一种基于深度Q学习的高超声速飞行器控制参数优化方法
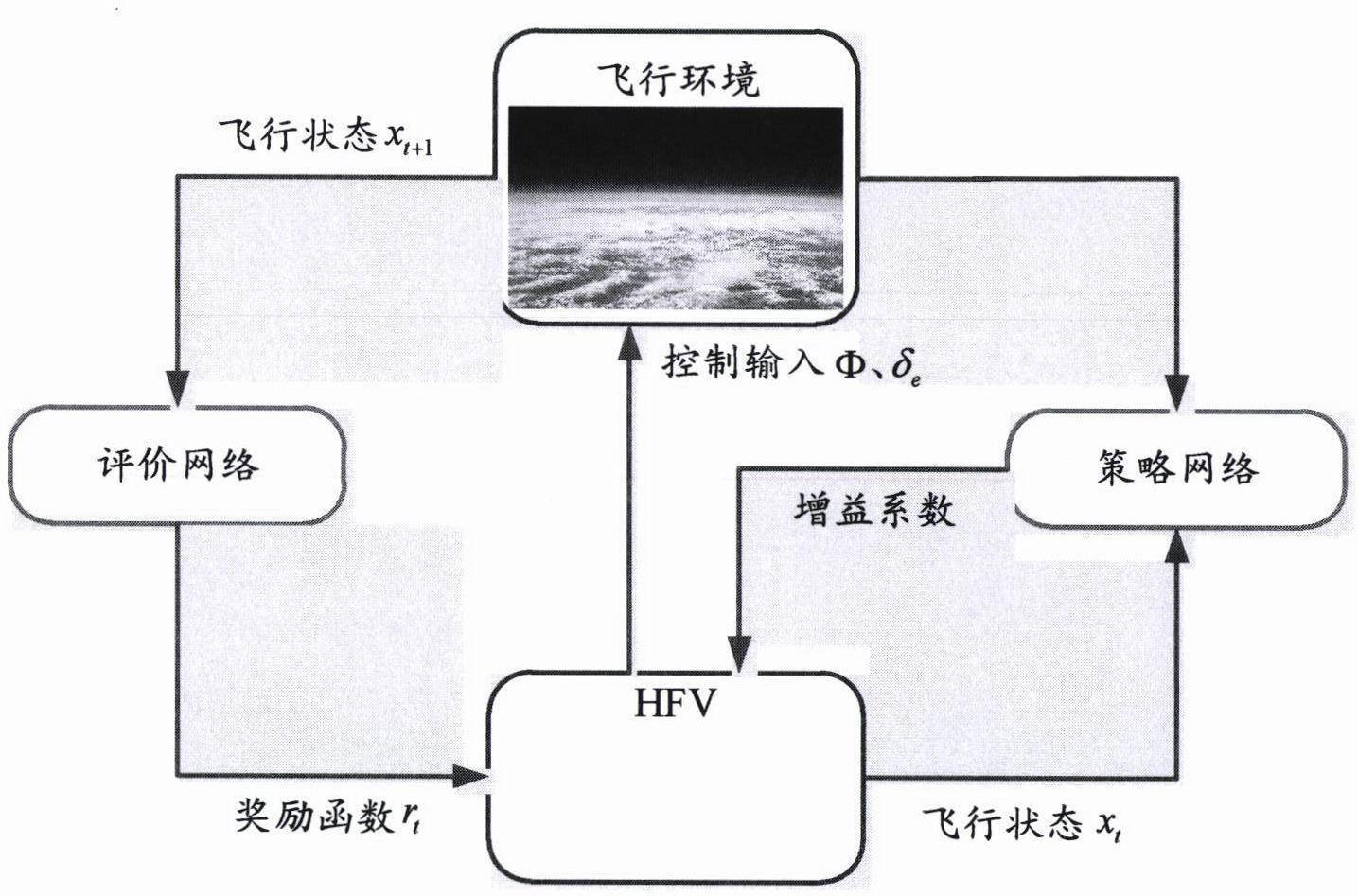
本发明涉及飞控参数优化方法,具体涉及一种基于深度q网络的高超声速飞行器的控制参数优化方法。
背景技术:
1、深度q网络(deep q-network,dqn)是一种人工智能算法,因其便于使用近年来受到广泛推崇。高超声速飞行器的控制器的参数设置对于控制性能甚至系统稳定性都有很大影响,因此,利用智能算法对高超声速飞行器的控制器进行参数优化有良好的应用前景。
2、传统的高超声速飞行器优化方法(k.gao,j.song,x.wang,and h.li,“fractional-order proportional-integral-derivative linear active disturbancerejection control design and parameter optimization for hypersonic vehicleswith actuator faults,”tsinghua science and technology,vol.26,no.1,pp.9-23,feb.2021.)虽能利用频域分析法实现参数优化,但每次只能优化一个工作点上的参数,高超声速飞行器的飞行包线跨域大,因此此类方法缺乏智能性。现有技术中的高超声速飞行器参数调整方法(一种高超声速飞行器专家智能控制方法及飞行器,cn201910547381.8)首先构建专家系统,在专家系统中预先建立高超声速飞行器的实时变形状态与pid控制器的控制参数的对应关系,在飞行过程中根据高超声速飞行器的状态调整控制参数。这是一种依赖规则的调参方法,虽具有一定的智能性,但在调参过程中缺乏自主能力。
3、高超声速飞行器的飞行包线大,飞行速度和飞行高度范围跨度大,相比于传统飞行器而言,其面临的飞行环境更加复杂多变。设计一种有效的控制参数优化方法,对于控制器性能的提升十分重要。
技术实现思路
1、针对现有技术存在的问题,本发明提供一种基于深度q学习的高超声速飞行器控制参数优化方法,具体步骤如下:
2、步骤1:建立如下高超声速飞行器动力学模型:
3、
4、式中:m,iyy,g分别为飞行器的质量、转动惯量和重力加速度;v,h,γ,α,θ,q分别为速度、高度、航迹角、攻角,俯仰角和俯仰角速度,且有α=θ-γ;分别为速度、高度、航迹角、俯仰角、俯仰角速度和弹性状态的导数;为弹性状态,η1、η2分别为第一阶弹性状态和第二阶弹性状态,分别为第一阶弹性状态和第二阶弹性状态的导数;是第i阶弹性状态的二阶导数;ζi,ωi,分别为弹性模态坐标的阻尼和自然振动频率;t、d、l、m、iyy、ni分别是推力、阻力、升力、俯仰力矩、转动惯量和第i阶广义力;
5、设置高超声速飞行器初始状态和参考信号;
6、步骤2:将高超声速飞行器动力学模型(1)分解为速度子系统(2)和高度子系统(3):
7、
8、
9、式中:fv、φ、dv、dh、fγ、dγ、fα、dα、fq、δe、dq分别为子系统函数、燃油当量比、速度扰动、迎角的导数、高度扰动、航迹角子系统函数、航迹角扰动、迎角子系统函数、迎角扰动、俯仰角速度子系统函数、升降舵偏角、俯仰角速度扰动,vγ表示两个参数相乘的关系;
10、步骤3:设计速度子系统自适应控制器:
11、
12、
13、式中:φ、kv、分别是燃油当量比、速度控制器参数、速度自适应参数和速度自适应参数的导数,ev=v-vref是速度跟踪误差,ev是时间t的函数,t1是飞行时间,vref是速度参考信号;tv>o是设计参数,kv>0将通过深度q学习网络训练得出;一致连续有界函数τ(t)满足:
14、
15、式中:τ1>0,τ2>o为设计参数,是函数τ(t)的导数;
16、步骤4:设计高度子系统自适应控制器:
17、
18、
19、式中:χγ、χα、χq、δe分别是航迹角虚拟控制律、迎角虚拟控制律、俯仰角速度虚拟控制律、升降舵偏角,ah、aγ、bγ、aα、bα、aq、bq、分别是高度控制器参数、航迹角控制器第一个参数、航迹角控制器第二个参数、航迹角自适应参数、航迹角自适应参数的导数、迎角控制器第一个参数、迎角控制器第二个参数、迎角自适应参数、迎角自适应参数的导数、俯仰角速度控制器第一个参数、俯仰角速度控制器第二个参数、俯仰角速度自适应参数、俯仰角速度自适应参数的导数;ah、aγ、aα、aq将通过深度q学习确定;eh=h-href是高度跟踪误差,href为高度参考信号,是高度参考信号的导数,eγ=γ-χγ是航迹角跟踪误差,eα=α-χα是迎角跟踪误差,eq=q-χq是俯仰角速度跟踪误差;
20、步骤5:利用深度q学习理论优化步骤3和步骤4中的设计参数ah、aγ、aα、aq,设计奖励函数:
21、r=-wv|ev|-wh|eh|-wφφ-we1|δδe|-we2|δe| (9)
22、式中:wv,wh,wφ,we1,we2均为权重参数,δδe、δe分别为升降舵偏角的变化量和升降舵偏角的大小。
23、本发明提出的深度强化学习能够基于仿真得到的样本数据,通过和环境不断交互的方式不断探索不同控制参数下的控制性能。在训练完成后,可以得到一个由飞行环境和飞行状态至控制参数的映射,根据外界环境和自身状态自适应地调整控制器的参数,从而最大化发挥控制器性能。
24、本发明的优点在于:
25、传统的高超声速飞行器自适应控制器设计方法中,在控制器设计完成后,其增益系数是固定的,一定程度上限制了控制器的性能。为了最大化发挥控制器性能,本发明提出一种适应飞行环境和飞行状态变化的参数动态优化/参数自适应方法,提高了控制器的效能。该方法可根据使用者的需要,设计奖励函数,动态地优化高超声速飞行器的控制器的参数,能够保证控制系统发挥最大效能。
技术特征:
1.一种基于深度q学习的高超声速飞行器控制参数优化方法,其特征在于,具体步骤如下:
技术总结
提供一种基于深度Q网络的高超声速飞行器的控制参数优化方法,该方法包括下列步骤:建立如下高超声速飞行器动力学模型;将高超声速飞行器动力学模型分解为速度子系统和高度子系统;设计速度子系统自适应控制器;设计高度子系统自适应控制器;利用深度Q学习理论优化步骤3和步骤4中的设计参数a<subgt;h</subgt;、a<subgt;γ</subgt;、a<subgt;α</subgt;、a<subgt;Q</subgt;,设计奖励函数。本发明可根据使用者的需要,设计奖励函数,动态地优化高超声速飞行器的控制器的参数,能够保证控制系统发挥最大效能。
技术研发人员:吕茂隆,董泽洪,沈堤,苟新禹,万路军,余付平,毛东辉
受保护的技术使用者:中国人民解放军空军工程大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!