基于强化学习的无人驾驶汽车多车道行驶的决策方法与流程
本发明涉及无人驾驶汽车决策技术领域,尤其涉及一种基于强化学习的无人驾驶汽车多车道行驶的决策方法。
背景技术:
随着当今时代智能化高度发展,智能车辆的产生与发展已成为一种趋势。通过智能决策和规划,无人驾驶汽车可以大幅度提高公路的通行能力,减少拥堵,尽量避免交通事故,通过合理分配降低汽车油耗等。而行为决策作为无人驾驶车辆智能化水平的一个重要体现,它决定着无人驾驶车辆的安全性、高效性、舒适性等方方面面。目前驾驶行为决策主要以基于规则的或是基于学习算法的决策系统为主。例如中国专利申请号cn201510381349.9,名称“一种无人驾驶汽车自主变道决策方法”中通过基于规则设计车辆间的安全变道距离作为变道条件;中国专利申请号cn201811524283.4,名称“一种基于规则与学习模型的无人驾驶汽车驶离高速的方法”中将规则模型与学习模型在不同环境下切换决策实现无人驾驶汽车安全下匝道任务。以上专利的决策系统依托神经网络模型或有限状态机模型进行决策,但神经网络需要的样本数量往往很大且容易过拟合,参数不易确定。有限状态机模型没有充分考虑环境的不确定性,在复杂的环境中,许多因素往往不能提前精确建模且在复杂环境下涉及状态增多时不便于管理。
技术实现要素:
本发明所要解决的技术问题是针对于上述现有技术的不足,提供一种基于强化学习的无人驾驶汽车多车道行驶的决策方法。
本发明为解决上述技术问题采用以下技术方案:
基于强化学习的无人驾驶汽车多车道行驶的决策方法,其包括以下步骤:
步骤1),基于小角度假设建立车辆的动力学模型和轮胎模型,建立动力学模型时结合转向工况下轮胎的侧偏力、驱动制动力、以及轮胎侧偏角进行单个轮胎和整车的受力分析,并对前轮偏角及横摆角建立约束条件;
步骤2),对ngsim数据库中us-101数据集的数据进行绘图分析,获取驾驶行为决策样本数据;
所述ngsim数据库中us-101数据集的数据包括:车辆进入检测路段先后编号、开始检测时刻为起点的时间序列编号、车头中心距路段左侧边缘距离x、车头中心距路段起点距离y、车辆瞬时速度、车辆瞬时加速度;
步骤3),构建强化学习训练模型、搭建bp神经网络前向传播结构并获取随机执行动作,基于强化学习算法的目标函数选择与执行动作相对应的收益函数,在此基础上采用基于策略梯度的强化学习算法反向更新神经网络权值,建立基于强化学习-bp神经网络算法的决策系统;
步骤4),基于上述决策系统获取执行动作并预测车辆行驶状态,由收益函数判断车辆行驶危险度,决策多车道工况下车辆当前时刻的最优驾驶行为,以提高汽车行驶时的安全性及高效性。
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,步骤1)中基于小角度假设建立车辆动力学模型和轮胎模型的具体步骤如下:
以车辆自身质心o为坐标原点,沿车辆纵轴建立x轴,垂直于x轴并过质心o作y轴,形成车辆坐标系,对车辆沿x轴,y轴和绕z轴的受力进行分析:
式中,
对动力学模型进行简化,减少计算时间,在计算轮胎力时,采用小角速度假设:
式中,δf表示前轮偏角;
基于较小的前轮偏角和将轮胎模型线性化处理后的车辆动力学模型如下:
式中:ccf、ccr表示前、后轮胎侧偏刚度;clf、clr表示前、后轮胎纵向刚度;sf、sr表示前、后轮胎的纵向滑移率;
轮胎模型如下:
式中:系数b、c、d由轮胎的垂直载荷和外倾角决定,b为刚度因子;c为形状因子;d为峰值因子;y()为输出变量代表轮胎所受的各方向力及力矩;x为输入变量,表示轮胎的侧偏角或纵向滑移率;fz为轮胎所受垂直载荷,γ为轮胎外倾角,e为曲率因子,sv为垂直偏移,sh为水平偏移,a1~a15为预先由轮胎实验数据拟合得到的参数值。
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,所述步骤3)中建立基于强化学习-bp神经网络算法的决策系统的具体步骤如下:
步骤3.1),建立bp神经网络的前向传播结构,初始化神经网络各层神经元之间的权值、阈值以及学习速率、迭代次数,设置强化学习算法的训练工况及障碍车参数;
步骤3.2),计算自车与自车周围车辆的车头时距信息作为bp神经网络的输入值,通过bp神经网络的前向传播得到输出动作,选取概率最大的动作作为决策动作;
步骤3.3),建立强化学习算法的收益函数r(τ),调用收益函数得到决策动作所对应的收益值;
步骤3.4),执行决策动作ut得到新的目标车状态st+1后重新执行步骤3.2)、步骤3.3)得到新的决策动作ut+1及所对应的收益值r;
步骤3.5),设定探索学习n次记为一条轨迹τ,将一条轨迹内每次决策动作的概率代入轨迹似然概率式中得轨迹τ在每一次的探索学习中可能出现的概率p(τ;θ),累加每次决策动作获得的收益值得到r(τ);
步骤3.6),将p(τ;θ)、r(τ)代入基于策略梯度的强化学习算法公式中得到策略梯度,再更新目标参数,这里的θ代表神经网络中输入层到隐含层的权值w;
步骤3.7),重复步骤3.2)至步骤3.6)n次以获取稳定且最优的权值,调用得到的最优权值对bp神经网络进行训练并利用ngsim数据集中得到的样本集检验决策的准确性。
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,n取500。
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,所述步骤3.1)中的训练工况为高速三车道,障碍车参数包括所在车道编号、相对坐标原点位置、自车速度、加速度。
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,所述步骤3.2)中的bp神经网络参数设定为输入层神经元个数5个,对应周围障碍车的车头时距;隐含层神经元个数13个;输出层神经元个数3个,分别为:直行、左转、右转。
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,所述步骤3.3)中强化学习算法收益函数r(τ)的收益值设置如下:
当车头时距小于1.75时车辆处于危险环境中,收益值设为负且随危险度增高而增大;车头时距在1.9-2.1之间时车辆处于相对安全环境,收益值设为正且最大;车头时距大于10时虽然车辆处于绝对安全状态但对于行驶的高效性是不利的,收益值设定为负。
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,所述步骤3.5)中轨迹似然概率公式如下:
式中,p(τ(i);θ)为轨迹的似然概率,表示在给定参数θ的情况下轨迹τ(i)出现的概率;
作为本发明基于强化学习的无人驾驶汽车多车道行驶的决策方法进一步的优化方案,所述步骤3.6)中基于策略梯度的强化学习算法公式包含:
目标函数u(θ):
式中,θ为目标函数的最优参数,r(st,ut)为在状态为st时采取动作ut所获得的收益值,πθ为当前状态下的策略,参数r(τ)表示每条轨迹τ的回报函数;p(τ;θ)表示每条轨迹τ在每一次的探索学习中可能出现的概率大小;
策略梯度算法参数更新方法:
式中,α为学习速率;
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
本发明提出的基于强化学习的无人驾驶汽车多车道行驶的决策方法,适用于无人驾驶汽车自主决策出多车道工况下车辆当前时刻的最优驾驶行为,规划路径,躲避障碍;且对紧急情况有较好的学习适应能力,有助于提高汽车行驶时的安全性及高效性。
本发明提出的强化学习-bp神经网络决策算法能够充分发挥强化学习在不决定环境下学习具有的试错性,目标导向等特质,建立适当环境模型即可进行遍历学习,大大减少了样本数据且由于奖励函数的存在使决策学习具有针对性。
附图说明
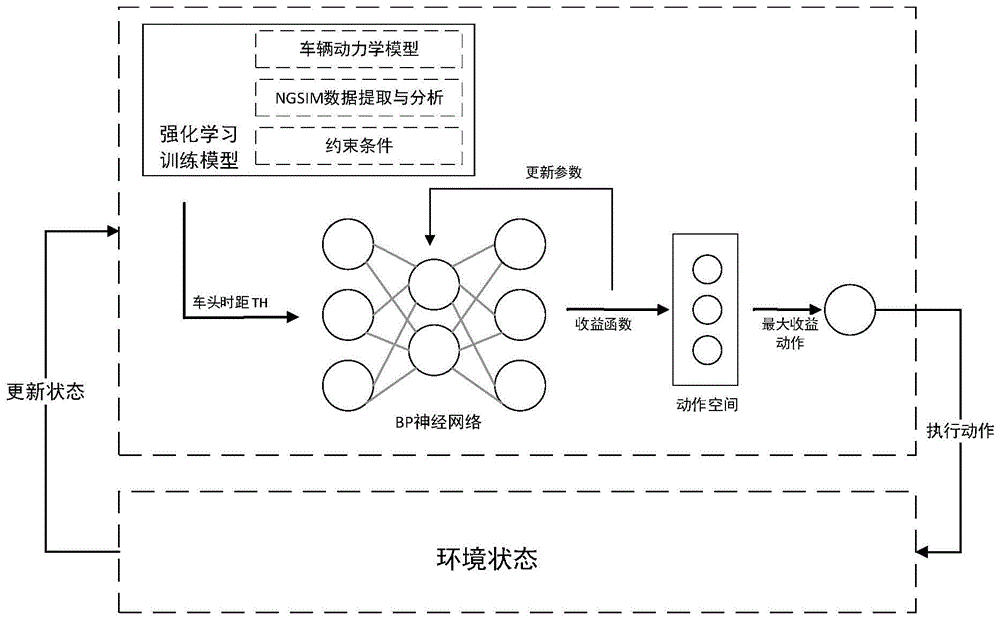
图1是本发明的原理示意图;
图2是本发明的流程示意图;
图3是本发明中强化学习算法的训练工况图。
具体实施方式
下面结合附图对本发明的技术方案做进一步的详细说明:
本发明可以以许多不同的形式实现,而不应当认为限于这里所述的实施例。相反,提供这些实施例以便使本公开透彻且完整,并且将向本领域技术人员充分表达本发明的范围。在附图中,为了清楚起见放大了组件。
参照图1所示,本发明的一种基于强化学习的无人驾驶汽车多车道行驶的决策方法,其包括以下步骤:
(1)建立基于小角度假设下的车辆动力学模型和轮胎模型,在动力学模型的建立过程中结合转向工况下的轮胎侧偏力和驱动制动力,轮胎侧偏角进行了单个轮胎和整车的受力分析,并针对车辆实际行驶过程中的情况对前轮偏角及横摆角建立约束条件。
(2)对ngsim数据库中的us-101部分数据进行绘图分析,获取驾驶行为决策样本数据,为决策系统的构建奠定基础。
ngsim数据库中所用数据包括:车辆进入检测路段先后编号、开始检测时刻为起点的时间序列编号、车头中心距路段左侧边缘距离x、车头中心距路段起点距离y、车辆瞬时速度、车辆瞬时加速度。
(3)基于上述步骤(1)、(2),构建强化学习训练模型,搭建bp神经网络前向传播结构获取随机动作,基于强化学习算法的目标函数设计与执行动作相对应的收益函数,在此基础上采用基于策略梯度的强化学习算法反向更新神经网络权值,建立基于强化学习-bp神经网络算法的决策系统。
(4)基于上述决策系统获取执行动作并预测车辆行驶状态,由收益函数判断车辆行驶危险度,决策多车道工况下车辆当前时刻的最优驾驶行为,以提高汽车行驶时的安全性及高效性。
其中,所述步骤(1)中的基于小角度假设下的动力学模型建立方法为:以车辆自身质心o为坐标原点,沿车辆纵轴建立x轴,垂直于x轴并过质心o作y轴,xoy构成了固定于车身的车辆坐标系。对车辆沿x轴,y轴和绕z轴的受力进行分析:
式中,
对动力学模型进行简化,减少计算时间,在计算轮胎力时,采用小角速度假设:
式中,δf表示前轮偏角。
基于较小的前轮偏角和将轮胎模型线性化处理后的车辆动力学模型:
式中:ccf、ccr表示前、后轮胎侧偏刚度;clf、clr表示前、后轮胎纵向刚度;sf、sr表示前、后轮胎的纵向滑移率。
轮胎模型:
式中:系数b,c,d由轮胎的垂直载荷和外倾角决定;b为刚度因子;c为形状因子;d为峰值因子;y为输出变量代表轮胎所受的各方向力及力矩;x为输入变量,可表示轮胎的侧偏角或纵向滑移率;fz为轮胎所受垂直载荷,γ为轮胎外倾角,sv为垂直偏移,e为曲率因子,sh为水平偏移;a1~a15为参数值,由轮胎实验数据拟合得到。
其中,所述步骤(2)中us-101数据集包含了79辆车在不同时刻的速度,车道位置以及每一时刻其周围车辆信息。根据以下公式采集目标车辆与前方车辆及左后、右后方车辆的车头时距信息:
式中,s1为前车行驶位置;s2为后车行驶位置;v为后车速度。
参考图2所示,上述步骤(3)中基于强化学习-bp神经网络算法,其包括以下步骤:
步骤3.1:首先建立bp神经网络的前向传播结构,初始化神经网络各层神经元之间的权值、阈值以及学习速率、迭代次数,设置强化学习算法的训练工况及障碍车各参数。
步骤3.2:计算目标车与障碍车之间的车头时距信息作为bp神经网络的输入值。通过bp神经网络的前向传播得到输出动作,选取概率最大的动作作为决策动作。
步骤3.3:建立强化学习算法的收益函数r(τ),调用收益函数得到决策动作所对应的收益值。
步骤3.4:执行决策动作ut得到新的目标车状态st+1,重复步骤3.2、3.3得到新的决策动作ut+1及所对应的收益值r。
步骤3.5:设定探索学习500次记为一条轨迹τ,将一条轨迹内每次决策动作的概率代入轨迹似然概率式中得轨迹τ在每一次的探索学习中可能出现的概率p(τ;θ),累加每次决策动作获得的收益值得到r(τ)。
步骤3.6:将p(τ;θ)、r(τ)代入基于策略梯度的强化学习算法公式中得到策略梯度,再更新目标参数,这里的θ代表神经网络中输入层到隐含层的权值w。
步骤3.7:重复步骤3.2~3.6,设定迭代次数为500次以获取稳定且最优的权值,调用得到的最优权值对bp神经网络进行训练并利用ngsim数据集中得到的样本集检验决策的准确性。
其中,所述步骤3.2中的bp神经网络参数设定为输入层神经元个数5个,对应周围障碍车的车头时距;隐含层神经元个数13个;输出层神经元个数3个,分别为决策执行动作:直行,左转,右转。
其中,所述步骤3.3中强化学习算法收益函数r(τ),收益函数的设置与危险度有关,当车头时距小于1.75时车辆处于危险环境中,收益值设为负且随危险度增高而增大;车头时距在1.9-2.1之间时车辆处于相对安全环境,收益值为正且最大;车头时距大于10时虽然车辆处于绝对安全状态但对于行驶的高效性是不利的,所以收益值设定为负。
其中,所述步骤3.5中轨迹似然概率公式:
式中,p(τ(i);θ)为轨迹的似然概率,表示在给定参数θ的情况下轨迹τ(i)出现的概率;
其中,所述步骤3.6中基于策略梯度的强化学习算法公式包含:
目标函数:
式中,θ为目标函数的最优参数,r(st,ut)为在状态为st时采取动作ut所获得的收益值,πθ为当前状态下的策略,参数r(τ)表示每条轨迹τ的回报函数。p(τ;θ)表示每条轨迹τ在每一次的探索学习中可能出现的概率大小。
策略梯度算法参数更新方法:
式中,α为学习速率。
参考图3所示,上述步骤3.1中的训练工况为高速三车道,1号为自车,2-6号为障碍车。障碍车参数包括所在车道编号,相对坐标原点位置,速度、加速度。“一,二,三”代表车道标号;th为目标车与障碍车之间的车头时距,作为神经网络的输入共有五个值需要实时计算。箭头为每次决策所做出的三个动作:直行、左转、右转。
本技术领域技术人员可以理解的是,除非另外定义,这里使用的所有术语(包括技术术语和科学术语)具有与本发明所属领域中的普通技术人员的一般理解相同的意义。还应该理解的是,诸如通用字典中定义的那些术语应该被理解为具有与现有技术的上下文中的意义一致的意义,并且除非像这里一样定义,不会用理想化或过于正式的含义来解释。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限制本发明,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!