一种履带式机器人轨迹跟踪控制方法、装置及相关设备
本申请涉及轨迹跟踪,更具体地说,是涉及一种履带式机器人轨迹跟踪控制方法、装置及相关设备。
背景技术:
1、履带式机器人指搭载履带底盘机构的机器人,其具有牵引力大、不易打滑、越野性能好等优点,凭借其在复杂地形中的优越机动性、穿越性以及有效载荷承载能力而被广泛应用于各个领域。
2、强化学习(reinforcement learning,rl)是机器学习中的一类问题,其智能体通过试错法与环境进行交互,因其行为而获得奖励,这一运行机制类似于人类的学习方式,引导智能体以改进未来的决策,从而最大化即将到来的奖励。
3、如何将强化学习应用于履带式机器人领域,以实现其轨迹跟踪控制,对于实现机器人智能化和自主化具有重要的应用价值。
技术实现思路
1、有鉴于此,本申请提供了一种履带式机器人轨迹跟踪控制方法、装置及相关设备,以实现对履带式机器人的轨迹跟踪控制。
2、为实现上述目的,本申请第一方面提供了一种履带式机器人轨迹跟踪控制方法,包括:
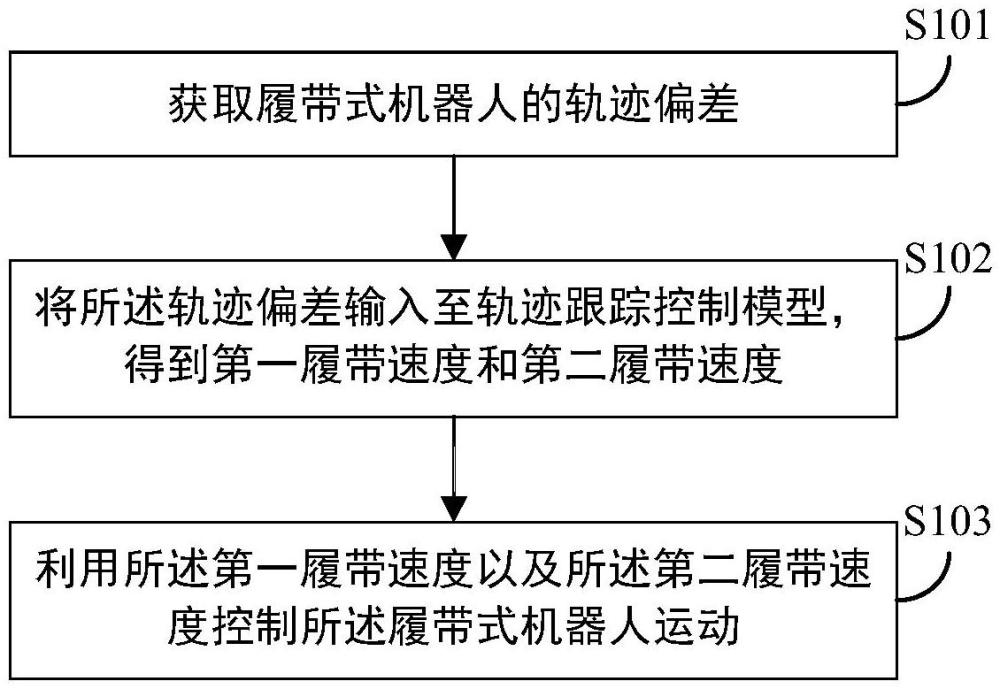
3、获取履带式机器人的轨迹偏差,所述轨迹偏差包括纵向距离偏差、横向距离偏差以及航向角偏差;
4、将所述轨迹偏差输入至轨迹跟踪控制模型,得到第一履带速度和第二履带速度,所述轨迹跟踪控制模型为以双延迟深度确定性策略梯度算法td3作为更新算法,在预设的训练环境中训练得到的,所述训练环境包括履带式机器人的运动学模型、目标轨迹模型和奖励函数;
5、利用所述第一履带速度以及所述第二履带速度控制所述履带式机器人运动。
6、优选地,所述轨迹跟踪控制模型包括策略网络和价值网络;
7、所述策略网络和所述价值网络均包括输入层、第一隐藏层、第二隐藏层以及输出层;
8、所述策略网络的输入层包括分别对应于纵向距离偏差、横向距离偏差以及航向角偏差的3个神经元;
9、所述策略网络的第一隐藏层、第二隐藏层均包括64个神经元,并均采用relu函数作为激活函数;
10、所述策略网络的输出层包括2个神经元,并通过tanh函数将输出限定在[-1,1];
11、所述价值网络的输入层包括分别对应于纵向距离偏差、横向距离偏差、航向角偏差、第一履带速度以及第二履带速度的5个神经元;
12、所述价值网络的第一隐藏层、第二隐藏层均包括64个神经元,并均采用relu函数作为激活函数;
13、所述价值网络的输出层包括1个神经元,用于评估所述策略网络的输出。
14、优选地,所述运动学模型表示为下述方程:
15、
16、其中,表示纵向距离偏差,表示横向距离偏差,表示航向角偏差,a表示单侧履带与几何中心的距离,r表示转向中心与质心的距离,α表示速度与纵向速度的夹角,cy表示质心处的纵向坐标,θ表示期望轨迹与实际轨迹的航向角,vl表示第一履带速度,vr表示第二履带速度。
17、优选地,所述奖励函数包括针对距离偏差的第一分段函数以及针对航向角偏差的第二分段函数。
18、优选地,所述奖励函数的奖励值由第一分段函数的奖励值与第二分段函数的奖励值通过等权重线性叠加的方式计算得到。
19、优选地,所述第一分段函数表示为下述方程:
20、
21、其中,reward1表示所述第一分段函数的奖励值,es表示距离偏差,表示为下述方程:
22、
23、其中,ex表示横向距离偏差,ey表示纵向距离偏差。
24、优选地,所述第二分段函数表示为下述方程:
25、
26、其中,reward2表示所述第二分段函数的奖励值,eθ表示航向角偏差。
27、本申请第二方面提供了一种履带式机器人轨迹跟踪控制装置,包括:
28、数据获取单元,用于获取履带式机器人的轨迹偏差,所述轨迹偏差包括纵向距离偏差、横向距离偏差以及航向角偏差;
29、数据推理单元,用于将所述轨迹偏差输入至轨迹跟踪控制模型,得到第一履带速度和第二履带速度,所述轨迹跟踪控制模型为以双延迟深度确定性策略梯度算法td3作为更新算法,在预设的训练环境中训练得到的,所述训练环境包括履带式机器人的运动学模型、目标轨迹模型和奖励函数;
30、跟踪控制单元,用于利用所述第一履带速度以及所述第二履带速度控制所述履带式机器人运动。
31、本申请第三方面提供了一种履带式机器人轨迹跟踪控制设备,包括:存储器和处理器;
32、所述存储器,用于存储程序;
33、所述处理器,用于执行所述程序,实现上述的履带式机器人轨迹跟踪控制方法的各个步骤。
34、本申请第四方面提供了一种存储介质,其上存储有计算机程序,所述计算机程序被处理器执行时,实现如上述的履带式机器人轨迹跟踪控制方法的各个步骤。
35、经由上述的技术方案可知,本申请首先获取履带式机器人的轨迹偏差,其中,所述轨迹偏差包括纵向距离偏差、横向距离偏差以及航向角偏差。可以理解,轨迹偏差可以观察得到的,反映了实际行驶路径与目标行驶路径之间的差距。然后,将所述轨迹偏差输入至轨迹跟踪控制模型,得到第一履带速度和第二履带速度。其中,所述轨迹跟踪控制模型为以td3作为更新算法,在预设的训练环境中训练得到的,所述训练环境包括履带式机器人的运动学模型、目标轨迹模型和奖励函数。最后,利用所述第一履带速度以及所述第二履带速度控制所述履带式机器人运动,以实现对履带式机器人的轨迹跟踪控制。本申请的轨迹跟踪控制模型在ddpg(deep deterministic policy gradient,深度确定性策略梯度)基础上引入双critic网络共同估计q值,缓解了q值过估计问题。同时,采用延迟更新actor网络策略,并对actor目标网络的输出添加高斯噪声,提高了算法的稳定性和收敛性。基于此,配合本申请针对履带式机器人而设置的运行模型、目标轨迹模型以及奖励函数,使得所述轨迹跟踪控制模型能以较少的训练片段完成训练,具有较优的收敛性。在利用所述轨迹跟踪控制模型对所述履带式机器人进行轨迹跟踪控制时,可以提高轨迹跟踪精度,且具有较高的轨迹跟踪稳定性。
技术特征:
1.一种履带式机器人轨迹跟踪控制方法,其特征在于,包括:
2.根据权利要求1所述的方法,其特征在于,所述轨迹跟踪控制模型包括策略网络和价值网络;
3.根据权利要求1所述的方法,其特征在于,所述运动学模型表示为下述方程:
4.根据权利要求1所述的方法,其特征在于,所述奖励函数包括针对距离偏差的第一分段函数以及针对航向角偏差的第二分段函数。
5.根据权利要求4所述的方法,其特征在于,所述奖励函数的奖励值由第一分段函数的奖励值与第二分段函数的奖励值通过等权重线性叠加的方式计算得到。
6.根据权利要求4所述的方法,其特征在于,所述第一分段函数表示为下述方程:
7.根据权利要求4所述的方法,其特征在于,所述第二分段函数表示为下述方程:
8.一种履带式机器人轨迹跟踪控制装置,其特征在于,包括:
9.一种履带式机器人轨迹跟踪控制设备,其特征在于,包括:存储器和处理器;
10.一种存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时,实现如权利要求1~7中任一项所述的履带式机器人轨迹跟踪控制方法的各个步骤。
技术总结
本申请公开了一种履带式机器人轨迹跟踪控制方法、装置及相关设备,所述方法包括:获取履带式机器人的轨迹偏差,其包括纵向距离偏差、横向距离偏差以及航向角偏差;将轨迹偏差输入至轨迹跟踪控制模型,得到第一履带速度和第二履带速度,所述轨迹跟踪控制模型为以双延迟深度确定性策略梯度算法TD3作为更新算法,在预设的训练环境中训练得到的,所述训练环境包括履带式机器人的运动学模型、目标轨迹模型和奖励函数;利用所述第一履带速度以及所述第二履带速度控制所述履带式机器人运动。所述轨迹跟踪模型在训练中具有较优的收敛性,在利用其对履带式机器人进行轨迹跟踪控制时,可以提高轨迹跟踪精度,且具有较高的轨迹跟踪稳定性。
技术研发人员:王海龙,邓聪,翁卫玉,陈新度
受保护的技术使用者:广东工业大学
技术研发日:
技术公布日:2024/10/17
- 还没有人留言评论。精彩留言会获得点赞!