方法、装置以及程序与流程
本公开涉及能够提高对话行为的推定精度的方法、装置以及程序。更具体而言,例如涉及对话行为推定方法、对话行为推定装置以及程序,尤其涉及使用被进行机器学习的预定模型来推定说话文的对话行为的对话行为推定方法、对话行为推定装置以及程序。
背景技术:
对话行为推定技术是推定用户说的话所意味的对话行为的技术。作为这种技术,已提出了使用如下神经网络的技术,即该神经网络使用以一句话为单位赋予了对话行为的语料库,将对对话行为有贡献的高频度的词句作为语言特征来学习,还使用与前一句话等的上下文(语境)信息来学习上下文依赖(上下文相关)的对话行为(例如参照非专利文献1)。在非专利文献1中,使用可处理时间序列信息的递归神经网络,学习上下文依赖以及语言特征的对话行为。
现有技术文献
非专利文献
非专利文献1:nalkalchbrenner,philblunsom,“recurrentconvolutionalneuralnetworksfordiscoursecompositionality”,arxivpreprintarxiv:1306.3584,2013.
技术实现要素:
发明所要解决的问题
然而,在上述非专利文献1所提出的方法中,存在学习时的教师数据不足,无法获得足够的推定精度这一问题。
本公开是鉴于上述情形而做出的,其目的在于提供能够提高对话行为的推定精度的方法、装置以及程序。
用于解决问题的技术方案
本公开的一个技术方案涉及的方法,包括:取得学习用数据,所述学习用数据包括:第1文句,其为推定对象的第1时刻的第1说话文的文本数据;第2文句,其为所述第1时刻之前的时刻的、与所述第1说话文连续的第2说话文的文本数据;行为信息,其表示与所述第1文句关联的行为;属性信息,其表示与所述第1文句关联的属性;以及对话行为信息,其表示作为与所述第1文句关联的行为和属性的组合的对话行为,使用所述学习用数据,使预定模型同时学习两种以上的任务,将所述学习得到的结果作为学习结果信息存储于存储器,在所述学习中,作为所述任务之一,使用所述学习用数据所包含的所述行为信息来作为教师数据,使所述预定模型学习所述第1说话文与所述行为信息的关联,作为所述任务之一,使用所述学习用数据所包含的所述属性信息来作为教师数据,使所述预定模型学习所述第1说话文与所述属性信息的关联,作为所述任务之一,将所述学习用数据所包含的所述对话行为信息作为教师数据,使所述预定模型学习所述第1说话文与所述对话行为信息的关联。
另外,本公开的一个技术方案涉及的装置,具备:取得部,其取得学习用数据,所述学习用数据包括:第1文句,其为推定对象的第1时刻的第1说话文的文本数据;第2文句,其为所述第1时刻之前的时刻的、与所述第1说话文连续的第2说话文的文本数据;行为信息,其表示与所述第1文句关联的行为;属性信息,其表示与所述第1文句关联的属性;以及对话行为信息,其表示作为与所述第1文句关联的行为和属性的组合的对话行为;学习部,其使用所述学习用数据,使预定模型同时学习两种以上的任务;以及存储部,其将所述学习得到的结果作为学习结果信息进行存储,所述学习部,作为所述任务之一,使用所述学习用数据所包含的所述行为信息来作为教师数据,使所述预定模型学习所述第1说话文与所述行为信息的关联,作为所述任务之一,使用所述学习用数据所包含的所述属性信息来作为教师数据,使所述预定模型学习所述第1说话文与所述属性信息的关联,作为所述任务之一,将所述学习用数据所包含的所述对话行为信息作为教师数据,使所述预定模型学习所述第1说话文与所述对话行为信息的关联。
此外,这些总括性或者具体的技术方案既可以通过系统、方法、集成电路、计算机程序或计算机可读取的cd-rom等记录介质来实现,也可以通过系统、方法、集成电路、计算机程序和记录介质的任意组合来实现。
发明效果
根据本公开的方法等,能够提高对话行为的推定精度。
附图说明
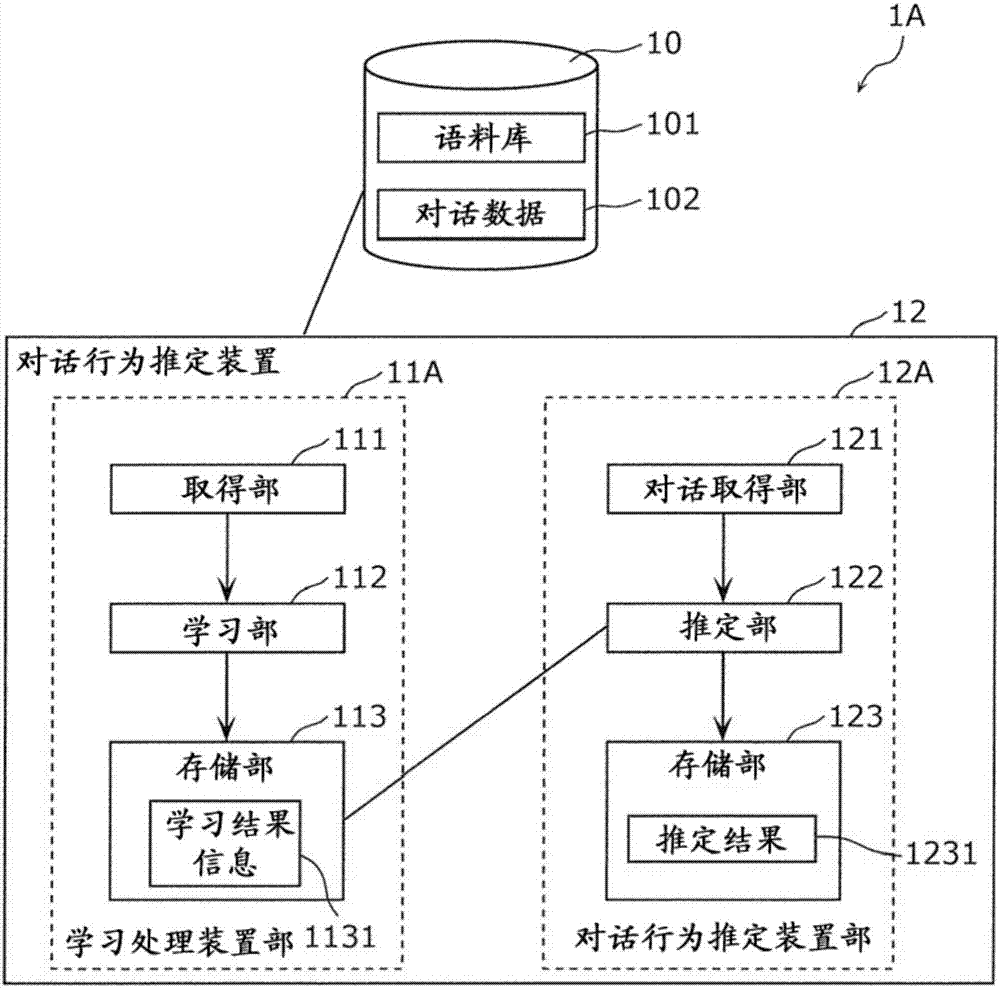
图1是表示实施方式1涉及的对话行为推定系统的构成例的框图。
图2是表示实施方式1涉及的对话行为推定系统的构成的另一例的框图。
图3是表示实施方式1涉及的学习用数据的一例的图。
图4是表示实施方式1涉及的学习部的详细构成的一例的框图。
图5是表示实施方式1涉及的神经网络模型的概略的图。
图6是表示实施方式1涉及的对话数据的一例的图。
图7是表示实施方式1涉及的对话行为推定部的详细构成的一例的框图。
图8是表示实施方式1涉及的对话行为推定装置的推定结果的一例的图。
图9是表示实施方式1涉及的对话行为推定系统的工作的概要的流程图。
图10是实施方式1涉及的学习处理的详细的流程图。
图11是表示图9所示的s23的详细的流程图。
图12是表示实施方式1涉及的对话行为推定方法等的效果的图。
图13是表示实施方式1的变形例涉及的神经网络模型的概略的图。
图14是表示实施方式1的变形例涉及的学习部的详细构成的一例的框图。
图15是表示实施方式1的变形例涉及的推定部的详细构成的一例的框图。
图16a是表示实施方式1的变形例涉及的对话行为推定方法等的效果的图。
图16b是表示实施方式1的变形例涉及的对话行为推定方法等的效果的图。
图17是表示实施方式2涉及的对话系统的构成的一例的框图。
标号说明
1、1a:对话行为推定系统;10:存储装置;11:学习处理装置;11a:学习处理装置部;12、504:对话行为推定装置;12a:对话行为推定装置部;50:服务器;60:便携终端;101:语料库;102:对话数据;111:取得部;112:学习部;113、123:存储部;121:对话取得部;122:推定部;142:训练数据;143:对话id;144、172:时刻信息;145:对话行为信息;146:行为信息;147:属性信息;148、173:说话者识别信息;149:文句;150:神经网络模型;174:说话文;175:对话信息;176:推定对话行为;501、604:通信部;502:语音处理部;505:对话管理部;506:应答生成部;601:麦克风;602:信号处理部;603:应答执行部;1011:学习用数据;1131:学习结果信息;1121、1221:词素解析部;1122、1222:行为用单词特征提取部;1123、1223:属性用单词特征提取部;1124、1224:行为用上下文依赖提取部;1125、1225:属性用上下文依赖提取部;1126:行为预测部;1127:属性预测部;1128、1226:对话行为预测部;1129:权重更新部;1227:对话行为推定部;1231:推定结果;1524、1525、1526、1527、1528:模型。
具体实施方式
(成为本公开的基础的见解)
另外,在非专利文献1中,作为问题的是未使用由连续说的话构成的对话数据所含的重要的上下文信息这一点。对此,提出了以下模型:按各说话者来区别由连续说的话构成的对话数据的话的特征量,利用作为时间序列模型的递归神经网络来进行学习,由此,将自身与对方的说话进行区别,来提取上下文依赖。
然而,非专利文献1假定了输出单一的语义的概念,没有进行对其他语义的概念的利用。
因此,在非专利文献1所提出的方法中,学习时的教师数据不足,无法获得足够的推定精度。
本公开的一个技术方案涉及的方法,包括:取得学习用数据,所述学习用数据包括:第1文句,其为推定对象的第1时刻的第1说话文的文本数据;第2文句,其为所述第1时刻之前的时刻的、与所述第1说话文连续的第2说话文的文本数据;行为信息,其表示与所述第1文句关联的行为;属性信息,其表示与所述第1文句关联的属性;以及对话行为信息,其表示作为与所述第1文句关联的行为和属性的组合的对话行为,使用所述学习用数据,使预定模型同时学习两种以上的任务,将所述学习得到的结果作为学习结果信息存储于存储器,在所述学习中,作为所述任务之一,使用所述学习用数据所包含的所述行为信息来作为教师数据,使所述预定模型学习所述第1说话文与所述行为信息的关联,作为所述任务之一,使用所述学习用数据所包含的所述属性信息来作为教师数据,使所述预定模型学习所述第1说话文与所述属性信息的关联,作为所述任务之一,将所述学习用数据所包含的所述对话行为信息作为教师数据,使所述预定模型学习所述第1说话文与所述对话行为信息的关联。
根据本技术方案,对学习处理对象的第1时刻的说话文的对话行为,使用表示该说话文的文句的行为信息、属性信息、以及行为信息和属性信息的组合的对话行为信息来进行多任务学习。由此,能够提高说话文与对话行为信息的关联的精度。
例如也可以为,所述学习用数据还包括表示所述第1文句的说话者的第1说话者识别信息和表示所述第2文句的说话者的第2说话者识别信息。
根据本技术方案,通过使用表示多个说话文的文句各自的说话者的说话者识别信息来进行学习,能够进一步提高说话文与对话行为信息的关联的精度。
另外,例如也可以为,所述预定模型包括:第1模型,其基于所述第1文句、所述第2文句、所述第1说话者识别信息、所述第2说话者识别信息和第1权重参数,输出第1特征向量,所述第1特征向量表现与所述第1文句所示的行为有关的单词特征以及该单词特征的上下文信息;第2模型,其基于所述第1文句、所述第2文句、所述第1说话者识别信息、所述第2说话者识别信息和第2权重参数,输出第2特征向量,所述第2特征向量表现与所述第1文句所示的属性有关的单词特征以及该单词特征的上下文信息;第3模型,其基于所述第1特征向量和第3权重参数,输出与所述第1文句对应的行为的后验概率;第4模型,其基于所述第2特征向量和第4权重参数,输出与所述第1文句对应的属性的后验概率;以及第5模型,其基于所述第1特征向量、所述第2特征向量和第5权重参数,输出与所述第1文句对应的对话行为的后验概率,在所述学习中,通过基于与所述第1文句对应的行为的后验概率、与所述第1文句对应的属性的后验概率以及与所述第1文句对应的对话行为的后验概率和所述学习用数据所包含的所述对话行为信息、所述行为信息以及所述属性信息之间的误差,用误差反向传播法来更新所述第1权重参数、所述第2权重参数、所述第3权重参数、所述第4权重参数以及所述第5权重参数,从而使用所述学习用数据来使所述预定模型同时学习两种以上的任务。
在此,例如也可以为,所述第1模型通过具有依赖于所述第1说话者识别信息以及所述第2说话者识别信息的所述第1权重参数的rnn-lstm(recurrentneuralnetwork-longshorttermmemory,长短期记忆递归神经网络)来构成,所述第2模型通过具有依赖于所述第1说话者识别信息以及所述第2说话者识别信息的所述第2权重参数的rnn-lstm来构成。
另外,例如也可以为,所述预定模型包括:第1模型,其基于所述第1文句、所述第2文句、所述第1说话者识别信息、所述第2说话者识别信息和第1权重参数,输出特征向量,所述特征向量表现与所述第1文句所示的行为和属性有关的单词特征以及该单词特征的上下文信息;第3模型,其基于所述特征向量和第3权重参数,输出与所述第1文句对应的行为的后验概率;第4模型,其基于所述特征向量和第4权重参数,输出与所述第1文句对应的属性的后验概率;以及第5模型,其基于所述特征向量和第5权重参数,输出与所述第1文句对应的对话行为的后验概率,在所述学习中,通过基于与所述第1文句对应的行为的后验概率、与所述第1文句对应的属性的后验概率以及与所述第1文句对应的对话行为的后验概率和所述学习用数据所包含的所述对话行为信息、所述行为信息以及所述属性信息之间的误差,用误差反向传播法来更新所述第1权重参数、所述第3权重参数、所述第4权重参数以及所述第5权重参数,从而使用所述学习用数据来使所述预定模型同时学习两种以上的任务。
在此,例如也可以为,所述第1模型通过具有依赖于所述第1说话者识别信息以及所述第2说话者识别信息的所述第1权重参数的rnn-lstm来构成。
另外,例如也可以为,在所述取得中,从语料库取得所述学习用数据,所述语料库收集有以时间序列连续地被说出的两个以上的说话文、和与该两个以上的说话文的各个相关联的行为信息、属性信息以及对话行为。
例如也可以为,所述方法还包括:取得对话数据,所述对话数据包括:第3文句,其为由用户所说出的第2时刻的第3说话文的文本数据;第4文句,其为紧接在所述第2时刻之前的时刻的第4说话文的文本数据;表示所述第3文句的说话者的第3说话者识别信息;以及表示所述第4文句的说话者的第4说话者识别信息,通过对反映了在所述存储的步骤中所存储的所述学习结果信息的所述模型应用所述对话数据,推定所述第3说话文的对话行为。
据此,能够使用学习结果,从说话文来推定对话行为。
另外,本公开的一个技术方案涉及的装置,具备:取得部,其取得学习用数据,所述学习用数据包括:第1文句,其为推定对象的第1时刻的第1说话文的文本数据;第2文句,其为所述第1时刻之前的时刻的、与所述第1说话文连续的第2说话文的文本数据;行为信息,其表示与所述第1文句关联的行为;属性信息,其表示与所述第1文句关联的属性;以及对话行为信息,其表示作为与所述第1文句关联的行为和属性的组合的对话行为;学习部,其使用所述学习用数据,使预定模型同时学习两种以上的任务;以及存储部,其将所述学习得到的结果作为学习结果信息进行存储,所述学习部,作为所述任务之一,使用所述学习用数据所包含的所述行为信息来作为教师数据,使所述预定模型学习所述第1说话文与所述行为信息的关联,作为所述任务之一,使用所述学习用数据所包含的所述属性信息来作为教师数据,使所述预定模型学习所述第1说话文与所述属性信息的关联,作为所述任务之一,将所述学习用数据所包含的所述对话行为信息作为教师数据,使所述预定模型学习所述第1说话文与所述对话行为信息的关联。
另外,本公开的一个技术方案涉及的程序使计算机执行根据上述技术方案所述的方法。
此外,这些总括性或者具体的技术方案既可以通过系统、方法、集成电路、计算机程序或计算机可读取的cd-rom等记录介质来实现,也可以通过系统、方法、集成电路、计算机程序和记录介质的任意组合来实现。
以下,参照附图,对本公开的实施方式进行说明。以下说明的实施方式均表示本公开的方法、装置、程序的一个具体例。在以下的实施方式中表示的数值、形状、构成要素、步骤、步骤的顺序等为一例,并非旨在限定本公开。另外,对于以下的实施方式中的构成要素中的、没有记载在表示最上位概念的独立权利要求中的构成要素,作为任意的构成要素进行说明。另外,在所有的实施方式中,也可以组合各自的内容。
(实施方式1)
以下,参照附图,对实施方式1中的对话行为推定方法等进行说明。
[对话行为推定系统]
图1是表示实施方式1涉及的对话行为推定系统1的构成例的框图。图2是表示实施方式1涉及的对话行为推定系统的构成的另一例的框图。此外,对与图1同样的要素赋予相同的标号。
图1所示的对话行为推定系统1具备存储装置10、学习处理装置11和对话行为推定装置12。在图1所示的例子中,本公开的装置具备学习处理装置11和对话行为推定装置12。
<存储装置10>
存储装置10存储语料库101以及对话数据102。语料库101集合了以作为表示一句话的文本数据的一个说话文为单位赋予了对话行为而得到的数据。对话行为表示用户进行的说话的意图的种类。在本实施方式中,语料库101包括多个学习用数据1011。学习用数据1011是学习处理装置11进行学习处理时使用的学习用数据。
存储装置10例如由硬盘驱动器或者固态驱动器等可改写的非易失性存储器构成。
<学习处理装置11>
学习处理装置11从存储于存储装置10的语料库101取得1个以上的学习用数据1011,进行使预定模型同时学习两种以上任务的多任务学习,所述预定模型是为了推定说话文的对话行为而使用的模型。学习处理装置11通过计算机等来实现。在本实施方式中,设为预定模型是包括被进行机器学习的两个递归神经网络的神经网络模型来进行说明,但也可以是包括crf(conditionalrandomfields,条件随机场)等的概率模型。
<对话行为推定装置12>
对话行为推定装置12从存储装置10取得对话数据102,使用由学习处理装置11在多任务学习中进行了机器学习的预定模型,推定对话数据102所包含的说话文的对话行为。对话行为推定装置12通过计算机等来实现。
此外,实施方式1涉及的对话行为推定系统1不限于图1所示的构成。如图2的对话行为推定系统1a所示,也可以为对话行为推定装置12包括:作为与图1所示的学习处理装置11相当的功能部的学习处理装置部11a;和作为与图1所示的对话行为推定装置12相当的功能部的对话行为推定装置部12a。在图2所示的例子中,本公开的装置对应于对话行为推定装置12。也就是说,既可以如图2所示的对话行为推定装置12那样进行学习处理和对话行为推定处理这双方,也可以如图1所示那样在学习处理装置11和对话行为推定装置12这样的不同的装置中进行学习处理和对话行为推定处理。另外,也可以为,图2所示的对话行为推定装置12还包括存储装置10。
以下,对学习处理装置11以及对话行为推定装置12的详细构成进行说明。
[学习处理装置11]
如图1等所示,学习处理装置11具备取得部111、学习部112以及存储部113。
<存储部113>
存储部113将在学习部112中学习得到的结果作为学习结果信息1131进行存储。存储部113例如由硬盘驱动器或者固态驱动器等可改写的非易失性存储器构成。
<取得部111>
取得部111取得学习用数据,所述学习用数据包括:第1文句,其为学习处理对象的第1时刻的第1说话文的文本数据;第2文句,其为第1时刻之前的时刻的、与第1说话文连续的第2说话文的文本数据;行为信息,其表示与第1文句关联的行为;属性信息,其表示与第1文句关联的属性;以及对话行为信息,其表示作为与第1文句关联的行为和属性的组合的对话行为。在此,也可以为,学习用数据还包括表示第1文句的说话者的第1说话者识别信息和表示第2文句的说话者的第2说话者识别信息。另外,取得部111从语料库取得学习用数据,所述语料库收集有以时间序列连续地被说出的两个以上的说话文、和与该两个以上的说话文的各个相关联的行为信息、属性信息以及对话行为。
在本实施方式中,取得部111从存储于存储装置10的语料库101取得1个以上的学习用数据1011。此外,取得部111例如通过cpu、asic或者fpga等处理器来构成,通过cpu等处理器执行计算机所保持的、计算机可读取的程序来实现。
图3是表示实施方式1涉及的学习用数据1011的一例的图。如上所述,图3所示的学习用数据1011包含于语料库101。换言之,语料库101相当于收集有学习用数据1011的集合。
学习用数据1011中包含有关于连续地以时间序列被说出的多个说话文的数据。图3所示的学习用数据1011具有关于构成由英语进行旅行引导的一串对话的多个说话文的数据。
如图3所示,学习用数据1011包括被赋予了对话id143、时刻信息144、对话行为信息145、行为信息146、属性信息147以及说话者识别信息148的文句149。另外,学习用数据1011具有包括1个以上的被赋予了对话id143~说话者识别信息148的文句149的训练数据142。图3示出了训练数据142中包括两个被赋予了对话id143~说话者识别信息148的文句149的例子,但不限于此。
文句149是一个说话文的文本数据,一个说话文表示一句话的文句。如图3所示,文句149是由半角空格分隔了英语单词的文字串数据。此外,在文句149是日语的文本数据的情况下,文句149是没有单词的分隔的文字串数据即可。
对话id143是用于唯一地确定学习用数据1011的标识符。时刻信息144表示文句149的说话顺序即时刻。也就是说,时刻信息144表示学习用数据1011所包含的多个文句149被说出的次序。此外,通过对话id143以及时刻信息144,管理一个学习用数据1011内的对话的开始以及终止。
对话行为信息145、行为信息146和属性信息147表示用户说出文句149所示的话的意图的种类即文句149的分类。具体而言,如图3所示,行为信息146表示如“ini(主导)”、“fol(附和)”、“res(应答)”、“qst(询问)”这样的、文句149所表示的行为的分类。属性信息147表示如“recommend(推荐)”、“info(信息提供)”、“ack(承诺)”这样的、文句149所表示的属性的分类。对话行为信息145表示文句149所表示的对话行为的分类。换言之,对话行为信息145通过图3所示的行为信息146和属性信息147的组合(例如fol_info),表示文句149的意思或其概要。此外,对话行为信息145、行为信息146和属性信息147在学习时被用作针对文句149的教师数据。
说话者识别信息148是用于识别文句149的说话者的信息。
在此,例如使用图3进行说明,取得部111从学习用数据1011取得成为学习部112的学习处理对象的第1时刻的被赋予了对话id143~说话者识别信息148的文句149来作为训练数据142。另外,取得部111从学习用数据1011取得如下前时刻组的文句149以及对该文句149所赋予的信息中的至少说话者识别信息148来作为训练数据142,所述前时刻组是紧接在该时刻之前的连续的时刻,是以预先确定的上下文范围(上下文宽度)表示的数量的1个以上的时刻。在此,上下文范围是固定的,但在对话初期等上下文信息不满足上下文范围的情况下,也可以为比固定的上下文范围短的上下文范围。
例如在上下文范围为5、学习处理对象为时刻5的文句149的情况下,取得部111取得时刻5的被赋予了对话id143~说话者识别信息148的文句149来作为训练数据142。另外,取得部111取得作为前时刻组的时刻0~4的文句149、和前时刻组的时刻0~4的说话者识别信息148“guide(向导)、tourist(旅行者)、guide、tourist、guide”来作为训练数据142。此外,取得部111取得了对时刻5的文句149所赋予的对话行为信息145“fol_ack、fol_positive”、行为信息146“fol”和属性信息147“ack、positive”,作为成为学习时的真值的教师数据。
此外,取得部111基于对话id143进行提取以使得在不同的对话间成为非连续。另外,取得部111通过在每次提取时使第1时刻递增从而能够取得不同的训练数据142。
<学习部112>
学习部112使用学习用数据,使预定模型同时学习两种以上的任务。作为任务之一,学习部112使用学习用数据所包含的行为信息来作为教师数据,使之学习第1说话文与行为信息的关联。另外,作为任务之一,学习部112使用学习用数据所包含的属性信息来作为教师数据,使之学习第1说话文与属性信息的关联。另外,作为任务之一,学习部112将学习用数据所包含的对话行为信息作为教师数据,使之学习第1说话文与对话行为信息的关联。此外,预定模型包括具有第1权重参数的第1模型、具有第2权重参数的第2模型、具有第3权重参数的第3模型、具有第4权重参数的第4模型以及具有第5权重参数的第5模型。
在本实施方式中,学习部112使用由取得部111取得的学习用数据1011,使包括两个递归神经网络的预定模型在多任务学习中进行机器学习。更具体而言,学习部112使用表示如图3的文句149中所示的说话文所包含的单词的重要度等的语言特征和上下文信息,使预定模型对学习处理对象的文句149与行为信息146的关联、该文句149与属性信息147的关联进行学习,并同时使之学习该文句149与对话行为信息145的关联。此外,学习部112例如通过cpu、asic或者fpga等处理器来构成,通过cpu等处理器执行计算机所保持的、计算机可读取的程序来实现。
图4是表示实施方式1涉及的学习部112的详细构成的一例的框图。图5是表示实施方式1涉及的神经网络模型150的概略的图。此外,神经网络模型150相当于上述的预定模型。
如图4所示,学习部112具备词素解析部1121、行为用单词特征提取部1122、属性用单词特征提取部1123、行为用上下文依赖提取部1124、属性用上下文依赖提取部1125、行为预测部1126、属性预测部1127、对话行为预测部1128以及权重更新部1129。
《词素解析部1121》
词素解析部1121在由取得部111取得的说话文中对作为以自然语言而具有意思的最小单位的词素进行解析,变换为以词素为单词的单词串。在本实施方式中,词素解析部1121将由取得部111取得的第1时刻以及前时刻组的文句149各自通过分割为单词从而变换为单词串。词素解析部1121对日语的说话文,例如使用mecab等词素解析软件,能够实现该处理。词素解析部1121例如将“頭痛があリます。(头疼)”这一说话文分割为“頭痛”、“が”、“あリます”、“。”。另外,词素解析部1121对英语的说话文,通过以半角空格为单词划分,能够实现该处理。
《行为用单词特征提取部1122》
行为用单词特征提取部1122基于由词素解析部1121变换得到的单词串,提取用于预测行为信息的单词特征,生成行为用特征向量,所述行为用特征向量是表现了所提取到的单词特征的文向量表示。在本实施方式中,行为用单词特征提取部1122将由词素解析部1121获得的、第1时刻以及前时刻组的单词串各自变换为表现了用于预测行为信息的单词特征的行为用特征向量。
作为向行为用特征向量进行变换的方法,有利用仅考虑文句中是否含有单词、不考虑单词的排列方式等的bag-of-words(词袋)模型的方法。若利用bag-of-words模型,则例如可以在文句中含有单词时表现为1,否则表现为0。在本实施方式中,行为用单词特征提取部1122利用bag-of-words模型,例如基于可假定为输入的所有单词的列表即辞典,变换为仅使句子所含的单词或者连续单词的要素值为1的行为用特征向量。因此,行为用特征向量包括辞典所含的所有单词或者连续单词的数量的要素,各要素与各单词或者连续单词的有无相对应。
此外,作为变换方法,不限于此。也可以使用如下方法:事先进行以行为为教师的有教师学习,变换为提取了在某行为中高频度出现的单词的向量表示。
《属性用单词特征提取部1123》
属性用单词特征提取部1123基于由词素解析部1121变换得到的单词串,提取用于预测属性信息的单词特征,生成属性用特征向量,所述属性用特征向量是表现了所提取到的单词特征的文向量表示。在本实施方式中,属性用单词特征提取部1123将由词素解析部1121获得的、第1时刻以及前时刻组的单词串各自变换为表现了用于预测属性信息的单词特征的属性用特征向量。作为变换方法,有与上述同样地利用bag-of-words模型的方法,或者进行以属性为教师的有教师学习,变换为提取了在某属性中高频度出现的单词的向量表示的方法。
《行为用上下文依赖提取部1124》
行为用上下文依赖提取部1124使用第1模型,根据行为用单词特征提取部1122所生成的行为用特征向量等,生成第1特征向量,所述第1特征向量表示以多个说话文预测行为所使用的单词特征以及高频度出现在该单词特征周围的单词等上下文(语境)。
在本实施方式中,行为用上下文依赖提取部1124使用预定模型所包含的第1模型,基于前时刻组的行为用特征向量、第1时刻的行为用特征向量、前时刻组的说话者识别信息148、和第1权重参数,算出表示在预测针对第1时刻的文句149的行为时高频度使用的上下文的第1特征向量。
在此,行为用上下文依赖提取部1124通过图5所示的神经网络模型150所包含的具有第1权重参数的模型1524来实现。也就是说,模型1524相当于预定模型所包含的第1模型,基于第1文句、第2文句、第1说话者识别信息、第2说话者识别信息和第1权重参数,输出第1特征向量,该第1特征向量表现与第1文句所示的行为有关的单词特征以及该单词特征的上下文信息。模型1524通过具有依赖于第1说话者识别信息以及第2说话者识别信息的第1权重参数的rnn-lstm(recurrentneuralnetwork-longshorttermmemory,长短期记忆递归神经网络)构成。例如,模型1524根据具有依赖于前时刻组的说话者识别信息148(图5中的前说话者识别信息)的第1权重参数的、作为时间序列神经网络模型的rnn-lstm,从第1时刻的文句149和前时刻组的文句149,算出第1特征向量。通过该模型1524,可输出在预测行为时高频度发生的与第1时刻的文句149相依赖的上下文信息来作为第1特征向量。
《属性用上下文依赖提取部1125》
属性用上下文依赖提取部1125使用第2模型,根据属性用单词特征提取部1123所生成的属性用特征向量等,生成第2特征向量,所述第2特征向量表示以多个说话文预测属性所使用的单词特征以及高频度出现在该单词特征周围的单词等上下文。
在本实施方式中,属性用上下文依赖提取部1125使用预定模型所包含的第2模型,基于前时刻组的属性用特征向量、第1时刻的属性用特征向量、前时刻组的说话者识别信息148、和第2权重参数,算出表示在预测针对第1时刻的文句149的属性时高频度使用的上下文的第2特征向量。
在此,属性用上下文依赖提取部1125通过图5所示的神经网络模型150所包含的具有第2权重参数的模型1525来实现。也就是说,模型1525相当于预定模型所包含的第2模型,基于第1文句、第2文句、第1说话者识别信息、第2说话者识别信息和第2权重参数,输出第2特征向量,该第2特征向量表现与第1文句所示的属性有关的单词特征以及该单词特征的上下文信息。模型1525通过具有依赖于第1说话者识别信息以及第2说话者识别信息的第2权重参数的rnn-lstm构成。例如,模型1525根据具有依赖于前时刻组的说话者识别信息148的第2权重参数的、作为时间序列神经网络模型的rnn-lstm,从第1时刻的文句149和前时刻组的文句149,算出第2特征向量。通过该模型1525,可输出在预测属性时高频度发生的与第1时刻的文句149相依赖的上下文信息来作为第2特征向量。
《行为预测部1126》
行为预测部1126使用第3模型,基于由行为用上下文依赖提取部1124算出的第1特征向量、和第3权重参数,预测针对学习处理对象的说话文的行为。
在本实施方式中,行为预测部1126使用预定模型所包含的第3模型,基于由行为用上下文依赖提取部1124算出的第1特征向量、和第3权重参数,算出表示针对第1时刻的文句149的行为的概率分布的后验概率。
在此,行为预测部1126通过图5所示的神经网络模型150所包含的具有第3权重参数的模型1526来实现。也就是说,模型1526相当于预定模型所包含的第3模型,基于第1特征向量和第3权重参数,输出与第1文句对应的行为的后验概率。如图5所示,模型1526通过多项逻辑回归来实现该后验概率的算出。如此,模型1526基于第1特征向量和第3权重参数,算出并输出与第1时刻的文句149对应的行为的后验概率。
《属性预测部1127》
属性预测部1127使用第4模型,基于由属性用上下文依赖提取部1125算出的第2特征向量、和第4权重参数,预测针对学习处理对象的说话文的属性。
在本实施方式中,属性预测部1127使用预定模型所包含的第4模型,基于由属性用上下文依赖提取部1125算出的第2特征向量、和第4权重参数,算出表示针对第1时刻的文句149的属性的概率分布的后验概率。
在此,属性预测部1127通过图5所示的神经网络模型150所包含的具有第4权重参数的模型1527来实现。也就是说,模型1527相当于预定模型所包含的第4模型,基于第2特征向量和第4权重参数,输出与第1文句对应的属性的后验概率。模型1527通过多项逻辑回归来实现该后验概率的算出。如此,模型1527基于第2特征向量和第4权重参数,算出并输出与第1时刻的文句149对应的属性的后验概率。
《对话行为预测部1128》
对话行为预测部1128使用第5模型,基于由行为用上下文依赖提取部1124算出的第1特征向量、由属性用上下文依赖提取部1125算出的第2特征向量、和第5权重参数,预测针对学习处理对象的说话文的对话行为。
在本实施方式中,对话行为预测部1128使用预定模型所包含的第5模型,基于由行为用上下文依赖提取部1124算出的第1特征向量、由属性用上下文依赖提取部1125算出的第2特征向量、和第5权重参数,算出表示针对第1时刻的文句149的对话行为的概率分布的后验概率。
在此,对话行为预测部1128通过图5所示的神经网络模型150所包含的具有第5权重参数的模型1528来实现。也就是说,模型1528相当于预定模型所包含的第5模型,基于第1特征向量、第2特征向量和第5权重参数,输出与第1文句对应的对话行为的后验概率。模型1528通过多项逻辑回归来实现该后验概率的算出。如此,模型1528基于第1特征向量、第2特征向量和第5权重参数,算出并输出与第1时刻的文句149对应的对话行为的后验概率。
《权重更新部1129》
权重更新部1129通过基于与第1文句对应的行为的后验概率、与第1文句对应的属性的后验概率以及与第1文句对应的对话行为的后验概率和学习用数据所包含的对话行为信息、行为信息以及属性信息之间的误差,用误差反向传播法来更新第1权重参数、第2权重参数、第3权重参数、第4权重参数以及第5权重参数,从而使用学习用数据来使预定模型同时学习两种以上的任务。
在本实施方式中,权重更新部1129将模型1524~模型1528的第1权重参数~第5权重参数更新为适合的数值,以使得由行为预测部1126算出的行为的后验概率和由属性预测部1127算出的属性的后验概率以及由对话行为预测部1128算出的对话行为的后验概率呈现成为教师数据即真值的对话行为、行为和属性。
具体而言,权重更新部1129基于对话行为的后验概率与成为真值的对话行为的预测误差、行为的后验概率与成为真值的行为的预测误差、和属性的后验概率与成为真值的属性的预测误差,通过误差反向传播法更新上述的权重参数。也就是说,权重更新部1129更新第1权重参数~第5权重参数即学习参数,以使得对话行为、行为以及属性的后验概率与成为真值的对话行为、行为以及属性之间的误差(差量)变为最小。
如此,学习部112通过在对话行为、行为以及属性的后验概率与学习用数据1011所包含的对话行为、行为以及属性的教师数据之间进行误差反向传播学习,执行使预定模型同时学习两种以上的任务的多任务学习。
<神经网络>
在此,对使用了图5所示的神经网络模型150的学习部112的学习方法进行说明。图5所示的神经网络模型150包括模型1524~模型1528,如上所述,由行为用上下文依赖提取部1124、属性用上下文依赖提取部1125、行为预测部1126、属性预测部1127以及对话行为预测部1128所使用。
模型1524相当于上述的第1模型,由行为用上下文依赖提取部1124所使用。另外,模型1525相当于上述的第2模型,由属性用上下文依赖提取部1125所使用。模型1524以及模型1525分别通过递归神经网络(lstm)来构成。递归神经网络适用于处理时间序列数据。其中,lstm(longshorttermmemory,长短期记忆)也因具有被称为记忆单元的模块,故在能够学习长期依赖关系方面表现出色。
模型1526相当于上述的第3模型,由行为预测部1126所使用。模型1527相当于上述的第4模型,由属性预测部1127所使用。模型1528相当于上述的第5模型,由对话行为预测部1128所使用。模型1526、模型1527以及模型1528分别通过逻辑回归和隐层来构成。
神经网络模型150的目的在于使由下述(式1)表示的误差的值最小化。
l(θ)=lmain(θmain)+lsub1(θsub1)++lsub2(θsub2)---(式1)
在此,lmain(θmain)表示对话行为的预测误差,lsub1(θsub1)表示行为的预测误差,lsub2(θsub2)表示属性的预测误差。θsub1是指模型1524的第1权重参数和模型1526的第3权重参数,θsub2是指模型1525的第2权重参数和模型1527的第4权重参数。θmain是指神经网络模型150的所有学习参数。
关于各预测误差,使用由下述(式2)表示的交叉熵误差。
在此,ptk表示针对n个训练数据142中的第t个(第1时刻)文句149的、ki个预测对象中的第k个标签的后验概率。另外,ytk是针对第t个文句149的、ki个预测对象中的第k个标签的真值。i是指要素{main,sub1,sub2}。也就是说,标签是指构成对话行为的行为和属性、以及作为其组合的对话行为。因此,(式1)表示了针对全部数据的对话行为、行为以及属性的预测误差的总和,学习部112为了使(式1)的预测误差最小化,将θmain用误差反向传播法进行更新。
下面,说明到求出各后验概率为止的神经网络的处理的流程。首先,在lstm中,如下述(式3)~(式6)所示,对特征向量x乘以四个权重矩阵wi、wc、wf、wo,对表示前一个lstm的输出的ht-1乘以权重矩阵hi、hc、hf、ho,使它们的结果与作为偏置项的bi、bc、bf、bo相加。将该结果作为激活函数即sigmoid函数的自变量,由此,算出在0~1的范围内具有要素值的四个向量it、c~t、ft、ot。it、c~t、ft、ot是用于进行记忆单元的控制的向量,按从前向后的顺序承担记忆输入控制、输入记忆单元、记忆忘却控制、记忆输出控制。
it=σ(wixt+hiht-1+bi)---(式3)
ft=σ(wfxt+hfht-1+bf)---(式3)
ot=σ(woxt+hoht-1+bo)---(式6)
接着,如下述(式7)所示,学习部112使用输入控制向量it和输入记忆单元c~t、忘却控制向量ft以及前记忆单元值ct-1,更新神经网络所具有的记忆单元ct的值。
接着,如下述(式8)所示,学习部112通过输出控制向量ot以及记忆单元ct算出ht,ht是第1时刻的lstm的输出。
ht=ot*tanh(ct)---(式8)
在此,t是指在按时间序列排列了前时刻组以及第1时刻的文句149时,其时刻是从过去开始的第几个。将tanh函数表示于(式9)。
学习部112递归地反复进行运算直到作为对话行为的预测对象的第1时刻的t=e为止。此外,对于上述的处理,行为用上下文依赖提取部1124使用第1权重参数,属性用上下文依赖提取部1125使用第2权重参数,以不同的权重参数来进行。
尤其是,作为本实施方式的特征,如下述(式10)所示,在图5的模型1524以及模型1525中,对(式3)~(式7)的权重矩阵hi、hc、hf、ho,使用依赖于之前的说话者识别信息的变量hiat-1、hcat-1、hfat-1、hoat-1。也就是说,利用根据前说话者的识别号码而不同的权重参数对前说话者的文句149的特征向量进行运算而得到的结果被递归地加于下一说话者的文句149的特征向量。由此,预测对话行为的第1时刻的lstm的输出中,在说话者被进行了区别的状态下,上下文得以反映。
接着,将图5所示的模型1526、1527、1528中的处理表示于下述(式11)。
针对某输入向量x,在隐层,乘以权重矩阵w(1),并对其结果加上偏置项b(1)。然后,通过逻辑回归,乘以权重矩阵w(2),并对其结果加上偏置项b(2),由此,获得多个概率值的向量。
logreg(x)=σ(w(2){σ(w(1)x+b(1))}+b(2))---(式11)
此外,(式11)是根据表示某特征量的向量,在神经网络中实现导出概率分布的近似函数的方法。
接着,在图5所示的模型1526中,以作为对话行为的预测对象的第1时刻的t=e的、行为用上下文依赖提取部1124的输出即hesub1作为输入,如下述(式12)所示,使用第3权重参数,获得行为的多个概率值的向量。而且,各要素表示行为的后验概率。
同样地,在图5所示的模型1527中,以作为对话行为的预测对象的第1时刻的t=e的、属性用上下文依赖提取部1125的输出即hesub2作为输入,如下述(式13)所示,使用第4权重参数,获得属性的多个概率值的向量。而且,各要素表示属性的后验概率。
接着,在图5所示的模型1528中,如下述(式14)所示,将由行为用上下文依赖提取部1124求得的特征向量hesub1和由属性用上下文依赖提取部1125求得的特征向量hesub2进行结合,算出hemain。
最后,在图5所示的模型1528中,以作为对话行为的预测对象的第1时刻的t=e的hemain作为输入,如下述(式15)所示,使用第5权重参数,获得对话行为的多个概率值的向量。而且,各要素表示对话行为的后验概率。
上述的处理在行为预测部1126、属性预测部1127和对话行为预测部1128中使用不同的权重参数来进行。
如上所述,通过图5所示的神经网络模型150,算出对话行为的后验概率。
[对话行为推定装置12]
接着,对对话行为推定装置12的详细构成进行说明。
如图1等所示,对话行为推定装置12具备对话取得部121、推定部122和存储部123。
<存储部123>
存储部123将在推定部122中推定得到的结果作为推定结果1231进行存储。存储部123例如由硬盘驱动器或者固态驱动器等可改写的非易失性存储器构成。
<对话取得部121>
对话取得部121取得对话数据,所述对话数据包括:第3文句,其为由用户所说出的第2时刻的第3说话文的文本数据;第4文句,其为紧接在第2时刻之前的时刻的第4说话文的文本数据;表示第3文句的说话者的第3说话者识别信息;以及表示第4文句的说话者的第4说话者识别信息。
在本实施方式中,对话取得部121取得对话数据102。更具体而言,对话取得部121取得成为推定处理对象的时刻的说话文、和作为紧接在该时刻之前的连续的时刻且以预先确定的上下文范围表示的数量的1个以上的时刻的前时刻组的说话文来作为对话数据。此外,对话取得部121例如通过cpu、asic或者fpga等处理器来构成,通过cpu等处理器执行计算机所保持的、计算机可读取的程序来实现。
图6是表示实施方式1涉及的对话数据102的一例的图。
对话数据102中包含有关于以时间序列被发出的多个说话文的数据。图6所示的对话数据102具有关于构成由英语进行旅行引导的一串对话的多个说话文的数据。
对话数据102包括赋予了时刻信息172以及说话者识别信息173的说话文174。另外,对话数据102具有多个包括1个以上的被赋予了时刻信息172以及说话者识别信息173的说话文174的对话信息175。图6示出了对话信息175中包括两个说话文174的例子,但不限于此。
说话文174是一个说话文的文本数据,该一个说话文表示由用户所说出的一句话的文句。图6所示的说话文174是由半角空格分隔了英语单词的文字串数据。此外,在说话文174是日语的文本数据的情况下,说话文174是没有单词的分隔的文字串数据即可。时刻信息172表示说话文174的说话顺序即时刻。也就是说,时刻信息172表示对话数据102所包含的多个说话文174被说出的次序。说话者识别信息173是用于识别说话文174的说话者的信息。
在图6中,示出了具有将第2时刻设为时刻4、将前时刻组设为时刻0~3的上下文范围为4的对话数据102的例子。与时刻0~4的各时刻对应的说话者识别信息173为“guide、tourist、tourist、tourist、guide”。
对话数据102例如基于从外部输入的连续的多个说话文而生成。即,首先,将连续的多个说话文以时间序列进行分割而生成多个说话文174。例如,在通过文本聊天系统输入了连续的说话文的情况下,以一次向对方发送的文本为单位来分割说话文而生成多个说话文174即可。另外,在通过语音对话系统输入了连续的说话文的情况下,基于成为语音识别的触发的连续无音区间的产生,分割说话文而生成多个说话文174即可。接着,对生成的各说话文174赋予时刻信息172以及说话者识别信息173。说话者识别信息173既可以通过声纹认证等生成,也可以从外部输入。
此外,对话数据102不限于被保存在位于对话行为推定装置12外部的存储装置10的情况,也可以为对话行为推定装置12基于从外部输入的用户的说话文来生成。也就是说,对话数据102既可以是对话行为推定装置12生成,也可以是其他装置生成。
另外,对话数据102至少保持有与上下文范围相应的过去的连续的说话文和新输入的当前的说话文,根据新的输入去除最以前的说话文。另外,上下文范围是固定的,但也可以使用与上述的取得部111取得的训练数据142的上下文范围相等的数值。
<推定部122>
推定部122通过对反映了在学习处理装置11中所存储的学习结果信息1131的预定模型应用对话数据,推定第3说话文的对话行为。
在本实施方式中,推定部122使用反映了存储于存储部113的学习结果信息1131的预定模型,对推定对象的说话文的对话行为进行推定。该预定模型与在学习部112中使用的神经网络模型150构造相同。此外,推定部122例如通过cpu、asic或者fpga等处理器来构成,通过cpu等处理器执行计算机所保持的、计算机可读取的程序来实现。
图7是表示实施方式1涉及的推定部122的详细构成的一例的框图。对与图1等同样的要素赋予相同的标号。
如图7所示,推定部122具备词素解析部1221、行为用单词特征提取部1222、属性用单词特征提取部1223、行为用上下文依赖提取部1224、属性用上下文依赖提取部1225、对话行为预测部1226以及对话行为推定部1227。
《词素解析部1221》
词素解析部1221对由对话取得部121取得的对话数据102所包含的说话文的词素进行解析,变换为以词素为单词的单词串。在本实施方式中,词素解析部1221将由对话取得部121取得的图6所示的对话数据102所包含的成为推定处理对象的时刻(第2时刻)以及前时刻组的说话文174各自通过利用词素解析分割为单词,从而变换为单词串。
此外,词素解析的方法如上所述。
《行为用单词特征提取部1222》
行为用单词特征提取部1222基于由词素解析部1221变换得到的单词串,提取用于预测行为信息的单词特征,生成表现了所提取到的单词特征的行为用特征向量。在本实施方式中,行为用单词特征提取部1222将由词素解析部1221获得的、第2时刻以及前时刻组的单词串各自变换为行为用特征向量,该行为用特征向量是表现了用于预测行为信息的单词特征的文向量表示。
此外,向行为用特征向量进行变换的方法如上所述。
《属性用单词特征提取部1223》
属性用单词特征提取部1223基于由词素解析部1221变换得到的单词串,提取用于预测属性信息的单词特征,生成表现了所提取到的单词特征的属性用特征向量。在本实施方式中,属性用单词特征提取部1223将由词素解析部1221获得的、第2时刻以及前时刻组的单词串各自变换为表现了用于预测属性信息的单词特征的属性用特征向量。
此外,向属性用特征向量进行变换的方法如上所述。
《行为用上下文依赖提取部1224》
行为用上下文依赖提取部1224使用已学习完的第1模型,根据行为用单词特征提取部1222所生成的行为用特征向量等,生成第1特征向量,所述第1特征向量表示以多个说话文预测行为所使用的单词特征以及高频度出现在该单词特征周围的单词等上下文。在本实施方式中,行为用上下文依赖提取部1224基于前时刻组的行为用特征向量、第2时刻的行为用特征向量、前时刻组的说话者识别信息173以及已学习完的第1权重参数,算出第1特征向量。
在此,行为用上下文依赖提取部1224通过图5所示的神经网络模型150所包含的具有已学习完的第1权重参数的模型1524来实现。也就是说,已学习完的模型1524相当于预定模型所包含的第1模型,具有反映了学习结果信息1131的第1权重参数。行为用上下文依赖提取部1224使用已学习完的模型1524,可输出在预测行为时高频度发生的与第2时刻的说话文174相依赖的上下文信息来作为第1特征向量。
此外,对于使用模型1524来输出第1特征向量的方法,除了使用已学习完的第1权重参数这一点以外,均为如上所述。
《属性用上下文依赖提取部1225》
属性用上下文依赖提取部1225使用已学习完的第2模型,根据属性用单词特征提取部1223所生成的属性用特征向量等,生成第2特征向量,所述第2特征向量表示以多个说话文预测属性所使用的单词特征以及高频度出现在该单词特征周围的单词等上下文。在本实施方式中,属性用上下文依赖提取部1225基于前时刻组的属性用特征向量、第2时刻的属性用特征向量、前时刻组的说话者识别信息173以及已学习完的第2权重参数,算出第2特征向量。
在此,属性用上下文依赖提取部1225通过图5所示的神经网络模型150所包含的具有已学习完的第2权重参数的模型1525来实现。也就是说,已学习完的模型1525相当于预定模型所包含的第2模型,具有反映了学习结果信息1131的第2权重参数。属性用上下文依赖提取部1225使用已学习完的模型1525,可输出预测属性时高频度发生的与第2时刻的说话文174相依赖的上下文信息来作为第2特征向量。
此外,对于使用模型1525来输出第2特征向量的方法,除了使用已学习完的第2权重参数这一点以外,均为如上所述。
《对话行为预测部1226》
对话行为预测部1226使用已学习完的第5模型,基于由行为用上下文依赖提取部1224算出的第1特征向量、由属性用上下文依赖提取部1225算出的第2特征向量、和已学习完的第5权重参数,预测针对推定处理对象的说话文的对话行为。在本实施方式中,对话行为预测部1226基于由行为用上下文依赖提取部1224算出的第3特征向量、由属性用上下文依赖提取部1225算出的第4特征向量、和已学习完的第5权重参数,算出表示针对第2时刻的说话文174的对话行为的概率分布的后验概率。
在此,对话行为预测部1226通过图5所示的神经网络模型150所包含的具有已学习完的第5权重参数的模型1528来实现。也就是说,已学习完的模型1528相当于预定模型所包含的第5模型,具有反映了学习结果信息1131的第5权重参数。
此外,对于使用模型1528来算出表示对话行为的概率分布的后验概率的方法,除了使用已学习完的第5权重参数这一点以外,均为如上所述。
《对话行为推定部1227》
对话行为推定部1227基于由对话行为预测部1226算出的对话行为的后验概率,推定对话行为。对话行为推定部1227将表示推定出的对话行为的推定结果1231存储于存储部123。例如,对话行为推定部1227通过对由后验概率所表示的多个对话行为的概率值例如应用阈值0.5,能够指定概率值高的多个对话行为作为推定结果1231。
图8是表示实施方式1涉及的对话行为推定装置12的推定结果1231的一例的图。对与图6同样的要素赋予相同的标号。图8是对图6所示的对话数据102的推定结果1231的一例。
如图8所示,推定结果1231与图6所示的对话数据102相比较,包括针对以时间序列被发出的多个说话文174的推定对话行为176。推定对话行为176是由对话行为推定部1227获得的针对说话文174的对话行为的推定结果。
在图8中,示出了下述例子:取得了将第2时刻设为时刻4、将前时刻组设为时刻0~3的上下文范围为4的对话数据102,获得了“res_info(应答_信息提供)”作为第2时刻的推定对话行为176。这是通过由行为用上下文依赖提取部1224和属性用上下文依赖提取部1225提取到了按行为而高频度发生的“youcantake”和按属性而高频度发生的“station”,从而预测准确率得到进一步提高的例子。再者,通过对话行为预测部1226对第1特征向量和第2特征向量的组合进行学习,例如能够避免如“fol_info(附和_信息提供)”那样的部分为正解的预测。
[对话行为推定系统1的工作]
接着,对如上所述构成的对话行为推定系统1的工作进行说明。
图9是表示实施方式1涉及的对话行为推定系统1的工作的概要的流程图。本公开的方法的一个具体例包括使用图9的流程图所说明的对话行为推定系统1的一系列处理的一部分或者全部。
首先,对话行为推定系统1使用语料库101所包含的学习用数据1011,进行学习说话文与对话行为的对应关系的学习处理(s1)。更具体而言,在s1中,学习处理装置11首先从存储于存储装置10的语料库101取得学习用数据1011(s11)。接着,学习处理装置11使用在s11中取得的学习用数据1011来使为了推定说话文的对话行为而使用的预定模型进行多任务学习(s12)。然后,学习处理装置11将在s12中学习到的结果作为学习结果信息1131进行存储(s13)。
接着,对话行为推定系统1使用s1的学习处理的结果,进行推定说话文的对话行为的对话行为推定处理(s2)。更具体而言,在s2中,首先,对话行为推定装置12读入作为s1的学习处理的结果的学习结果信息1131(s21),并反映到预定模型中。接着,对话行为推定装置12取得存储于存储装置10的对话数据102(s22)。然后,对话行为推定装置12使用反映了学习结果信息1131的预定模型,推定对话数据102所包含的说话文的对话行为(s23)。
<学习处理装置11的工作>
接着,对学习处理装置11所进行的学习处理的详细进行说明。
图10是实施方式1涉及的学习处理的详细的流程图。对与图9同样的要素赋予相同的标号。以下,使用图3等所示的例子进行说明。本公开的方法的一个具体例包括使用图10的流程图所说明的学习处理装置11的一系列处理的一部分或者全部。
首先,学习处理装置11将作为学习对象的所有权重参数即学习对象的学习参数初始化(s10)。具体而言,学习处理装置11基于伪随机数表将图5所示的神经网络模型150的第1权重参数~第5权重参数初始化。
接着,学习处理装置11取得学习用数据1011(s11)。具体而言,学习处理装置11取得存储于存储装置10的语料库101所包含的多个学习用数据1011中的一个。
接着,学习处理装置11使用在s11中取得的学习用数据1011来进行学习(s12)。具体而言,学习处理装置11将在s11中取得的学习用数据1011所包含的行为信息、属性信息以及对话行为信息用作教师数据。学习处理装置11使图5所示的神经网络模型150使用该教师数据来学习学习处理对象的第1说话文与行为信息的关联、第1说话文与属性信息的关联以及第1说话文与对话行为信息的关联。
更详细而言,如图10所示,在s12中,首先,学习处理装置11将在s11中取得的第1时刻以及前时刻组的文句149各自通过进行词素解析从而变换为单词串(s1211)。
接着,学习处理装置11将在s1211中获得的第1时刻以及前时刻组的单词串各自变换为表现了用于预测行为信息的单词特征的行为用特征向量(s1212)。另外,学习处理装置11将在s1211中获得的第1时刻以及前时刻组的单词串各自变换为表现了用于预测属性信息的单词特征的属性用特征向量(s1213)。
接着,学习处理装置11基于在s1212中算出的前时刻组的行为用特征向量以及第1时刻的行为用特征向量、前时刻组的说话者识别信息148、和模型1524的第1权重参数,算出第1特征向量,所述第1特征向量表示在预测针对第1时刻的文句149的行为时被高频度使用的上下文(s1214)。另外,学习处理装置11基于在s1213中算出的前时刻组的属性用特征向量以及第1时刻的属性用特征向量、前时刻组的说话者识别信息148、和模型1525的第2权重参数,算出第2特征向量,所述第2特征向量表示在预测针对第1时刻的文句149的属性时被高频度使用的上下文(s1215)。
接着,学习处理装置11基于在s1214中算出的第1特征向量、和模型1526的第3权重参数,算出表示针对第1时刻的文句149的行为的概率分布的后验概率(s1216)。另外,学习处理装置11基于在s1215中算出的第2特征向量、和模型1527的第4权重参数,算出表示针对第1时刻的文句149的属性的概率分布的后验概率(s1217)。
接着,学习处理装置11基于在s1214中算出的第1特征向量、在s1215中算出的第2特征向量、和模型1528的第5权重参数,算出表示针对第1时刻的文句149的对话行为的概率分布的后验概率(s1218)。
接着,学习处理装置11使用在s1216中算出的行为的后验概率、在s1217中算出的属性的后验概率、在s1218中算出的对话行为的后验概率、和教师数据来进行学习(s1219)。如上所述,这里的教师数据是由第1时刻的对话行为信息145表示的成为真值的对话行为、由第1时刻的行为信息146表示的成为真值的行为、由第1时刻的属性信息147表示的成为真值的属性。也就是说,学习处理装置11使用在s1216~s1218中算出的行为、属性以及对话行为的后验概率和它们的教师数据,将模型1524~模型1528的第1权重参数~第5权重参数即学习参数通过进行误差反向传播学习而更新为适合的数值。
接着,学习处理装置11判定是否结束s12的学习处理(s1220)。在不结束s12的学习处理的情况下(s1220:否),再次返回到s11,将第1时刻的下一时刻设为第1时刻,或者取得另外的学习用数据1011,进行s12的学习处理。也就是说,学习处理装置11一边变更作为学习处理对象的第1时刻或者学习用数据1011,一边反复执行s12的学习处理直到学习收敛为止。
另一方面,学习处理装置11在结束学习处理的情况下(s1220:是),将表示学习处理的结果的学习结果信息1131进行存储(s13)。具体而言,学习处理装置11将学习处理结束时的学习参数作为学习结果信息1131进行存储。此外,学习处理装置11在即使反复进行学习,误差也不减小的情况下判定为结束学习处理。
<对话行为推定装置12的工作>
接着,对对话行为推定装置12所进行的对话行为推定的详细进行说明。
图11是表示图9所示的s23的详细的流程图。对与图9同样的要素赋予相同的标号。以下,使用图6等所示的例子进行说明。本公开的方法的一个具体例包括使用图11的流程图所说明的对话行为推定装置12的一系列处理的一部分或者全部。
在s23中,对话行为推定装置12使用具有反映了学习结果信息1131的第1权重参数~第5权重参数的神经网络模型150,对推定处理对象的说话文的对话行为进行推定。
更详细而言,如图11所示,在s23中,首先,对话行为推定装置12将在s22中取得的对话数据102所包含的推定处理对象的第2时刻以及前时刻组的说话文174各自通过进行词素解析从而变换为单词串(s2311)。
接着,对话行为推定装置12将在s2311中获得的第2时刻以及前时刻组的单词串各自变换为表现了用于预测行为信息的单词特征的行为用特征向量(s2312)。另外,对话行为推定装置12将在s2311中获得的第2时刻以及前时刻组的单词串各自变换为表现了用于预测属性信息的单词特征的属性用特征向量(s2313)。
接着,对话行为推定装置12基于在s2312中算出的前时刻组的行为用特征向量以及第2时刻的行为用特征向量、前时刻组的说话者识别信息173、和模型1524的已学习完的第1权重参数,算出第1特征向量,所述第1特征向量表示在预测针对第2时刻的说话文174的行为时被高频度使用的上下文(s2314)。另外,对话行为推定装置12基于在s2313中算出的前时刻组的属性用特征向量以及第2时刻的属性用特征向量、前时刻组的说话者识别信息173、和模型1525的已学习完的第2权重参数,算出第2特征向量,所述第2特征向量表示在预测针对第2时刻的说话文174的属性时被高频度使用的上下文(s2315)。
接着,对话行为推定装置12基于在s2314中算出的第1特征向量、在s2315中算出的第2特征向量、和模型1528的已学习完的第5权重参数,算出表示针对第2时刻的说话文174的对话行为的概率分布的后验概率(s2316)。
接着,对话行为推定装置12基于在s2316中获得的对话行为的后验概率,推定针对第2时刻的说话文174的对话行为(s2317)。对话行为推定装置12将表示推定出的对话行为的推定结果1231进行存储。
此外,对对话数据102所包含的各时刻的说话文174依次进行图11所示的一系列处理。
[效果等]
如上所述,根据本实施方式,使用两个rcnn即分别与行为以及属性对应的rcnn,对行为用上下文依赖提取和属性用上下文提取的任务进行学习,同时也对其特征结合的任务进行学习。由此,能够实现能够提高对话行为的推定精度的对话行为推定方法以及对话行为推定装置。
更具体而言,在本实施方式中,对学习处理对象的第1时刻的说话文的对话行为,使用表示该说话文的文句的行为信息和属性信息、以及行为信息和属性信息的组合的对话行为信息来进行多任务学习。例如,使用图3所示的表示文句149所示的行为的种类的行为信息146、表示文句149所示的属性的种类的属性信息147、以及例如fol_info等基于行为信息146和属性信息147的组合的文句149所示的对话行为信息145,进行学习。由此,能够提高说话文与对话行为信息的关联的精度。此外,通过分别地收集第1时刻的说话文的文句、该文句的行为信息以及该文句的属性信息,也能够进一步提高精度。
另外,通过还使用表示多个说话文各自的说话者的说话者识别信息来进行学习,能够进一步提高说话文与对话行为信息的关联的精度。
此外,也可以还使用说话者更替信息和说话者识别信息来进行学习,所述说话者更替信息表示学习处理对象的第1时刻的文句的说话者是否与接近在第1时刻之前的文句的说话者相同,所述说话者识别信息表示各文句的说话者。由此,能够进一步提高说话文与对话行为信息的关联的精度。
图12是表示实施方式1涉及的对话行为推定方法等的效果的图。在图12中,示出了使用每组包括100~1000条对话的14组英语对话数据规模的旅行引导的对话语料库(dstc4),学习了图5所示的神经网络模型150的学习参数时的对话行为推定的结果。另外,作为比较例,在图12中示出了通过非专利文献1所提出的方法进行了学习时的对话行为推定的结果。
如图12所示,可知在由4种行为和22种属性而成的88种对话行为的分类精度(f1值)中,实施方式1涉及的推定结果与非专利文献1的推定结果相比较,不论是对向导还是对旅行者均呈现出了优异的分类精度。
(变形例)
图13是表示实施方式1的变形例涉及的神经网络模型150b的概略的图。此外,对与图5同样的要素赋予相同的标号,并省略详细说明。
在实施方式1中,说明了学习处理装置11以及对话行为推定装置12使用图5所示的神经网络模型150来作为预定模型,但不限于此。也可以使用图13所示的神经网络模型150b。
图13所示的神经网络模型150b与图5所示的神经网络模型150相比较,结构的不同之处在于不具有模型1524和模型1525中的模型1525,而仅包括模型1524b。即,结构的不同之处在于图13所示的神经网络模型150b是包括一个递归神经网络的模型,图5所示的神经网络模型150是包括两个递归神经网络的模型。
以下,对与实施方式1的不同之处进行说明。
[学习部112b]
与实施方式1同样地,学习部112b使用学习用数据,使预定模型同时学习两种以上的任务。作为任务之一,学习部112b使用学习用数据所包含的行为信息来作为教师数据,使之学习第1说话文与行为信息的关联。另外,作为任务之一,学习部112b使用学习用数据所包含的属性信息来作为教师数据,使之学习第1说话文与属性信息的关联。另外,作为任务之一,学习部112b以学习用数据所包含的对话行为信息作为教师数据,使之学习第1说话文与对话行为信息的关联。
在本变形例中,预定模型包含具有第1权重参数的第1模型、具有第3权重参数的第3模型、具有第4权重参数的第4模型、具有第5权重参数的第5模型。第1模型基于第1文句、第2文句、第1说话者识别信息、第2说话者识别信息和第1权重参数,输出特征向量,该特征向量表现与第1文句所表示的行为和属性有关的单词特征以及该单词特征的上下文信息。第1模型通过具有依赖于第1说话者识别信息以及第2说话者识别信息的所述第1权重参数的rnn-lstm构成。第3模型基于特征向量和第3权重参数,输出与第1文句对应的行为的后验概率。第4模型基于特征向量和第4权重参数,输出与第1文句对应的属性的后验概率。第5模型基于特征向量和第5权重参数,输出与第1文句对应的对话行为的后验概率。
也就是说,在本变形例中,学习部112b基于与第1文句对应的行为的后验概率、与第1文句对应的属性的后验概率以及与所述第1文句对应的对话行为的后验概率和学习用数据所包含的对话行为信息、行为信息以及属性信息之间的误差,通过用误差反向传播法来更新第1权重参数、第3权重参数、第4权重参数以及第5权重参数,从而使用学习用数据来进行同时学习两种以上的任务的多任务学习。
也就是说,学习部112b使用由取得部111取得的学习用数据1011,使包括一个递归神经网络的预定模型进行多任务学习。而且,该预定模型相当于图13所示的神经网络模型150b。
图14是表示实施方式1的变形例涉及的学习部112b的详细构成的一例的框图。对与图4同样的要素赋予相同的标号,并省略详细说明。
图14所示的学习部112b与图4所示的学习部112相比较,结构的不同之处在于不具有行为用上下文依赖提取部1124以及属性用上下文依赖提取部1125,而追加了行为用以及属性用上下文依赖提取部1124b。
<行为用以及属性用上下文依赖提取部1124b>
行为用以及属性用上下文依赖提取部1124b使用第1模型,根据行为用单词特征提取部1122所生成的行为用特征向量和属性用单词特征提取部1123所生成的属性用特征向量等,生成特征向量,所述特征向量表示以多个说话文预测行为和属性所使用的单词特征以及高频度出现在该单词特征周围的单词等上下文。此外,行为用以及属性用上下文依赖提取部1124b使用第1模型来生成特征向量这一工作相当于生成相同的第1特征向量以及第2特征向量来设为特征向量。
在此,行为用以及属性用上下文依赖提取部1124b由图13所示的神经网络模型150b所包含的具有第1权重参数的模型1524b实现。也就是说,模型1524b相当于本变形例的预定模型所包含的第1模型,基于第1文句、第2文句、第1说话者识别信息、第2说话者识别信息和第1权重参数,输出特征向量,所述特征向量表现与第1文句所示的行为和属性有关的单词特征以及该单词特征的上下文信息。模型1524b通过具有依赖于第1说话者识别信息以及第2说话者识别信息的第1权重参数的rnn-lstm构成。例如,模型1524b根据具有依赖于前时刻组的说话者识别信息148(图13中为前说话者识别信息)的第1权重参数的、作为时间序列神经网络模型的rnn-lstm,从第1时刻的文句149和前时刻组的文句149,算出特征向量。通过该模型1524b,可输出在预测行为以及属性时高频度发生的与第1时刻的文句149相依赖的上下文信息来作为特征向量。
此外,这能够通过如下方式实现:在上述的式1~式15中,将第3权重参数、第4权重参数设为单一的共同权重参数,将作为行为用上下文依赖提取部1124的输出的hesub1和作为属性用上下文依赖提取部1125的输出的hesub2以及结合了它们的hemain全部表现为相同的特征向量。
[推定部122b]
推定部122b通过对反映了作为由学习部112b学习得到的结果的学习结果信息1131的预定模型应用对话数据,推定说话文的对话行为。在本变形例中,推定部122b使用反映了存储于存储部113的学习结果信息1131的神经网络模型150b,对推定对象的说话文的对话行为进行推定。该神经网络模型150b与在学习部112b中使用的模型构造相同。
图15是表示实施方式1的变形例涉及的推定部122b的详细构成的一例的框图。对与图7等同样的要素赋予相同的标号。
图15所示的推定部122b与图7所示的推定部122相比较,结构的不同之处在于不具有行为用上下文依赖提取部1224和属性用上下文依赖提取部1225,而追加了行为用以及属性用上下文依赖提取部1224b。
<行为用以及属性用上下文依赖提取部1224b>
行为用以及属性用上下文依赖提取部1224b使用已学习完的第1模型,根据行为用单词特征提取部1222所生成的行为用特征向量和属性用单词特征提取部1223所生成的属性用特征向量等,生成特征向量,所述特征向量表示以多个说话文预测行为和属性所使用的单词特征以及高频度出现在该单词特征周围的单词等上下文。
在此,行为用以及属性用上下文依赖提取部1224b通过图13所示的神经网络模型150b所包含的具有已学习完的第1权重参数的模型1524b来实现。
此外,行为用以及属性用上下文依赖提取部1224b使用第1模型来生成特征向量这一工作相当于在实施方式1中生成相同的第1特征向量以及第2特征向量来设为特征向量。
[效果等]
如上所述,根据本变形例,使用一个rcnn,对行为用上下文依赖提取和属性用上下文提取的任务进行学习,同时也对其特征结合的任务进行学习。由此,能够实现能够提高对话行为的推定精度的对话行为推定方法以及对话行为推定装置。
图16a以及图16b是表示实施方式1的变形例涉及的对话行为推定方法等的效果的图。在图16a以及图16b中,也使用了每组包括100~1000条对话的14组英语对话数据规模的旅行引导的对话语料库。在图16a以及图16b中,示出了使用旅行引导的对话语料库(dstc4)而是使图13所示的神经网络模型150b学习了学习参数时的对话行为推定的结果。另外,作为比较例,在图16a以及图16b中示出了通过非专利文献1所提出的方法来进行了学习时的对话行为推定的结果和通过实施方式1涉及的方法来进行了学习时的对话行为推定的结果。
如图16a以及图16b所示,在由4种行为和22种属性而成的88种对话行为的分类精度(f1值)中,本变形例涉及的推定结果与非专利文献1的推定结果相比较,不论是对向导还是对旅行者均示出了优异的分类精度。另外,本变形例涉及的推定结果与实施方式1涉及的推定结果相比较,对旅行者呈现出了优异的分类精度。这可考虑为是由于与实施方式1相比较,在旅行引导的对话语料库(dstc4)中能够作为教师数据加以利用的数据量增加了而引起的。
(实施方式2)
接着,作为实施方式2,对上述的对话行为推定装置12的利用方式进行说明。
图17是表示实施方式2涉及的对话系统的构成的一例的框图。该对话系统具有语音识别的功能,包括存在于云上的服务器50、和智能手机等便携终端60。用户经由便携终端60,能够通过语音与系统进行基于自然语言的对话。服务器50以及便携终端60例如经由互联网等公共通信网络而连接。
便携终端60是智能手机或者平板电脑等。便携终端60具备麦克风601、信号处理部602、应答执行部603以及通信部604。麦克风601是将语音变换为电的语音信号的设备,用于收集用户的语音。信号处理部602判定从麦克风601输入的语音信号是否是噪声,在不是噪声的情况下,将该语音信号输出给通信部604。通信部604将所输入的语音信号变换为具有能够通信的格式的通信信号,并将获得的通信信号发送给服务器50。应答执行部603将信号处理部602通过通信部604接收到的应答文显示于监视器。
服务器50具备对话行为推定装置12、通信部501、语音处理部502、对话行为推定装置504、对话管理部505以及应答生成部506。
通信部501接收来自便携终端60的通信信号,从通信信号中取出语音信号,将取出的语音信号输出给语音处理部502。语音处理部502通过对被取出的语音信号进行解析,生成表示用户所说的话的语音的文本数据。
对话行为推定装置504例如是图2所示的对话行为推定装置12,是上述的学习处理已经结束的状态。对话行为推定装置504使用由语音处理部502生成的文本数据,生成上述的对话数据102,使用该对话数据102,推动对话行为,并输出推定结果。
对话管理部505将由对话行为推定装置504推定出的对话行为以时间序列进行保持,基于对话行为的序列,输出应该应答的系统侧的对话行为。应答生成部506生成与从对话管理部505接收到的对话行为对应的应答文。而且,通信部501将所生成的应答文变换为具有能够通信的格式的通信信号,将获得的通信信号发送给便携终端60。
如此,在图17所示的对话系统中,服务器50能够使用在实施方式1中说明的进行了学习后的对话行为推定装置504,适当地理解用户说的话,进行应答。
以上,对实施方式涉及的对话行为推定装置以及对话行为推定方法等进行了说明,但是本公开不限定于该实施方式。
另外,上述实施方式涉及的对话行为推定装置所含的各处理部,典型地作为集成电路即lsi来实现。这些既可以个别地单芯片化,也可以单芯片化成包含一部分或者全部。
另外,集成电路化不限于lsi,也可以通过专用电路或者通用处理器来实现。也可以利用在lsi制造后可编程的fpga(fieldprogrammablegatearray:现场可编程们阵列)或者可以重构lsi内部的电路单元的连接和/或设定的可重构处理器。
另外,本公开也可以作为由对话行为推定装置执行的对话行为推定方法来实现。
另外,在上述各实施方式中,各结构要素可以由专用的硬件构成,也可以通过执行适合于各结构要素的软件程序来实现。各结构要素也可以通过由cpu或处理器等程序执行部读出并执行记录于硬盘或半导体存储器等记录介质的软件程序来实现。
另外,框图中的功能块的分割仅为一例,可以将多个功能块作为一个功能块实现,也可以将一个功能块分割为多个,还可以将一部分的功能移至其他的功能块。另外,也可以由单一的硬件或者软件并行或者分时地处理具有类似的功能的多个功能块的功能。
另外,流程图中的各步骤被执行的顺序是为了具体地说明本公开而例示的,也可以是上述以外的顺序。另外,上述步骤的一部分也可以与其他的步骤同时(并行)地执行。
以上,基于实施方式对一个或多个技术方案涉及的对话行为推定装置进行了说明,但是本公开并不限定于该实施方式。只要不偏离本公开的宗旨,将本领域技术人员想到的各种变形应用于本实施方式而得到的方式、和将不同实施方式中的构成要素组合而构建的方式也可以包含在一个或者多个技术方案的范围内。
产业上的可利用性
本公开能够适用于对话行为推定装置,例如,能够适用于如下系统:基于保持有通过语音或者文本获得的用户说的话的对话历史记录,适当地理解用户说的话。另外,本公开能够利用于达成用户的任务的呼叫中心、问诊对话、或者闲谈对话等面向任务或者非面向任务的对话系统装置或者对话系统方式。另外,本公开能够利用于从对话历史记录仅提取特定的对话行为的信息检索装置或者信息检索方式。
- 还没有人留言评论。精彩留言会获得点赞!