17.根据权利要求16所述的计算机可读介质,其中,所述计算机程序还被配置为使得一个或多个计算机处理器基于所述推断的伪标签和所述标记实例来训练第二模型。
18.根据权利要求17所述的计算机可读介质,其中,所述计算机程序还被配置为使得一个或多个计算机处理器用所述第二模型来替换所述第一模型。
19.根据权利要求15所述的计算机可读介质,其中,所述标记实例和所述未标记实例对应于说话者或引文。
20.根据权利要求15所述的计算机可读介质,其中,所述标记实例和所述未标记实例对应于类令牌、包含话语的第一段文本中的令牌、分隔符令牌以及覆盖所述第一段文本的第二段文本中的令牌。
技术总结
提供了一种用于识别基于文本的作品中的说话者的方法、计算机程序和计算机系统。提取对应于一个或多个说话者的标记实例和未标记实例。基于所述标记实例来推断提取的未标记实例的伪标签。基于推断的伪标签来标记所述未标记实例中的一个或多个未标记实例。
技术研发人员:于典,俞栋
受保护的技术使用者:腾讯美国有限责任公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!