一种快速的新闻文本内容情感分析系统及方法与流程
本发明涉及一种新闻资讯领域,具体涉及一种快速的新闻文本内容情感分析系统及方法。
背景技术:
随着互联网的快速发展,网络舆情对社会的影响力越来越大。不管是政府网络舆情监控的需要,还是企业在进行品牌传播及品牌公关的需要,如何在大量的舆情的条件下,快速地分析舆情的情感倾向,以及时地进行决策支持和舆情引导,响应快速变化的舆论环境,是舆情分析中迫切需要解决的问题。以往的情感分析,需要进行复杂的分析,在应对大量的舆情条件下,无法做到低延迟处理。
技术实现要素:
本发明的目的在于克服现有技术的不足,提供一种新闻用户情感分析系统,在面对大量舆情场景下,快速进行情感指数计算的方法。
本发明的目的是通过以下技术方案来实现的:
一种快速的新闻文本内容情感分析系统,包括以下模块:
新闻抓取模块:用于从新闻门户、论坛及微博上抓取新闻文档,其中包括对文本进行初步去重处理;
新闻文本初步处理模块:用于对文本进行初步文本特征处理,包括分词、去停用词、对否定式短语进行额外标注;
新闻文本情感计算模块:包括textrank计算、分词情感计算、对计算值进行归一化处理、综合计算得到文档的情感指数;
数据存储模块:存储计算后的结果。
一种快速的新闻文本内容情感分析方法,包括如下步骤:
s01:从互联网新闻门户、论坛及微博爬取新闻,对文本去重;
s02:抽取文本信息,主要是来源、作者、标题、正文等信息;
s03:对标题、正文进行分词,去掉停用词;
s04:使用textrank计算每个词的权重;
s05:同时根据情感词典,得到每个词的情感倾向及情感强度s;
s06:最后将词的权重与词的情感强度相乘,计算总和,进行归一化处理,从而得到文档的情感指数。
进一步的,所述的骤s04所述的使用textrank计算每个词的权重,具体包括
给标题的词语额外加权,加权算法为wt=n×wd,其中,wt表示标题分词,wd表示正文分词取值范围是[0,100]),n表示加权权重权重范围值是多少[2,10];
对分词进行词性过滤,只保留名词性和动词性分词;
使用textrank算法计算每个词的权重;
对计算结果进行归一化处理,归一化的计算方式为wt=wt/(max(wt)+1)。其中,wt表示有textrank计算的词权重,max(wt)表示该文档中最大的权重。
更进一步的,所述的步骤s06中根据分词计算文档的情感指数,具体计算方式为
sd=∑(wt×st)×c/n
其中,sd表示文档的情感指数,wt表示每个分词的权重,st表示每个分词的情感指数该指数值范围是[-100,100],c是一个常数范围值是多少[1,5],n表示该文档内,单词的数量
本发明的有益效果是:本发明只需经过简单的文本处理和计算就可以得到相应的情感指数分析结果,解决了在面对大量舆情条件下的低延迟处理。
附图说明
图1为本发明的系统结构示意图;
图2为本发明的方法流程图。
具体实施方式
下面结合附图进一步详细描述本发明的技术方案,但本发明的保护范围不局限于以下所述。
如图1所示,
一种快速的新闻文本内容情感分析系统,包括以下模块:
新闻抓取模块:用于从新闻门户、论坛及微博上抓取新闻文档,其中包括对文本进行初步去重处理;
新闻文本初步处理模块:用于对文本进行初步文本特征处理,包括分词、去停用词、对否定式短语进行额外标注;
新闻文本情感计算模块:包括textrank计算、分词情感计算、对计算值进行归一化处理、综合计算得到文档的情感指数;
数据存储模块:存储计算后的结果。
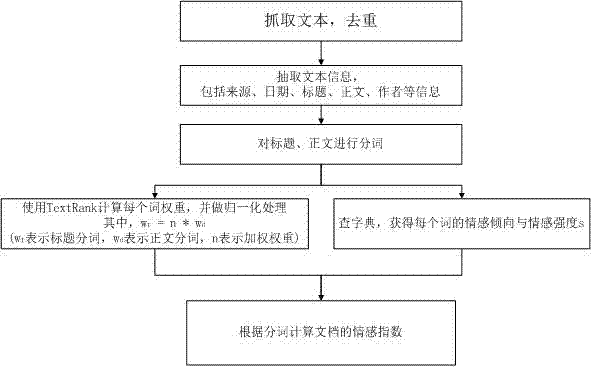
如图2所示:
一种快速的新闻文本内容情感分析方法,包括如下步骤:
s01:从互联网新闻门户、论坛及微博爬取新闻,对文本去重;
s02:抽取文本信息,主要是来源、作者、标题、正文等信息;
s03:对标题、正文进行分词,去掉停用词;
s04:使用textrank计算每个词的权重;
s05:同时根据情感词典,得到每个词的情感倾向及情感强度;
s06:最后将词的权重与词的情感强度相乘,计算总和,进行归一化处理,从而得到文档的情感指数。
具体的操作是首先抓取文本,去重处理,抽取文本信息,包括来源、日期、标题、正文、作者等信息,紧接着对标题、正文进行分词处理,然后从两方面进行处理;一是使用textrank计算每个词的权重,并做归一化处理,二是通过查字典,获得每个词的情感倾向与情感强度s(情感强度s的取值是如何的提高具体数值范围)。
所述的骤s04所述的使用textrank计算每个词的权重,具体包括
给标题的词语额外加权,加权算法为wt=n×wd,其中,wt表示标题分词,wd表示正文分词取值范围是[0,100],n表示加权权重权重范围值是[2,10];
对分词进行词性过滤,只保留名词性和动词性分词;
使用textrank算法计算每个词的权重;
对计算结果进行归一化处理,归一化的计算方式为wt=wt/(max(wt)+1)。其中,wt表示有textrank计算的词权重,max(wt)表示该文档中最大的权重。
所述的步骤s06中根据分词计算文档的情感指数,具体计算方式为
sd=∑(wt×st)×c/n
其中,sd表示文档的情感指数,wt表示每个分词的权重,st表示每个分词的情感指数该指数值范围是[-100,100],c是一个常数范围值是[1,5],n表示该文档内,单词的数量。
以上所述仅是本发明的优选实施方式,应当理解本发明并非局限于本文所披露的形式,不应看作是对其他实施例的排除,而可用于各种其他组合、修改和环境,并能够在本文所述构想范围内,通过上述教导或相关领域的技术或知识进行改动。而本领域人员所进行的改动和变化不脱离本发明的精神和范围,则都应在本发明所附权利要求的保护范围内。
技术特征:
技术总结
本发明公开了一种快速的新闻文本内容情感分析系统及方法包括以下模块:新闻抓取模块:用于从新闻门户、论坛及微博上抓取新闻文档,其中包括对文本进行初步去重处理;新闻文本初步处理模块:用于对文本进行初步文本特征处理,包括分词、去停用词、对否定式短语进行额外标注;新闻文本情感计算模块:包括TextRank计算、分词情感计算、对计算值进行归一化处理、综合计算得到文档的情感指数;数据存储模块:存储计算后的结果。本发明能在面对大量舆情场景下,快速进行情感指数计算。
技术研发人员:余军;卢品吟;刘盾;张汨
受保护的技术使用者:成都华栖云科技有限公司
技术研发日:2017.05.04
技术公布日:2017.08.15
- 还没有人留言评论。精彩留言会获得点赞!