基于可控运动模式强化学习的四足机器人优化和控制方法
本发明属于机器人领域,特别涉及一种基于可控运动模式强化学习的四足机器人优化和控制方法。
背景技术:
1、强化学习作为机器学习的一个关键分支,已经在多个应用场景中显示出其潜力和有效性,尤其是在处理需要实时决策和自适应性的复杂任务时。尽管rl在诸如游戏、自动驾驶、能源管理以及最重要的机器人控制等领域取得了显著成就,但其在实际应用中仍面临一些挑战。
2、奖励工程的复杂性:在rl中,奖励函数的设计是驱动代理学习的核心。特别是对于四足或多足机器人,需要精确的奖励设计来引导其完成复杂的运动任务,如行走、跑步或跳跃。这些奖励函数必须能够反映机器人的运动目标,同时确保其动作的安全性、稳定性和能效。然而,创建一个既能促进高性能又不引起不利行为的奖励函数是极具挑战性的。过于简单或过于复杂的奖励设置都可能导致非预期的学习结果或不稳定的行为模式。
3、权重配置的挑战:在多目标优化场景中,如何平衡不同奖励项的权重成为一个关键问题。这些权重的配置通常需要大量的实验和专家经验。在有腿机器人的场景中,权重不仅需要反映任务的主要目标,还需要考虑到机器人的物理限制和性能要求,如能源效率、响应速度和抗干扰能力。缺乏一个系统的方法来评估和调整这些权重,使得机器人难以在不同的环境和任务要求下灵活适应。
4、适应性和灵活性的需求:现实世界的环境变化多端,机器人可能需要在各种地形和情况下操作。这就需要机器人不仅要有稳定和高效的运动能力,还要能根据环境的变化调整其行为。传统的rl方法通常在这方面存在局限性,因为它们倾向于在特定的任务和环境中优化机器人的表现,而不是提供一种通用的解决方案。
技术实现思路
1、本发明旨在提供一种基于可控运动模式强化学习的四足机器人优化和控制方法,通过深度强化学习策略,显著优化和控制四足机器人在不同环境和任务条件下的运动模式。关键在于,本发明能够充分探索复杂的奖励结构,通过权重的探索和最优权重的求解,实现对机器人行为的精细控制,从而满足多样化的实际应用需求。此外,本方法旨在通过创新的技术方案,大幅提升机器人在复杂环境中的适应性和灵活性,确保其在各种情况下都能保持高效和稳定的性能。
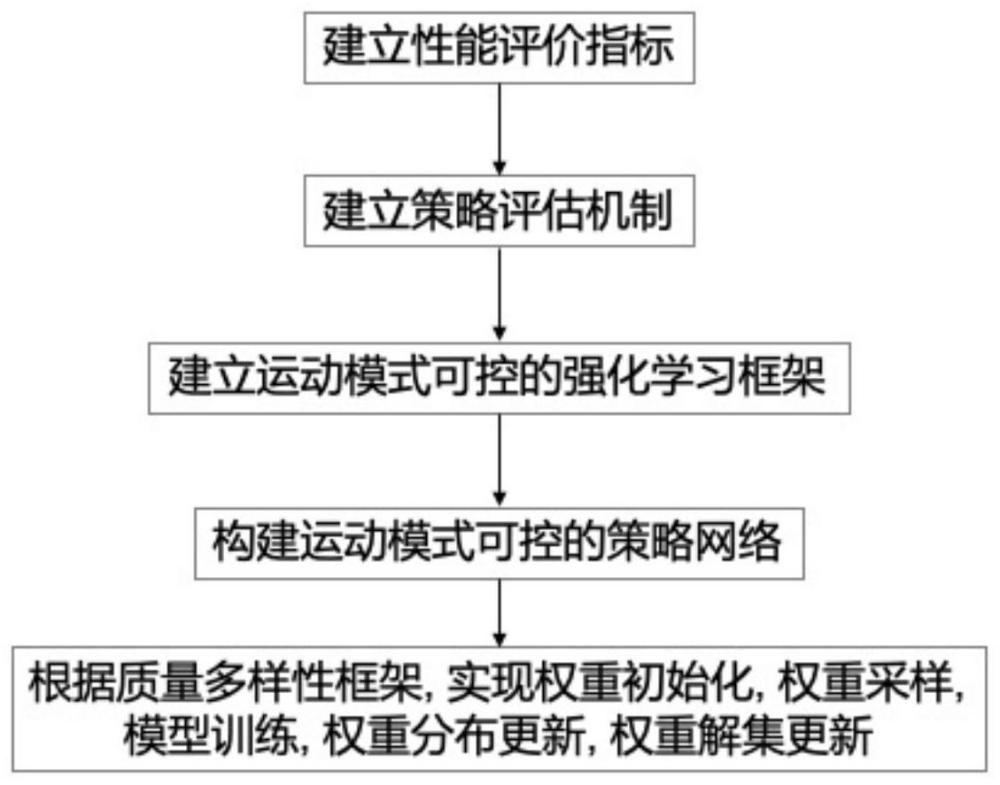
2、本发明的技术方案是,一种基于可控运动模式强化学习的四足机器人优化和控制方法,其包括以下步骤:
3、s1、建立性能评价指标;
4、s2、建立基于机器人动力学和运动学的控制策略评价机制,建立策略集合评价机制;
5、s3、建立运动模式可控的强化学习框架,针对不同机器人和评价指标建立优化问题;
6、s4、建立运动模式可控的策略网络,通过额外奖励权重输入控制策略的运动模式;
7、s5、建立质量-多样性控制策略训练框架,通过性能提升和新奇搜索的方式找到最优的奖励权重和策略。
8、本发明的进一步改进在于,步骤s1中建立策略评价指标过程中,建立有关足式机器人的多个性能指标,包括指令遵循性、能量效率和步态可变性。
9、本发明的进一步改进在于,步骤s2包括:
10、控制策略通过多个性能指标进行比较,使用多目标优化方法比较评价结果,得到控制策略间支配关系,最终得到非支配的帕累托前沿策略集。
11、本发明的进一步改进在于,步骤s3包括:
12、建立状态空间,动作空间,奖励函数,转移方程;额外引入的奖励函数权重空间,允许通过量化的方式比较和选择奖励权重;
13、优化目标:得到最优奖励权重集合,以及对应控制策略,不同的奖励权重的控制策略用于不同的性能指标,即表现为多样的运动模式。
14、本发明的进一步改进在于,步骤s4中构建允许额外奖励权重输入的运动模式可控的策略网络包括
15、可控运动模式的策略:由预训练专家测策略,零线性层,专家拷贝模块。
16、可控运动模式的网络架构通过接收额外的奖励权重输入,以及使用预训练专家测策略,实现对机器人运动模式的精确控制。
17、本发明的进一步改进在于,步骤s5中建立质量-多样性控制策略训练框架的过程包括:
18、建立质量-多样性控制策略训练框架的过程包括:建立指标空间,解集的初始化;奖励权重的采样和更新;可控策略的学习和评估;解集的更新;
19、初始化包括:将指标空间栅格化,每个区域储存奖励权重和对应评估指标;
20、奖励权重的采样和更新:每个区域中的采样权重建模为多变量高斯分布;使用性能和新奇搜索更新区域内采样分布;
21、学习和评估:使用无模型强化学习更新策略,评估不同奖励权重下的指标;
22、解集更新:保留每个区域内的指标的局部帕累托前沿和对应的权重。
23、本发明的有益效果为:本发明的方法能够充分探索复杂的奖励结构,通过权重的探索和最优权重的求解,实现对机器人行为的精细控制,从而满足多样化的实际应用需求。此外,本方法旨在通过创新的技术方案,大幅提升机器人在复杂环境中的适应性和灵活性,确保其在各种情况下都能保持高效和稳定的性能。
技术特征:
1.一种基于可控运动模式强化学习的四足机器人优化和控制方法,其特征在于包括以下步骤:
2.根据权利要求1所述的一种基于可控运动模式强化学习的四足机器人优化和控制方法,其特征在于,步骤s1中建立策略评价指标过程中,建立有关足式机器人的多个性能指标,包括指令遵循性、能量效率和步态可变性。
3.根据权利要求2所述的一种基于可控运动模式强化学习的四足机器人优化和控制方法,其特征在于,步骤s2包括:
4.根据权利要求3所述的一种基于可控运动模式强化学习的四足机器人优化和控制方法,其特征在于,步骤s3包括:
5.根据权利要求4所述的一种基于可控运动模式强化学习的四足机器人优化和控制方法,其特征在于,步骤s4中构建允许额外奖励权重输入的运动模式可控的策略网络包括:
6.根据权利要求5所述的一种基于可控运动模式强化学习的四足机器人优化和控制方法,其特征在于,步骤s5中建立质量-多样性控制策略训练框架的过程包括:
技术总结
本发明公开了一种基于可控运动模式强化学习的四足机器人优化和控制方法,其包括以下步骤:S1、建立性能评价指标;S2、建立基于机器人动力学和运动学的控制策略评价机制,建立策略集合评价机制;S3、建立运动模式可控的强化学习框架,针对不同机器人和评价指标建立优化问题;S4、建立运动模式可控的策略网络,通过额外奖励权重输入控制策略的运动模式;S5、建立质量‑多样性控制策略训练框架,通过性能提升和新奇搜索的方式找到最优的奖励权重和策略。本发明的方法能够充分探索复杂的奖励结构,通过权重的探索和最优权重的求解,实现对机器人行为的精细控制,从而满足多样化的实际应用需求。
技术研发人员:高岳,高峰,季经天
受保护的技术使用者:上海交通大学
技术研发日:
技术公布日:2024/5/16
- 还没有人留言评论。精彩留言会获得点赞!