缺陷检查装置、缺陷检查方法以及预测模型生成方法与流程
本发明涉及缺陷检查装置、缺陷检查方法以及预测模型生成方法,特别适用于使用通过机器学习生成的学习模型进行缺陷检查的装置及方法。
背景技术:
1、以往,已知有使用通过机器学习生成的学习模型,并根据被检查物的拍摄图像来判定有无缺陷的系统(例如参照专利文献1、2)。在专利文献1所记载的检查装置中,在被检查物的拍摄图像中根据规定的特征量提取一个以上的缺陷候补,针对包含提取出的缺陷候补的判断区域,使用通过机器学习构建的学习模型来判断有无缺陷。而且,在判断为判断区域的任意一个存在缺陷时,输出表示存在缺陷的信号,另一方面,在判断为判断区域全部不存在缺陷时,输出表示不存在缺陷的信号。在专利文献2所记载的图像评价装置中,不仅判定有无缺陷,还判定缺陷的种类。
2、专利文献1所记载的学习模型通过使用多个训练数据的监督学习而生成,该多个训练数据是对包含缺陷的图像赋予“有缺陷”的正解标签、对不包含缺陷的图像赋予“无缺陷”的正解标签而成的。而且,通过向这样生成的学习模型输入被检查物的拍摄图像,从而作为来自学习模型的输出而得到表示缺陷的有/无的信息。专利文献2所记载的学习模型通过使用多个训练数据的监督学习而生成,该多个训练数据是针对缺陷种类已知的图像赋予该缺陷的种类作为正解标签而成的。
3、在使用机器学习所得的学习模型进行缺陷检查的情况下,若被检查物的拍摄图像与作为训练数据而使用的图像相同,则能够得到正确的检查结果。然而,通常被检查物的拍摄图像与作为训练数据而使用的图像不会完全相同。该情况下,由于是通过基于从被检查物的拍摄图像提取的特征与从训练数据提取的特征(记录于学习模型的特征)的近似度的概率计算来进行判定,因此未必总是能够得到正确的检查结果。
4、从缺陷检查的性质来说,要求尽可能地减少将缺陷品判定为正常品的假阴性(检查中为阴性但实际上为阳性的情况)的误认(降低假阴性率、或者提高召回率(也称为灵敏度))。也就是说,期望学习模型具有检测“疑似缺陷”的能力。然而,在专利文献1、2所记载的学习模型中,存在如下问题:有可能同等程度发生将缺陷品判定为正常品的假阴性的误认和将正常品判定为缺陷品的假阳性(检查中为阳性但实际上为阴性的情况)的误认。
5、此外,还已知有一种分类装置,其通过对从样本图像提取出的缺陷区域(推测存在缺陷的区域)赋予该缺陷区域应被分类的缺陷种类的正解类别和作为相对于该正解类别的妥当性的尺度的确信等级的信息而生成训练数据,使用这样生成的训练数据来判定从被检查物的图像提取出的缺陷区域中包含的缺陷的种类(例如参照专利文献3)。该专利文献3中还公开了如下内容:作为正解类别而对一个缺陷区域赋予多个缺陷种类,并根据其确信等级对各正解类别赋予权重。
6、在该专利文献3所记载的分类装置中,由于生成对缺陷的种类设定了权重的训练数据,因此能够提高对于是哪个缺陷种类进行分类的精度。然而,在专利文献3所记载的分类装置中,以通过对检查图像进行图像解析而提取的缺陷区域作为对象生成表格形式的训练数据,并通过与该训练数据的对照来进行缺陷种类的分类。即,专利文献3所记载的分类装置并不是根据机器学习所得的学习模型来进行是正常品还是缺陷品的判定以及缺陷种类的判定。因此,即使使用专利文献3中记载的技术,也无法减少在根据学习模型进行缺陷检查时将缺陷品判定为正常品的假阴性的误认。
7、专利文献1:日本专利特开2021-110629号公报
8、专利文献2:日本专利特开2020-119135号公报
9、专利文献3:日本专利第4050273号公报
技术实现思路
1、本发明是为了解决这样的问题而完成的,其目的在于,在使用通过机器学习生成的学习模型进行缺陷检查的系统中,能够尽可能地减少将缺陷品判定为正常品的假阴性的误认。
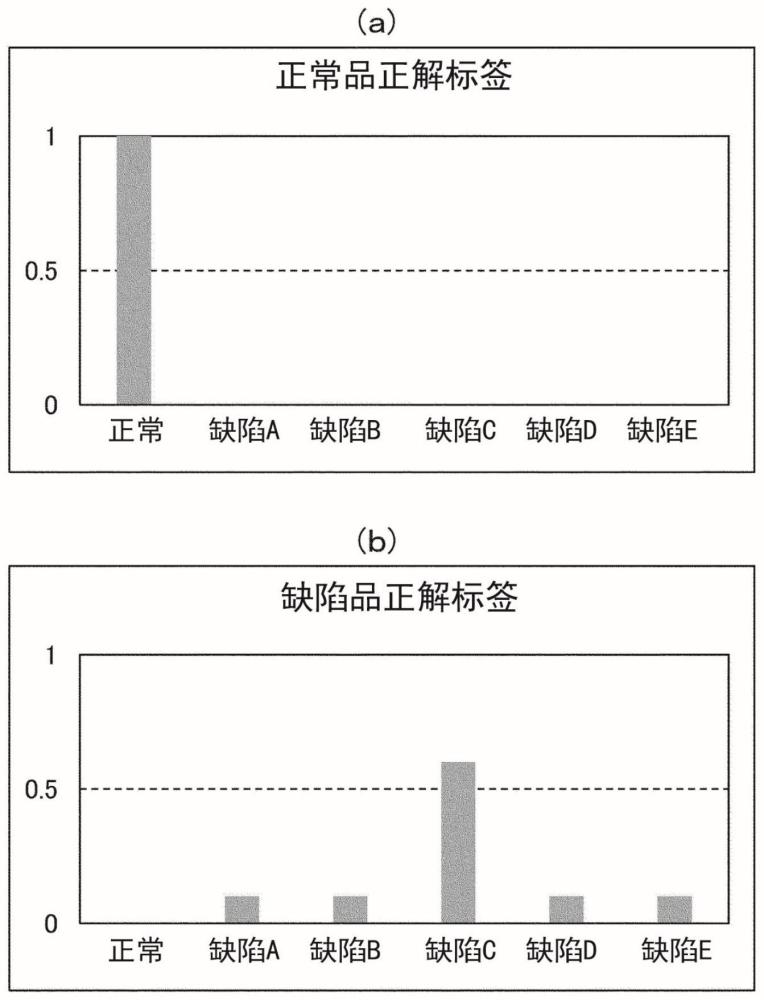
2、为了解决上述问题,在本发明中,通过将作为被检查物的拍摄图像的检查图像应用于使用训练数据学习完毕的预测模型,从而进行被检查物是否为正常品以及被检查物为缺陷品时的缺陷种类的预测。训练数据是对正常品的学习用图像赋予正常品正解标签,另一方面对缺陷品的学习用图像赋予缺陷品正解标签而成的,该正常品正解标签不包含表示符合缺陷品的可能性的标签而仅包含表示符合正常品的可能性的正常标签,该缺陷品正解标签不包含表示符合正常品的可能性的正常标签,而包含表示符合多个缺陷种类的可能性的多个缺陷种类标签及相对于各缺陷种类标签的权重。
3、(发明效果)
4、通过使用这样构成的训练数据进行预测模型的机器学习,从被赋予缺陷品正解标签的缺陷品的学习用图像预测为正常品时的损失值比从该学习用图像预测为正解以外的缺陷种类的缺陷品时的损失值大。由于预测模型是以使该损失值最小化的方式进行机器学习所得的模型,因此能够进一步降低误将缺陷品预测为正常品的可能性。由此,根据本发明,在使用通过机器学习生成的学习模型进行缺陷检查的系统中,能够尽可能地减少将缺陷品判定为正常品的假阴性的误认。
技术特征:
1.一种缺陷检查装置,其特征在于,具备:
2.根据权利要求1所述的缺陷检查装置,其特征在于,
3.一种缺陷检查方法,其特征在于,具有:
4.一种预测模型生成方法,其特征在于,具有:
技术总结
本发明作为用于生成预测模型的训练数据,使用正常品用的训练数据和缺陷品用的训练数据,该正常品用的训练数据是对正常品的学习用图像赋予仅包含表示符合正常品的可能性的正常标签的正常品正解标签而成,该缺陷品用的训练数据是对缺陷品的学习用图像赋予仅包含表示符合多个缺陷种类的可能性的加权的多个缺陷种类标签的缺陷品正解标签而成,由此,在机器学习时,从被赋予了缺陷品正解标签的缺陷品的学习用图像预测为正常品时的损失值比从该学习用图像预测为正解以外的缺陷种类的缺陷品时的损失值大,能够通过误将缺陷品预测为正常品的可能性进一步降低的预测模型进行缺陷检查。
技术研发人员:冈崎元树
受保护的技术使用者:株式会社F.C.C.
技术研发日:
技术公布日:2024/3/31
- 还没有人留言评论。精彩留言会获得点赞!