一种基于强化学习的飞行器控制方法
本发明涉及自动控制与强化学习,特别是一种基于强化学习的飞行器控制方法。
背景技术:
1、自动驾驶仪是飞行制导,控制不可缺少的部件,核心作用是保证飞行器精确、稳定的跟踪制导系统生成的指令信号,使飞行器根据指令信号产生相应的控制力和力矩,从而让飞行器稳定飞行至目标点。自动驾驶仪可以增加飞行器阻尼,保持系统稳定性,加快飞行器响应速度,提高飞行器抗干扰能力,并且能精确、快速的跟踪输入指令。目前应用最广泛的为过载自动驾驶仪,跟踪信号为过载信号。
2、现有基于经典控制方法的过载自动驾驶仪,由于在设计过程中使用小扰动,线性化等方法来辅助完成设计,使得设计结果在面对大攻角改变等情形时,效果并不理想。并且基于反馈的调节方式,并不能第一时间给出较好解,积分初值往往难以选取。经典设计方法存在以下问题:(1)过多的依赖设计者的设计经验,尝试性强;(2)设计过程繁琐,尤其处理多输入多输出的系统时更加难以设计,难以完全的掌握系统的性能;(3)基于选取特征点的设计方式,无法全盘考虑控制系统性能,可能造成一些情况下调节误差较大。
3、为了克服以上问题,科研人员做了相关研究,提出了基于强化学习的控制方式,例如专利cn111708378a提出了一种基于强化学习的飞行器纵向姿态控制算法,该算法不基于反馈,只由当前状态来跟踪所过载信号,根据当前的每一时刻的状态和所需要跟踪的过载给出跟踪指令。张皓涵等公开了论文“基于强化学习的非线性主动悬架系统的最优控制”,主要提出了用强化学习算法来求解现代控制hjb方程,该方法的设计破解了hjb方程求解困难等问题,在现代控制求解上取得了一定进展。张启航等公开了论文“基于强化学习的燃气轮机转速控制策略研究”,主要是通过强化学习来代替人工调节pid参数,大大节省了人工调节的时间,提高了精度,但本质上还是在用经典pid控制来解决问题,该方法通过大量训练,一定程度上提高了pid控制的精度。
4、然而,目前强化学习在控制方法上的应用还存在以下问题:一是通过强化学习来调整经典控制律参数,性能较经典控制有所提升,但奖惩指标无法很好设计,依赖于对模型的精确建立;二是利用强化学习在线的求解最优控制律,性能有较大提升,但稳定性有所下降,并且强化学习难以收敛,控制系统设计者往往需要添加额外设计来保证强化学习收敛;三是利用强化学习进行端到端的控制律设计,根据反馈的偏差量求解下一步动作,该种设计方法较难收敛,并且鲁棒性较差。
技术实现思路
1、本发明的目的在于提供一种设计合理、稳定性高、鲁棒性好的基于强化学习的飞行器控制方法,以更好的适应飞行器飞行过程中遇到强干扰、大攻角改变等情形,且控制效果得到较好提升。
2、实现本发明目的的技术解决方案为:一种基于强化学习的飞行器控制方法,包括以下步骤:
3、步骤1、根据飞行动力学,建立飞行器运动环境,并根据控制目标设计控制性能验证指标;
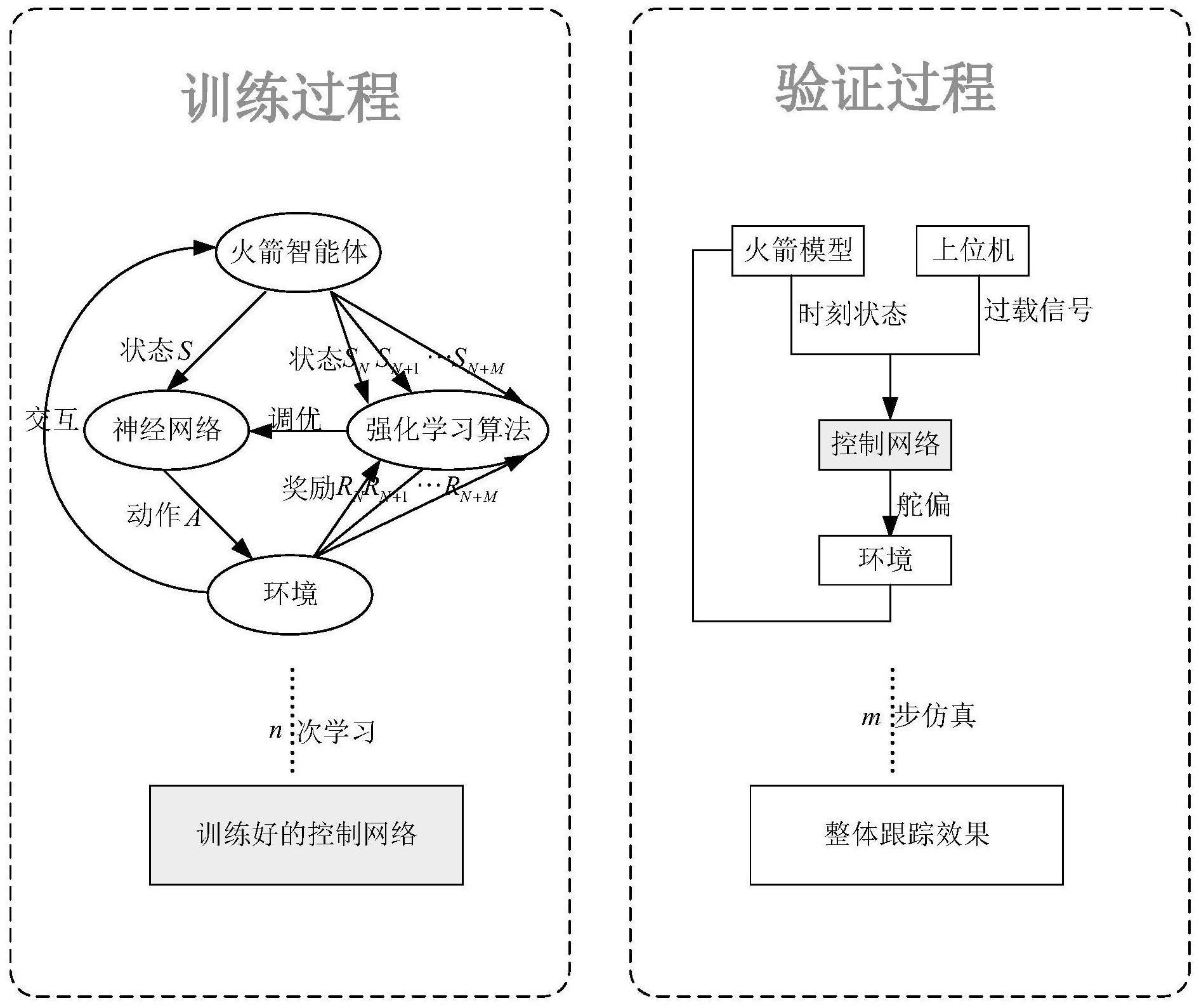
4、步骤2、根据飞行器运动环境建立马尔可夫决策过程,构建智能控制方式,将控制过程转化为决策过程,搭建强化学习环境,通过神经网络来拟合控制目标与相关自变量关系,在不同的飞行器飞行状态下给出最优解;
5、步骤3、根据设计的强化学习环境,选择强化学习算法并构建状态空间、动作空间和奖惩函数,然后进行归一化;
6、步骤4、根据强化学习算法,设计训练空间,预设控制指令空间并进行训练;
7、步骤5、在步骤4训练完成后,根据控制律设计需求,设计基于经典控制的三回路过载驾驶仪,在不同时间段跟踪不同的阶跃过载,并且通过控制性能验证指标来比对性能差异。
8、本发明与现有技术相比,其显著优点在于:(1)通过强化学习算法来拟合数据间关系,形成系统状态与控制动作的函数映射。保证了数据的有效性,降低了驾驶仪的设计难度,较经典控制驾驶仪,在快速性和稳定性上有了较大的提高;(2)通过将飞行控制过程转化为马尔可夫决策过程,大大提高了控制快速性;(3)通过设定状态反馈,将飞行器的五个状态作为反馈设计,提高了控制性能的鲁棒性;(4)通过对仿真环境的选取,极大的保留了数据的真实性,使得在相同状态下,本方法设计的驾驶仪具有更好的准确性;(5)将算法应用到飞行器真实飞行环境,验证了该算法设计的驾驶仪的可行性。
技术特征:
1.一种基于强化学习的飞行器控制方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤1中,控制性能验证指标的设计具体如下:设计三种控制性能验证指标,分别为启控时间到达第一次跟踪上信号的过渡时间、在该时间内与控制量的偏差和、第一次跟踪上信号时间后保持在跟踪信号±5%范围内的维系时间。
3.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤2中智能控制方式为:根据实际情况,选择控制机构为舵机,控制指令信号为纵向过载,采取端到端的控制方式,通过当前的火箭状态和过载指令直接给出当前的舵偏值,使用预设多种过载指令的做法,不断地通过尝试拟合预设指令与舵偏之间的关系,并通过真实的仿真环境训练,得到当前状态及连续状态下,在预设控制指令下得到的一系列最优舵偏值,其中没有预设的指令,通过拟合后的神经网络自动给出,根据过载和状态关系,设计马尔可夫决策过程,并同时设计奖励函数。
4.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤3中的强化学习算法为:
5.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤2中所述将控制过程转化为决策过程,具体如下:
6.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤4所述根据强化学习算法,设计训练空间,预设控制指令空间并进行训练,具体如下:
7.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤3中奖惩函数具体如下:
8.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤3中构建状态空间,具体如下:
9.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤3中的归一化具体如下:
10.根据权利要求1所述的基于强化学习的飞行器控制方法,其特征在于,步骤4中预设控制指令空间,具体为:
技术总结
本发明公开了一种基于强化学习的飞行器控制方法,具体为:建立飞行器运动环境,并根据控制目标设计控制性能验证指标;建立马尔可夫决策过程,构建智能控制方式,将控制过程转化为决策过程,搭建强化学习环境,通过神经网络来拟合控制目标与相关自变量关系,在不同的飞行器飞行状态下给出最优解;选择强化学习算法并构建状态空间、动作空间和奖惩函数,进行归一化;设计训练空间,预设控制指令空间并进行训练;根据控制律设计需求,设计基于经典控制的三回路过载驾驶仪,在不同时间段跟踪不同的阶跃过载,并且通过控制性能验证指标来比对性能差异。本发明可以更好的适应飞行器飞行过程中遇到强干扰、大攻角改变等情形,控制效果得到较高提升。
技术研发人员:白宏阳,赵大想,孙瑞胜,薛帅,曹宇
受保护的技术使用者:南京理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!