一种针对网络文档的网络爬虫提取URL并索引及与关键词映射的框架的制作方法
本发明涉及一种针对网络文档的网络爬虫提取url并索引及与关键词映射的框架
背景技术:
目前搜索引擎只针对文本进行搜索,还不能有效对音乐、图片和视频等多媒体文件进行搜索,原因主要是多媒体数据量太大;如何索引多媒体文件;进而对处理过的多媒体文件检索。现在因特网上有大量的多媒体文件,特别是社交网站和多媒体分享的兴起,需要对多媒体文件进行精准检索。
网络爬虫,也称网络蜘蛛、网络机器人,是一个自动提取网页的程序,它从因特网上下载网页,是搜索引擎的重要组成部分。网络爬虫利用标准的http协议,根据超级链接和网络文档检索的方法遍历因特网信息空间。因特网上有数千种不同的数据类型,http给每种要通过网络传输的对象都打上了名为mime类型的数据格式标签。统一资源定位符(url)是资源标识符最常见的形式。url描述了一台特定服务器上某资源的特定位置。元素文件(metafile)可提供有关页面的元信息,如针对搜索引擎和更新频度的描述和关键词,可针对元素的关键词进行索引。
网络搜索的数据往往是高维的,其维数甚至达到百万数量级。发现和利用高维数据中的低维结构,在网络搜索中显得尤为重要。另外,在网络搜索中,人们只能观察到少量元素,希望根据这些有限的信息,能够猜测出未看到的大量元素,从而恢复一个未知的低秩矩阵或近似低秩矩阵。
假定已知数据已排列成一高维数据或样本矩阵。估计一低维子空间的问题称为低秩矩阵逼近。当低秩矩阵或样本矩阵的某些元素被严重损坏时,能够自动识别被损坏的元素,精确地恢复原低秩矩阵。在网络搜索中,需要将一个数据矩阵分解为一个低秩矩阵与一个稀疏矩阵之和,并且希望同时恢复低秩矩阵与稀疏矩阵。
本发明提供了一种针对网络文档的网络爬虫提取url并索引及与关键词映射的框架,可在适当增加数据量的前提下,通过metafile的关键词对url进行索引,并与相关关键词建立映射,利用关键词对网络文档进行语义检索。
技术实现要素:
本发明的目的在于提供一种针对网络文档的网络爬虫提取url并索引及与关键词映射的框架。本发明包括以下特征:
发明技术方案
1.一种针对网络文档的网络爬虫提取url并索引及与关键词映射的框架,其具体步骤如下:
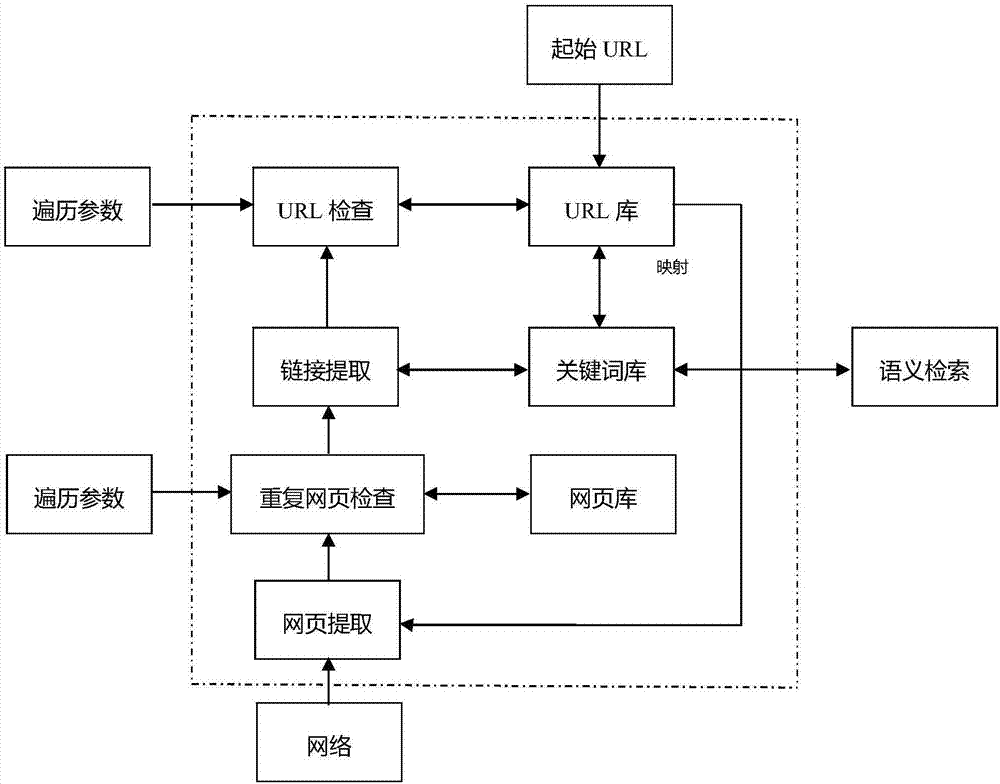
1)网络爬虫从遍历参数和起始url开始;
2)使用url库中的第一个url从网络上下载网页;
3)将其传递给重复网页检查,重复核查的准确性取决于具体的遍历参数;
4)如果网页没有被拒绝,则将它保存到网页库中;
5)并传递给链接提取;
6)链接提取从网页的metafile中提取链接,传递给url检查;如果之前访问过,或不符合遍历参数表中列出的标准,则拒绝下载;
7)同时提取关键词,传递给关键词库,以备语义检索;
8)将没有被拒绝的url进行索引,递给url库;并与相关关键词建立映射;
9)url库然后将一个未被访问的url传递给网页提取。
附图说明
图1是针对网络文档的网络爬虫提取url并索引及与关键词映射的框架图。
具体实施方式
这种针对网络文档的网络爬虫提取url并索引及与关键词映射的框架,包括如下步骤:
1)网络爬虫从遍历参数和起始url开始;
2)使用url库中的第一个url从网络上下载网页;
3)将其传递给重复网页检查,重复核查的准确性取决于具体的遍历参数;
4)如果网页没有被拒绝,则将它保存到网页库中;
5)并传递给链接提取;
6)链接提取从网页的metafile中提取链接,传递给url检查;如果之前访问过,或不符合遍历参数表中列出的标准,则拒绝下载;
7)同时提取关键词,传递给关键词库,以备语义检索;
8)将没有被拒绝的url进行索引,递给url库;并与相关关键词建立映射;
9)url库然后将一个未被访问的url传递给网页提取。
技术特征:
技术总结
本发明公开一种针对网络文档的网络爬虫提取URL并索引及与关键词映射的框架,可在适当增加数据量的前提下,通过METAFILE的关键词对URL进行索引,并与相关关键词建立映射,利用关键词对网络文档进行语义检索。
技术研发人员:张军;徐苛;陈晓峰
受保护的技术使用者:上海德衡数据科技有限公司
技术研发日:2017.06.08
技术公布日:2017.09.29
- 还没有人留言评论。精彩留言会获得点赞!