基于DDPG和分层强化学习的移动机器人导航方法和系统
本发明涉及移动机器人路径规划,具体涉及一种基于ddpg和分层强化学习的移动机器人导航方法和一种基于ddpg和分层强化学习的移动机器人导航系统。
背景技术:
1、随着人工智能技术的发展,移动机器人逐渐走进了我们的日常生活。尤其在服务行业更加繁荣,因此,人类对移动机器人的需求也变得越来越重要。移动机器人的路径规划一直是机器人学领域的一个关键问题,需要自主移动的机器人根据约束条件找到一条从初始位置到目标位置的通畅路径。随着移动机器人面临的环境越来越复杂,因此要求移动机器人具有更高水平的预测障碍物并避免与其相撞的能力。
2、在传统的导航解决方案中,如遗传算法和模拟退火法等,已经在导航中取得了良好的效果。然后,这些方法假定的环境是已知的,实际的导航精度依赖于已知的信息的准确性。但是当移动机器人面临的导航任务十分复杂,甚至需要在一些具有不确定因素或者全局信息未知的特定环境下执行任务时,传统的算法已不再适用。
技术实现思路
1、本发明为解决上述技术问题,提供了一种基于ddpg和分层强化学习的移动机器人导航方法和系统,能够在未知的环境中精准的完成目标导航,并且能够避免与障碍物相撞。
2、本发明采用的技术方案如下:
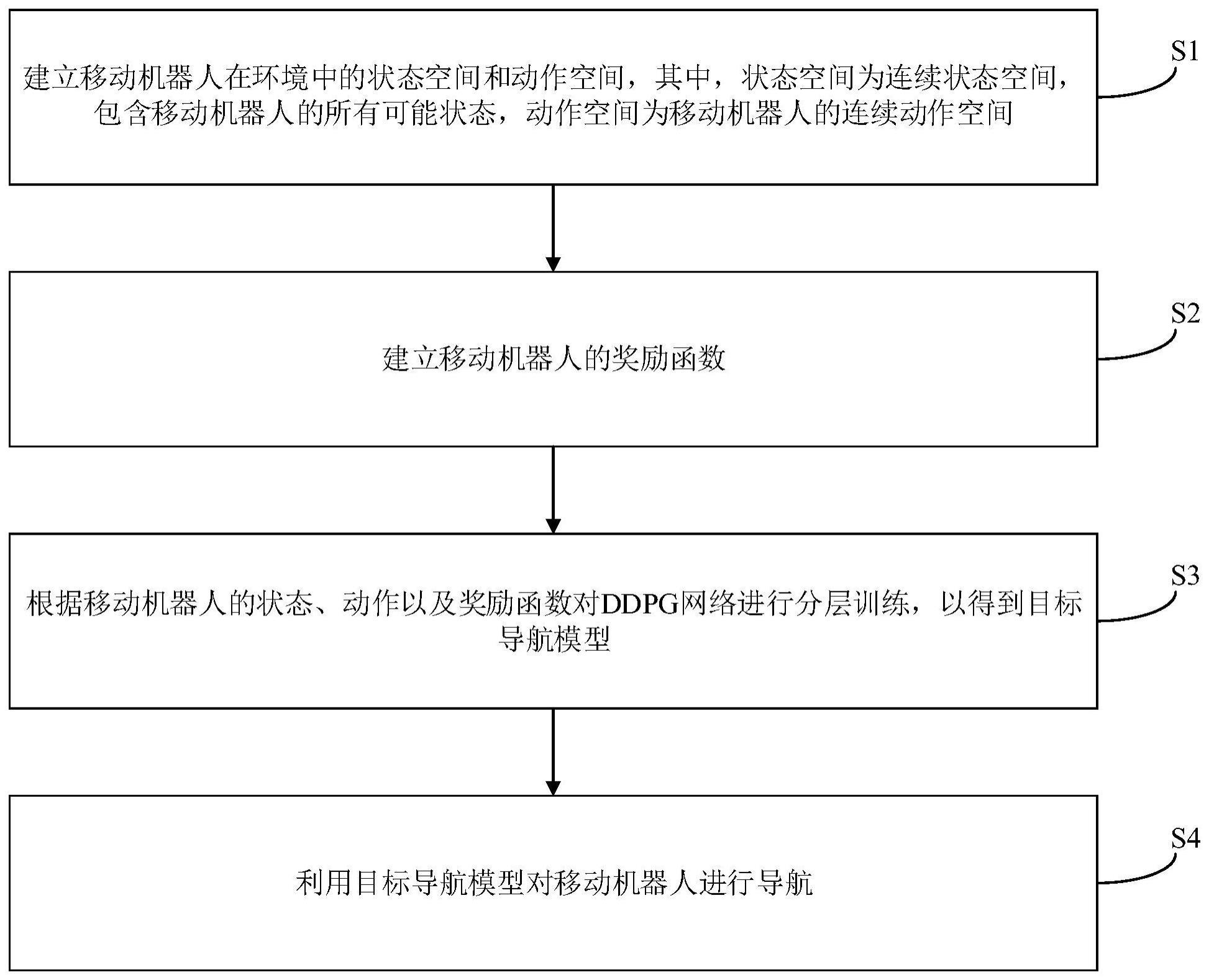
3、一种基于ddpg和分层强化学习的移动机器人导航方法,包括以下步骤:建立移动机器人在环境中的状态空间和动作空间,其中,所述状态空间为连续状态空间,包含所述移动机器人的所有可能状态,所述动作空间为所述移动机器人的连续动作空间;建立所述移动机器人的奖励函数;根据所述移动机器人的状态、动作以及奖励函数对ddpg网络进行分层训练,得到目标导航模型;利用所述目标导航模型对所述移动机器人进行导航。
4、所述移动机器人在环境中的状态空间包括所述移动机器人的位置、所述移动机器人的角速度、所述移动机器人的线速度和所述移动机器人所处的环境信息。
5、所述移动机器人在环境中的动作空间包括所述移动机器人的旋转角度和所述移动机器人的前进距离。
6、所述奖励函数为:
7、r(t)=rnor+rdis+robs+ra
8、其中,r(t)为奖励函数,rnor为常规奖励项,rdis为距离奖励项,robs为障碍物惩罚项,ra为所述移动机器人旋转角度惩罚项。
9、对ddpg网络进行训练具体包括:构建数据集,所述数据集为所述移动机器人在每个时刻的状态信息;将所述数据集输入至ddpg网络对所述移动机器人进行目标导航训练,以得到所述移动机器人的目标导航模型;通过所述移动机器人的目标导航模型利用ddpg网络对所述移动机器人进行行进间避障训练,其中,对所述移动机器人进行行进间避障训练基于所述目标导航模型基础之上。
10、一种基于ddpg和分层强化学习的移动机器人导航系统,包括:第一建立模块,所述第一建立模块用于建立移动机器人在环境中的状态空间和动作空间,其中,所述状态空间为连续状态空间,包含所述移动机器人的所有可能状态,所述动作空间为所述移动机器人的连续动作空间;第二建立模块,所述第二建立模块用于建立所述移动机器人的奖励函数;训练模块,所述训练模块用于根据所述移动机器人的状态、动作以及奖励函数对ddpg网络进行分层训练;导航模块,所述导航模块用于利用所述目标导航模型对所述移动机器人进行导航。
11、所述移动机器人在环境中的状态空间包括所述移动机器人的位置、所述移动机器人的角速度、所述移动机器人的线速度和所述移动机器人所处的环境信息。
12、所述移动机器人在环境中的动作空间包括所述移动机器人的旋转角度和所述移动机器人的前进距离。
13、所述奖励函数为:
14、r(t)=rnor+rdis+robs+ra
15、其中,r(t)为奖励函数,rnor为常规奖励项,rdis为距离奖励项,robs为障碍物惩罚项,ra为所述移动机器人旋转角度惩罚项。
16、对ddpg网络进行训练具体包括:构建数据集,所述数据集为所述移动机器人在每个时刻的状态信息;通过建立移动机器人在环境中的状态空间和动作空间以及奖励函数,并根据移动机器人的状态、动作以及奖励函数对ddpg网络进行训练,得到目标导航模型,并利用目标导航模型对移动机器人进行导航。
17、本发明的有益效果:
18、本发明通过建立移动机器人在环境中的状态空间和动作空间以及奖励函数,并根据移动机器人的状态、动作以及奖励函数对ddpg网络进行分层训练,得到目标导航模型,并利用目标导航模型对移动机器人进行导航,由此,能够在未知的环境中精准的完成目标导航,并且能够避免与障碍物相撞。
技术特征:
1.一种基于ddpg和分层强化学习的移动机器人导航方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于ddpg和分层强化学习的移动机器人导航方法,其特征在于,所述移动机器人在环境中的状态空间包括所述移动机器人的位置、所述移动机器人的角速度、所述移动机器人的线速度和所述移动机器人所处的环境信息。
3.根据权利要求1所述的基于ddpg和分层强化学习的移动机器人导航方法,其特征在于,所述移动机器人在环境中的动作空间包括所述移动机器人的旋转角度和所述移动机器人的前进距离。
4.根据权利要求1所述的基于ddpg和分层强化学习的移动机器人导航方法,其特征在于,所述奖励函数为:
5.根据权利要求1所述的基于ddpg和分层强化学习的移动机器人导航方法,其特征在于,对ddpg网络进行训练具体包括:
6.一种基于ddpg和分层强化学习的移动机器人导航系统,其特征在于,包括:
7.根据权利要求6所述的基于ddpg和分层强化学习的移动机器人导航系统,其特征在于,所述移动机器人在环境中的状态空间包括所述移动机器人的位置、所述移动机器人的角速度、所述移动机器人的线速度和所述移动机器人所处的环境信息。
8.根据权利要求6所述的基于ddpg和分层强化学习的移动机器人导航系统,其特征在于,所述移动机器人在环境中的动作空间包括所述移动机器人的旋转角度和所述移动机器人的前进距离。
9.根据权利要求6所述的基于ddpg和分层强化学习的移动机器人导航系统,其特征在于,所述奖励函数为:
10.根据权利要求6所述的基于ddpg和分层强化学习的移动机器人导航系统,其特征在于,对ddpg网络进行训练具体包括:
技术总结
本发明提供一种基于DDPG和分层强化学习的移动机器人导航方法和系统,其中,所述方法包括以下步骤:建立移动机器人在环境中的状态空间和动作空间,其中,所述状态空间为连续状态空间,包含所述移动机器人的所有可能状态,所述动作空间为所述移动机器人的连续动作空间;建立所述移动机器人的奖励函数;根据所述移动机器人的状态、动作以及奖励函数对DDPG分层网络进行训练,得到目标导航模型;利用所述目标导航模型对所述移动机器人进行导航。本发明能够在未知的环境中精准的完成目标导航,并且能够避免与障碍物相撞。
技术研发人员:黄宪振,范洪辉,朱洪锦,盛小春,张翔平
受保护的技术使用者:江苏理工学院
技术研发日:
技术公布日:2024/1/12
- 还没有人留言评论。精彩留言会获得点赞!