一种基于强化学习的多机编队协同控制策略优化方法与流程
本申请属于飞机控制,特别涉及一种基于强化学习的多机编队协同控制策略优化方法。
背景技术:
1、在现代战争中,无人机由于成本低,使用方便,机动性能好,适应性强,不存在飞行员伤亡等特点,发挥着越来越重要的作用。多架无人机组成编队,相互配合协同执行同一任务可以明显提高任务执行效率和任务完成的概率,而且还能够执行更为复杂、多样化的任务。但是,由于受到无人机自身载荷以及智能化程度限制,对于某些特定的任务,往往无法完成。因此,世界各军事强国都在发展有人/无人机协同编队技术。
2、目前,国外非常重视有人/无人机协同编队的发展,早在上个世纪便进行了相关研究和试飞验证,探索有人机与无人机平台协同作战的方法,并进行了大量的飞行试验,实现了有人/无人机协同编队作战控制策略、无人机智能化控制、无人机集群控制等技术的突破。
3、国内在有人/无人机协同编队控制技术研究领域仍处于初始理论研究阶段。但有人/无人机协同编队作战技术的研究已经受到重视。在有人机与无人机协同作战方式与流程、作战平台能力需求分析、编队队形控制、协同任务管理等方面都取得了一定的研究成果。
4、然而,国内与国外发达国家相比,不管在有人/无人机协同编队理论研究方面还是实际飞行试验方面都存在很大的差距,无人机的智能化程度和自主控制能力、有人/无人机协同编队控制策略有待进一步提升。
技术实现思路
1、为了解决上述技术问题至少之一,本申请设计了一种基于强化学习的多机编队协同控制策略优化方法,以增强飞机的智能化程度,拓展多机编队的任务类别,提升多机编队的任务完成率。该多机编队协同控制策略优化主要包括:
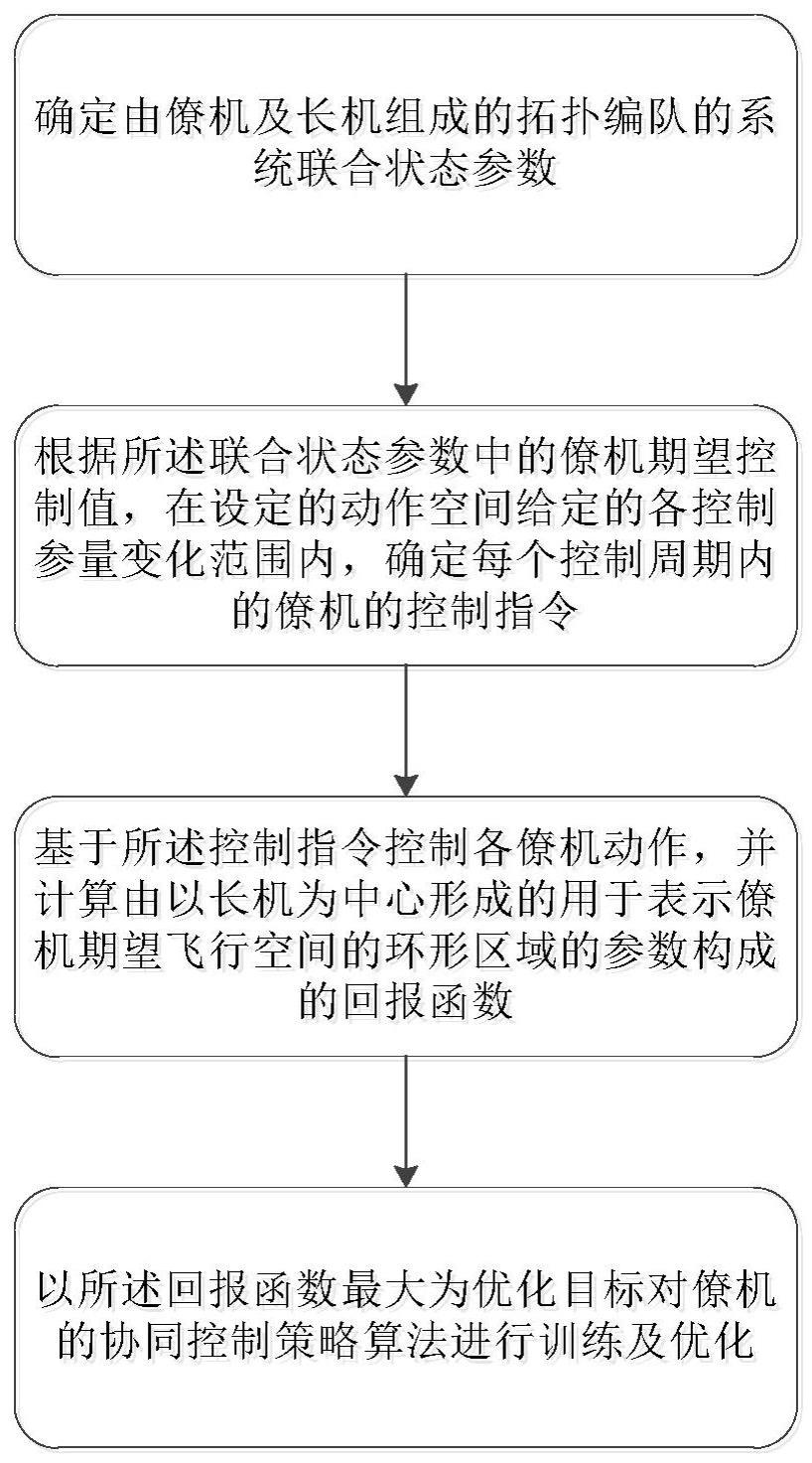
2、步骤s1、确定由僚机及长机组成的拓扑编队的系统联合状态参数;
3、步骤s2、根据所述联合状态参数中的僚机期望控制值,在设定的动作空间给定的各控制参量变化范围内,确定每个控制周期内的僚机的包含对各控制参量更新的控制指令;
4、步骤s3、基于所述控制指令控制各僚机动作,并计算由以长机为中心形成的用于表示僚机期望飞行空间的环形区域的参数构成的回报函数;
5、步骤s4、以所述回报函数最大为优化目标对僚机的协同控制策略算法进行训练及优化。
6、优选的是,步骤s1进一步包括:
7、步骤s11、获取僚机自身的僚机飞行状态参数及获取长机的长机飞行状态参数;
8、步骤s12、获取长机的包含期望滚转角及期望速度的控制策略参数;
9、步骤s13、基于所述僚机飞行状态参数、长机飞行状态参数、控制策略参数确定所述系统联合状态参数。
10、优选的是,步骤s1中,所述僚机飞行状态参数包括僚机的坐标值、僚机的航向角、僚机的滚转角及僚机的飞行速度,所述长机飞行状态参数包括长机的坐标值,长机的航向角、长机的滚转角及长机的飞行速度,所述系统联合状态参数至少包括僚机相对于长机的平面位置、航向角只差、长机的期望滚转角、长机的期望速度。
11、优选的是,步骤s2中,所述控制参量变化范围包括但不限于:俯仰角变化范围、偏航角变化范围、滚转角变化范围以及飞行速度变化范围。
12、优选的是,步骤s2中,确定所述控制指令包括:
13、步骤s21、获取各僚机的期望滚转角及期望速度;
14、步骤s22、确定期望滚转角与现时滚转角的滚转差值,以及确定期望速度与现时速度的速度差值;
15、步骤s23、当所述滚转角差值在设定的滚转动作空间内时,计算滚转角改变量,对应的,当所述速度差值在设定的速度动作空间内,计算速度改变量;
16、步骤s24、在每个控制周期内,在设定的飞行滚转角范围内及设定的飞行速度范围内,根据滚转角改变量与速度改变量控制僚机的飞行姿态。
17、优选的是,步骤s3中,所述回报函数为成本函数的负函数,所述成本函数被设定为选取第一参数及第二参数的最大值,其中,所述第一参数为僚机到所述环形区域的距离,所述第二参数为由僚机与长机的航向角差值、僚机到所述环形区域的距离、调整因子及所述环形区域的内半径构成的关系式,当僚机与长机过远或过近时,通过所述第一参数将两机之间的距离调整至期望区间;当僚机进入环形区域或接近环形区域时,通过所述第二参数对齐僚机与长机的航向。
18、优选的是,步骤s4中,所述协同控制策略算法包括但不限于:深度确定性策略梯度算法以及其改进型多智能体深度确定性策略梯度算法。
19、优选的是,当采用改进型多智能体深度确定性策略梯度算法时,在僚机的每一次状态更新后,对每个僚机的智能体分别更新critic网络及actor网络,其中,所述actor网络被配置为从环境中获取状态观测值o,并执行动作a反馈给环境,所述critic网络被配置为能够获取其余所有僚机智能体反馈给环境的动作信息。
20、本申请的基于强化学习的编队控制策略,采用强化学习的理论与方法,通过选取合理的控制参量、设计合理的回报函数,可实现编队协同策略的不断训练与优化,经某型号飞机仿真验证,可达到协同控制预期效果,有效提升多机编队的任务完成率。
技术特征:
1.一种基于强化学习的多机编队协同控制策略优化方法,其特征在于,包括:
2.如权利要求1所述的基于强化学习的多机编队协同控制策略优化方法,其特征在于,步骤s1进一步包括:
3.如权利要求2所述的基于强化学习的多机编队协同控制策略优化方法,其特征在于,步骤s1中,所述僚机飞行状态参数包括僚机的坐标值、僚机的航向角、僚机的滚转角及僚机的飞行速度,所述长机飞行状态参数包括长机的坐标值,长机的航向角、长机的滚转角及长机的飞行速度,所述系统联合状态参数至少包括僚机相对于长机的平面位置、航向角只差、长机的期望滚转角、长机的期望速度。
4.如权利要求1所述的基于强化学习的多机编队协同控制策略优化方法,其特征在于,步骤s2中,所述控制参量变化范围包括但不限于:俯仰角变化范围、偏航角变化范围、滚转角变化范围以及飞行速度变化范围。
5.如权利要求1所述的基于强化学习的多机编队协同控制策略优化方法,其特征在于,步骤s2中,确定所述控制指令包括:
6.如权利要求1所述的基于强化学习的多机编队协同控制策略优化方法,其特征在于,步骤s3中,所述回报函数为成本函数的负函数,所述成本函数被设定为选取第一参数及第二参数的最大值,其中,所述第一参数为僚机到所述环形区域的距离,所述第二参数为由僚机与长机的航向角差值、僚机到所述环形区域的距离、调整因子及所述环形区域的内半径构成的关系式,当僚机与长机过远或过近时,通过所述第一参数将两机之间的距离调整至期望区间;当僚机进入环形区域或接近环形区域时,通过所述第二参数对齐僚机与长机的航向。
7.如权利要求1所述的基于强化学习的多机编队协同控制策略优化方法,其特征在于,步骤s4中,所述协同控制策略算法包括但不限于:深度确定性策略梯度算法以及其改进型多智能体深度确定性策略梯度算法。
8.如权利要求7所述的基于强化学习的多机编队协同控制策略优化方法,其特征在于,当采用改进型多智能体深度确定性策略梯度算法时,在僚机的每一次状态更新后,对每个僚机的智能体分别更新critic网络及actor网络,其中,所述actor网络被配置为从环境中获取状态观测值o,并执行动作a反馈给环境,所述critic网络被配置为能够获取其余所有僚机智能体反馈给环境的动作信息。
技术总结
本申请属于飞机控制技术领域,特别涉及一种基于强化学习的多机编队协同控制策略优化方法。该方法包括步骤S1、确定由僚机及长机组成的拓扑编队的系统联合状态参数;步骤S2、根据所述联合状态参数中的僚机期望控制值,在设定的动作空间给定的各控制参量变化范围内,确定每个控制周期内的僚机的控制指令;步骤S3、基于所述控制指令控制各僚机动作,并计算由以长机为中心形成的用于表示僚机期望飞行空间的环形区域的参数构成的回报函数;步骤S4、以所述回报函数最大为优化目标对僚机的协同控制策略算法进行训练及优化。本申请能够实现编队协同策略的不断训练与优化,能够达到协同控制预期效果,有效提升了多机编队的任务完成率。
技术研发人员:赵跃明,黑文静,张菁华,吴佳驹,周洲
受保护的技术使用者:中国航空工业集团公司西安飞机设计研究所
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!