一种无人电动车的路径规划方法与流程
本发明属于电动汽车技术领域,更为具体地讲,涉及一种无人电动车的路径规划方法。
背景技术:
作为人们生活中的重要交通工具,汽车的大量使用带来了能源消耗,资源短缺,环境污染等一系列负面影响,而节能与环保问题目前已成为世界各国关注的主要社会问题。在此种背景下,电动汽车因其能源利用率高、零污染、噪声小等优点而受到了各国政府以及车企的重视,并开始步入实用化阶段。从上个世纪90年代开始,各个国家就已经纷纷出台优惠政策,投入研发经费来促进电动汽车的发展,比如中国的《汽车产业调整和振兴规划》、美国的《电动汽车和复合汽车的研究开发和样车试用法令》、日本的“绿色税制”以及德国的《国家电动汽车发展计划》等。与此同时,大型车企们也纷纷加大资金投入进行电动汽车的研发和生产。目前多种电动汽车品牌已经出现在市场上,如宝马的i3,奔驰的eqc,通用的bolt等。
电动汽车因其能源利用率高、零污染、噪声小等优点而受到了政府和车企的重视,然而其续航里程短、充电时间长的缺点使得电动汽车实际市场占有率远远低于预期。目前关于提高电动汽车续航里程,缩短充电时间的研究因其关键科学问题太难且成本过高等原因而面临巨大挑战。本专利将改进的增强学习算法运用到电动车的最优路径探索上。
增强学习也称为强化学习。增强学习就是将情况映射为行为,也就是去最大化收益。学习者并不是被告知哪种行为将要执行,而是通过尝试学习到最大增益的行为并付诸行动。也就是说增强学习关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。通过增强学习,一个智能体应该知道在什么状态下应该采取什么行为。rl是从环境状态到动作的映射的学习,我们把这个映射称为策略。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种无人电动车的路径规划方法,通过道路的评价最高值来规划无人电动车的路径。
为实现上述发明目的,本发明一种无人电动车的路径规划方法,其特征在于,包括以下步骤:
(1)、在最初的状态,电动车的起始位置为p0,初始电量为e0,初始状态为s0(p0,e0),电动车对每一条道路的评价q均设为0;从一个正太分布中随机抽取一个计步数k,已走步数设置为a=0;
(2)、电动车在与当前道路相邻道路中,以90%的概率选出其中评价最高的道路作为接下来要行驶的道路,以10%的概率随机选择一条道路作为接下来要行驶的道路,然后执行步骤(3);
(3)、当行驶完当前道路后,电动车到达另一个状态p’,e’,此时,电动车得到一个奖励r,电动车的已走步数:a=a+1;
(4)、比较a与k的大小,如果a等于k,则选择更新,执行步骤(5);如果a不等于k则执行步骤(2);
(5)、结合下一条道路中的最高评价值来更新当前道路的评价值:
在下一条道路中选择评价最高的道路最为规划路径,记其评价为qm
q当前道路=q当前道路+α(r+γqm-q当前道路)
其中,α代表学习速率,一般取0.1,γ代表对未来奖励的一个折扣率,一般取0.95;
重新抽取一个新的计步数k,并令已走步数a=0,再重新执行步骤(2)。
本发明的发明目的是这样实现的:
本发明一种无人电动车的路径规划方法,将电动车视为一个质点,道路视为一条条线段,在利用导航系统我们可以实时获得电动车的绝对位置pt(指各条道路的交点)以及电动车的电量et,利用二元组(pt,et)作为增强学习中的状态,其输出为电动车选择将要行驶哪一条道路,而选择的依据是电动车对与当前道路相邻的道路中评价最高的那一条道路作为将要行驶的道路。
附图说明
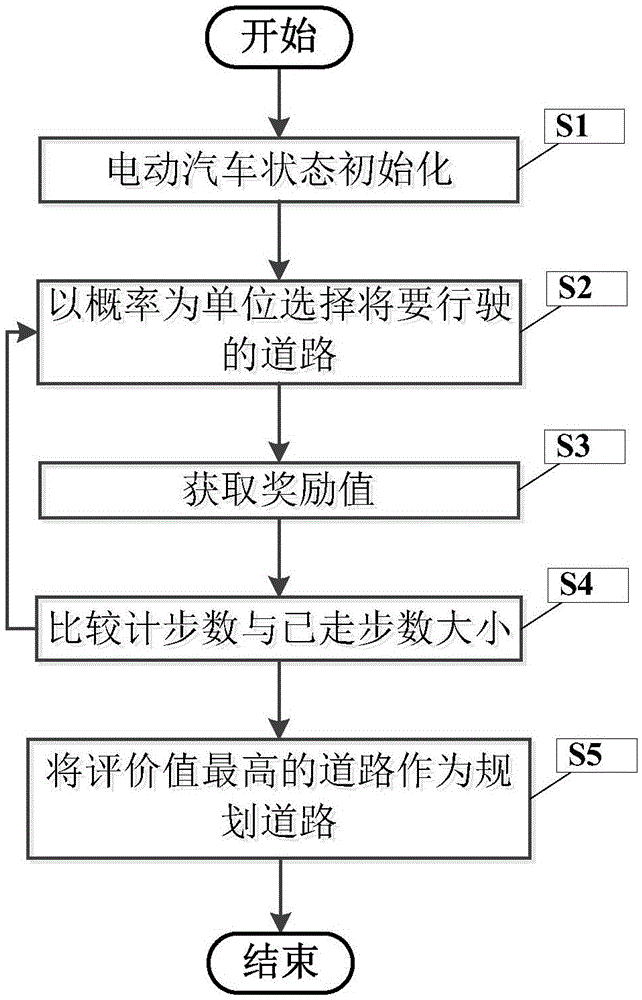
图1是本发明一种无人电动车的路径规划方法流程图;
图2是无人电动车路径规划对比图。
具体实施方式
下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。
实施例
图1是本发明一种无人电动车的路径规划方法流程图。
在本实施例中,如图1所示,本发明一种无人电动车的路径规划方法,包括以下步骤:
(1)、在最初的状态,电动车的起始位置为p0,初始电量为e0,初始状态为s0(p0,e0),电动车对每一条道路的评价q均设为0;从一个正太分布中随机抽取一个计步数k,已走步数设置为a=0;
(2)、电动车在与当前道路相邻道路中,以90%的概率选出其中评价最高的道路作为接下来要行驶的道路,以10%的概率随机选择一条道路作为接下来要行驶的道路,然后执行步骤(3);
(3)、当行驶完当前道路后,电动车到达另一个状态p’,e’,此时,电动车得到一个奖励r,电动车的已走步数:a=a+1;
(4)、比较a与k的大小,如果a等于k,则选择更新,执行步骤(5);如果a不等于k则执行步骤(2);
(5)、结合下一条道路中的最高评价值来更新当前道路的评价值:
在下一条道路中选择评价最高的道路最为规划路径,记其评价为qm
q当前道路=q当前道路+α(r+γqm-q当前道路)
其中,α代表学习速率,一般取0.1,γ代表对未来奖励的一个折扣率,一般取0.95;
重新抽取一个新的计步数k,并令已走步数a=0,再重新执行步骤(2)。
我们在sumo仿真平台下进行实验,图2为以100回合为一组,跑了50次后取每个回合取均值得到的结果,其中k服从int(n(4,1.5)。
在这里我们没有与具有优先级的经验回放制度做对比,因为其较高的计算复杂度,对于大型场景并不适用,所以不用做比较。从上图能看出三种方法最终均收敛在-1左右,但因为随机学习步数q学习用的当前样本条更新参数,所以收敛的最快,而组合q学习因为每次的训练集中含有当前样本条表现比传统的经验回放制要好。实验结果表示我们改进的算法在电动车的路径规划应用上收敛最快。
尽管上面对本发明说明性的具体实施方式进行了描述,以便于本技术领域的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本技术领域的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。
技术特征:
技术总结
本发明公开了一种无人电动车的路径规划方法,将电动车视为一个质点,道路视为一条条线段,在利用导航系统我们可以实时获得电动车的绝对位置pt(指各条道路的交点)以及电动车的电量et,利用二元组(pt,et)作为增强学习中的状态,其输出为电动车选择将要行驶哪一条道路,而选择的依据是电动车对与当前道路相邻的道路中评价最高的那一条道路作为将要行驶的道路。
技术研发人员:郭宏亮;何闵;杨其锦
受保护的技术使用者:电子科技大学
技术研发日:2018.11.30
技术公布日:2019.03.08
- 还没有人留言评论。精彩留言会获得点赞!