基于卷积神经网络的汉语手语识别方法与流程
本发明属于手势识别领域。
背景技术:
目前手势识别方法主要分为两类,一是基于穿戴式设备的是被方法,虽然实时性较好,但是穿戴设备有价格昂贵,使用不太便利的缺点;另一类就是基于视觉系统的,这类方法通过传感器采集图像信息,然后进行图像的处理和识别过程,给使用者带来了很好的人机交互性,如何提高识别精度和减少识别时间是这类方法一直以来的难点。
近年来,随着计算机图形计算处理能力的显著提高,深度学习在语音识别、图像分类等领域取得了重大突破。深度学习利用多层非线性的深度神经网络对输入的图像或语音信息进行分类处理,能有效的自主提取特征,识别精度高。手语识别作为人机交互的重要组成,对听力障碍人群与计算机或者不懂手语人之间的交流有重要作用。
技术实现要素:
本发明的目的是提供一种识别精度高的汉语手语识别方法。本发明通过卷积神经网络训练汉语手语模型,对汉语手语的实时识别。技术方案如下:
一种基于卷积神经网络的汉语手语识别方法,包括下列步骤:
步骤1,采集汉语手语的各类手势图,经手势分割和预处理获得多张手势样本。
步骤2,将采集到的手势样本数据集按5:1:1的比例分为训练集、验证集和测试集;
步骤3,搭建7层的卷积神经网络cnn模型,包含3层卷积层、2层池化层和1层全连接层,用该cnn模型训练集的手势特征,取每次批处理batchsize的图像数为200,通过最大池化选取每次卷积后的特征;
步骤4,在最后一次卷积层之后,通过softmax函数进行特征向量的分类,分类结果与标签对比并更新模型的权值;
步骤5,对比每次迭代后验证集的准确率,与上一次的验证结果对比,若准确率下降则继续迭代,否则停止迭代。
附图说明
图1本发明采用的卷积神经网络结构图
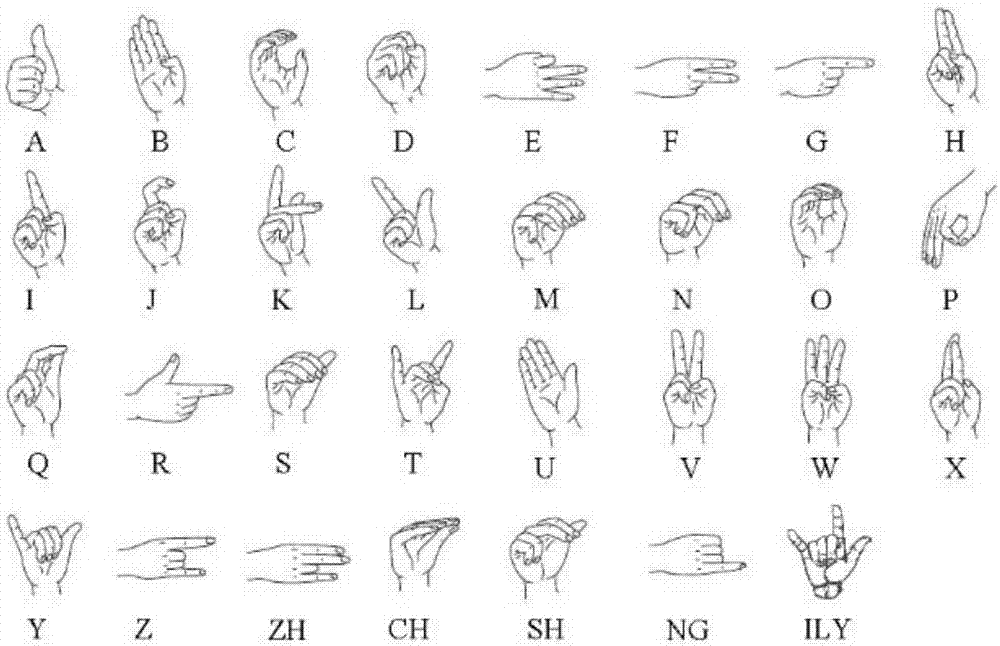
图2输入的31类手势样本
具体实施方式
卷积神经网络网络结构主要由卷积层、池化层和全连接层组成。卷积层也是特征提取层,它通过利用不同的卷积核对输入的图像进行卷积操作来提取图像的不同特征,卷积操作使得卷积核的参数在图像的不同位置共享,可以大大降低模型的参量,减少训练的时间,而且提取的特征与出现的空间位置无关,其表达式如下:
其中,
池化层也叫特征映射层,将每层网络上的多个特征映射为一个平面,和卷积层的操作类似,只是一个平面上的神经元权值相等,表达式如下:
down(·)是采样函数,若n*n代表核大小,则输出的特征图像大小是输入的1/n;f(·)一般采用sigmoid函数;
和lenet-5结构相比,做了一些改进,在池化层,我们采用max-pooling从核大小中选取最大的值作为池化层保留值,相当于选取若干特征值中最大的,抛弃其他较弱的此类特征。这样的优势在于可以保证特征的位置与旋转不变形,强特征在哪个位置出现都能提取出来。另一处的改进在于全连接层中用softmax分类器,通过不删除数据来减少数据中极值或者异常值的影响,它的表达式如下所示:
其中,k代表输出为k维的向量,p(y=j|x)表示y可以去k个不同值得概率。
取汉语手语中31种手势用作实验,通过kinect采集手势图,经过手势分割和预处理过程,得到适合卷积神经网络输入的手势大小,每一类手势取4000张作为训练样本,取800张作为验证样本,另800张作为测试样本。总共173600张手势图构成数据集,包括124000张训练集、24800张验证集和24800张测试集。输入到上述结构的cnn网络中,经过了42次的迭代以后,用测试样本进行测试,得到了表1中各类手势的识别精度,平均的识别精度达到了96.23%。
经过上述结构的神经网络结构训练的模型,能将31类汉语手语分类开来,而且能达到很高的识别精度,满足汉语手语识别的应用要求。
表1用cnn分类的各手势精度
技术特征:
技术总结
本发明涉及一种基于卷积神经网络的汉语手语识别方法,包括下列步骤:采集汉语手语的各类手势图,经手势分割和预处理获得多张手势样本;将采集到的手势样本数据集按5:1:1的比例分为训练集、验证集和测试集;搭建7层的卷积神经网络CNN模型,包含3层卷积层、2层池化层和1层全连接层,用该CNN模型训练集的手势特征,取每次批处理batchsize的图像数为200,通过最大池化选取每次卷积后的特征;在最后一次卷积层之后,通过Softmax函数进行特征向量的分类,分类结果与标签对比并更新模型的权值;对比每次迭代后验证集的准确率,与上一次的验证结果对比,若准确率下降则继续迭代,否则停止迭代。
技术研发人员:吕辰刚;鲍志强
受保护的技术使用者:天津大学
技术研发日:2017.09.23
技术公布日:2018.02.27
- 还没有人留言评论。精彩留言会获得点赞!