信息估计装置和信息估计方法与流程
本发明涉及用于使用神经网络来执行估计过程的信息估计装置和信息估计方法。本发明特别涉及在神经网络中提供退出(dropout)层以获得表示估计结果的置信区间的方差的信息估计装置和信息估计方法。
背景技术:
与其他估计器相比,使用神经网络(nn)的估计器可以将大量信息(诸如图像和传感器信号数据)作为输入数据来处理以执行估计,并且所以预期在各个领域中被使用。
神经网络具有在其中布置用于处理数据的层的结构。数据被供应到每个层并且在层中服从于计算集,并且然后输出经处理的数据。详细地,首先将来自被观测对象的输入数据供应给神经网络的输入层,进行处理并输出。然后将数据作为输入数据供应给按顺序的后续层(中间层),进行处理并输出。因此重复执行每个层中的过程以将数据传播到神经网络中。最终从作为最后一层的输出层输出的数据是估计结果。来自被观测对象的输入数据是要被估计的观测目标的n维向量数据。例如,对于10像素乘10像素的单色相机图像的输入数据是10×10=100维(即n=100)的向量数据,其具有与相应像素相对应的元素。
神经网络中的每个层可以被设置成使得输入向量数据的维数和输出向量数据的维数是彼此不同的。换言之,当向量数据经过每个层时向量数据的维数可以增加或减小。此外,从输出层输出的向量数据的维数根据设计者想估计什么而改变。例如,在估计诸如“速度”或“得分”之类的值的情况下,来自输出层的输出是n=1维标量数据。在将输入图像分类为“步行者”、“汽车”和“自行车”中的任一类的情况下(即在执行3类分类的情况下),来自输出层的输出是存储指示输入图像对应于三类中的哪一类的“得分”的n=3维的向量数据。
由用于使用神经网络来执行估计过程的估计器所执行的过程包括学习阶段和估计阶段。
在学习阶段中,设计者准备训练数据并且促使神经网络学习神经网络中的神经元权重以使得在使用训练数据的情况下从具有特定模式的输入数据产生期望的特定输出。
在估计阶段,将未知的新数据(即测试数据)供应给具有在学习阶段中学习以用来执行估计的规则的神经网络。如果学习已成功,则神经网络根据学习的概念来产生估计结果。
使用神经网络的常规估计器与使用概率性方法(诸如贝叶斯估计)的其他估计器的主要差别是在神经网络中,估计结果仅被输出为“值”,并且不能计算表示估计结果的置信区间的方差。
因此,不能在神经网络中计算表示置信区间的方差。这使得难以例如设置阈值并且仅采用不低于预定级别的可靠估计结果,因为错误确定的可能性可能很高。例如,在要求高安全性的环境中使用神经网络的情况下(诸如当估计汽车的周边环境时),如果估计结果包含错误确定则可能会接着发生严重的事故。
下面列出的非专利文献1提出一种在神经网络中计算输出值以及其方差的方法。下面描述在非专利文献1中公开的计算方法。
在非专利文件1的方差计算方法中,在估计期间还使用通常用来防止学习期间的过拟合的退出,来计算估计结果的方差。退出是一种在神经网络的各层中提供退出层并且利用由设计者提前设置的概率pdrop将供应给退出层的输入向量数据的每个元素独立地设置成零的技术,如作为一个示例在专利文献1中公开的那样。
例如,假定输入向量数据具有100维,即由100个元素组成。每个元素都独立地服从于是否将包括在元素中的值设置成零(概率为pdrop)的确定(在不将值设置为零的情况下不改变原始元素中的值)。从统计上来说这导致来自100个元素之中的100×pdrop个元素为零。因此,退出促使要在对应于概率pdrop的数目的元素缺失(设置成零)的状态中执行计算。
在学习期间,计算权重以便最小化在具有概率pdrop的元素缺失的状态中获得的输出结果与期望的正确解数据的差。在学习期间该计算被重复许多次。详细地,供应给退出层的另一向量数据的每个元素独立地服从于是否将包括在元素中的值设置成零(概率为pdrop)的确定,针对处在对应于概率pdrop的数目的元素缺失的状态中的其他向量数据执行计算,并且计算权重以便最小化与期望正确解数据的差。通过以这种方式使用对于输入向量数据的退出来重复执行学习,神经网络学习能够输出与估计结果相同的正确解数据,而不管向量数据的哪些元素缺失。
使用退出的该计算方法常规上仅在学习期间被采用。换言之,常规上已经在学习期间使用退出,但是没有在估计期间使用。
非专利文献1介绍一种技术,通过该技术也在估计计算期间对来自同一对象的输入向量数据重复执行涉及退出的计算多次来获得输出值以及其方差。使用退出的此类估计在非专利文献1中被称为蒙特卡洛(mc)退出。归因于元素缺失,在每个估计计算处在退出层中以概率pdrop将输入向量数据的元素组设置成零的模式是不同的,以使得在通过后续层之后的最后估计结果每次也是不同的。在此说明书中,对于向量数据的每个输入的输出估计结果不同的现象也被称为估计结果的“波动”。
图1a示出通过执行计算一次获得的输出值,并且图1b示出通过重复执行计算多次获得的输出值的分布。在图1a中,在图表上画出通过执行计算一次获得的输出值(该图表的水平轴指示值)。在图1b中,在图表上画出通过执行计算多次(在该示例中10次)获得的输出值(该图表的水平轴指示值,并且垂直轴示意性地指示频率)。
图1c示出通过计数获得的作为频率的对于每个值在图1b中示出的输出值的分布的直方图。在图1c中,通过指示输出值的量值(水平轴)和频率(垂直轴)之间的关系的直方图来表示图1b中示出的分布。以这种方式执行许多实验使得有可能获得输出值分布。图1c还示出估计的概率密度分布的图表(在图1c中用虚线示出的图表)、均值和由统计处理产生的估计的方差。在此说明书中,以这种方式执行许多实验来找出概率密度分布也被称为“以蒙特卡洛方式的计算”。
在非专利文献1中,执行计算mc次以收集最终输出向量数据的mc(约200或更少)个值(它们每次都变化),并且根据下面的表达式来计算这些值的方差。根据该表达式产生的方差被定义为关于输入数据的不确定性。
在该表达式中,x*是输入,y*是输出,t是计算的次数(即t=mc),并且左侧是输出y*的方差。如在表达式中示出的,左侧(方差)被表示为与初始方差有关的常数项τ-1id(右侧的第一项)和从输出y*的方差(右侧的第二项)减去输出y*的均方(右侧的第三项)的结果。
这样的计算被直观地表示如下。对于同一对象的神经网络的估计被计算多次。在每次计算处,输入向量数据到退出层的值都被随机设置成零以便在向量数据的元素组中随机地创建缺失元素,因此有意地使来自退出层的输出数据波动。如果从输出层输出的最终估计结果不波动(即方差小),甚至在如上面提到的有意地使来自退出层的输出数据波动的情况下,神经网络可以被视为产生具有高可靠性的估计。如果从输出层输出的最终估计结果波动大(即方差大),则神经网络可以被视为产生具有低可靠性的估计。
[专利文献1]国际公开wo2014105866a1。
[非专利文献1]“dropoutasabayesianapproximation:representingmodeluncertaintyindeeplearning”,yaringal,zoubinghahramani:2015年6月6日(可从https://arxiv.org/pdf/1506.02142v1.pdf得到)。
[非专利文献2]“onthevarianceofthesamplemeanfromfinitepopulation”,syedshakiralighazali,journalofscientificresearch,卷xxxiv2号:2005年10月。
技术实现要素:
然而,为了获得对于一个观测目标的方差,如上面提到的在神经网络中的退出层之后的计算需要重复执行多次。例如,计算需要被执行mc(约200或更少)次。在计算的次数被减少的情况下,所获得的输出值的概率密度分布不具有平滑的分布轮廓,这使得难以准确地估计方差。另一方面,在计算的次数增加的情况下,更准确的方差估计是可能的,但是大量的计算要求计算过程中的时间和劳力。这在实际使用中造成了沉重的计算负担。
为了解决上面提到的问题,本发明具有提供用于使用神经网络来执行估计过程的信息估计装置和信息估计方法的目的,利用其可以在没有大量计算的情况下稳定且快速地计算作为估计结果的置信区间的方差。
为了实现上面阐述的目的,本发明还提供一种用于使用神经网络来执行估计过程的信息估计装置,该神经网络包括组合了用于退出输入数据的一部分的退出层和用于计算权重的fc层的集成层,该信息估计装置包括:数据分析单元,其被配置成基于由去到具有多变量分布的集成层的输入数据的每个向量元素与权重的相应积形成的项的数值分布来确定来自具有多变量分布的集成层的输出数据的每个向量元素的数据类型;以及估计的置信区间计算单元,其被配置成将与由数据分析单元确定的数据类型相关联的近似计算方法应用于集成层中的计算,以便基于去到集成层的输入数据解析地计算来自集成层的输出数据的每个向量元素的方差。
为了实现上面阐述的目的,本发明提供一种用于使用神经网络来执行估计过程的信息估计方法,该神经网络包括组合了用于退出输入数据的一部分的退出层和用于计算权重的fc层的集成层,该信息估计方法包括:数据分析步骤,其基于由去到具有多变量分布的集成层的输入数据的每个向量元素与权重的相应积形成的项的数值分布来确定来自具有多变量分布的集成层的输出数据的每个向量元素的数据类型;以及估计的置信区间计算步骤,其将与在数据分析步骤中确定的数据类型相关联的近似计算方法应用于集成层中的计算,以便基于去到集成层的输入数据解析地计算来自集成层的输出数据的每个向量元素的方差。
本发明涉及一种使用神经网络的估计技术,并且具有稳定且快速地计算作为估计结果的置信区间的方差的有利效果。本发明因此加速并促进通过神经网络确定估计结果的可靠性。此外,例如,可以根据可靠性来确定是否采用估计结果以及是否将估计结果与通过贝叶斯估计等等产生的另一估计结果合并。这大大拓宽了神经网络的应用范围。
附图说明
图1a是示出通过使用神经网络的常规估计器获得的且通过执行计算一次获得的输出值的图表。
图1b是示出通过使用神经网络的常规估计器获得的且通过执行计算多次获得的输出值的图表。
图1c是示出通过执行计算多次获得的图1b的输出值的直方图的图表。
图2是示出本发明的实施例中的信息估计装置的结构的一个示例的框图。
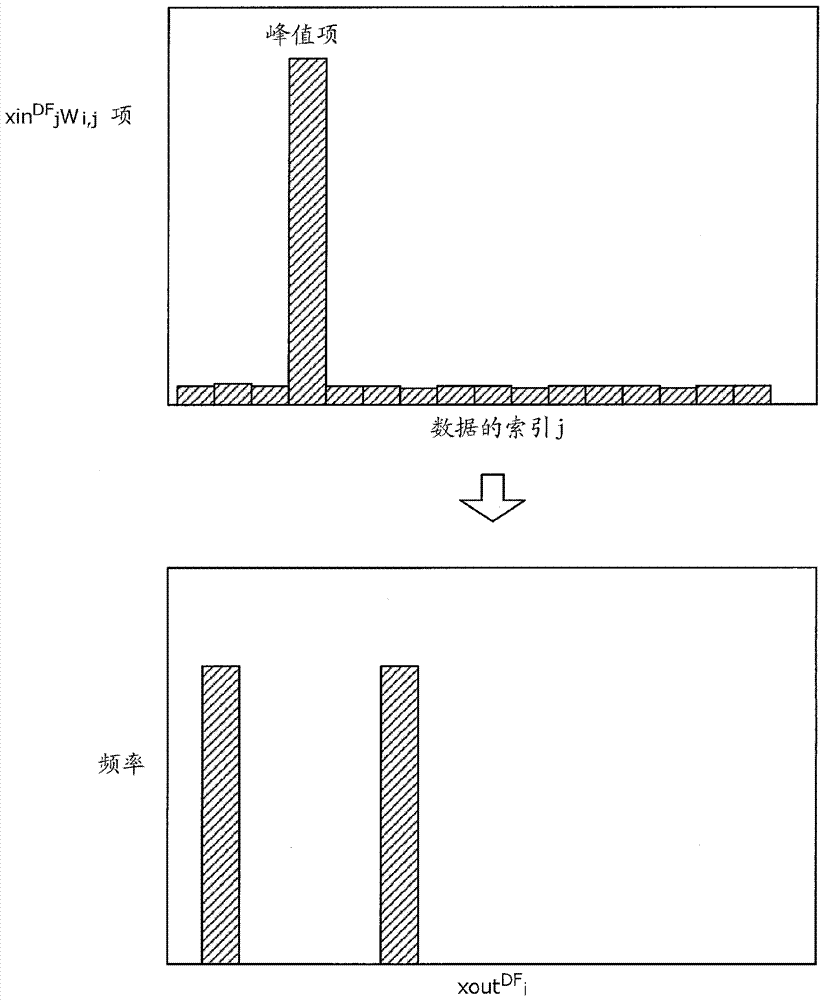
图3图示关于“类型2”的条形图和直方图,上部图示示出绘制对于“类型2”中的每个索引j的xindfjwi,j项的值的一个示例的条形图,并且下部图示示出在从具有上部中示出的趋势的xindfjwi,j项的值获得的xoutdfi的值被计算多次的情况下xoutdfi的一个示例的直方图。
图4图示关于“类型1”的条形图和直方图,上部图示示出绘制对于“类型1”中的每个索引j的xindfjwi,j项的值的一个示例(峰值项的数目是1)的条形图,并且下部图示示出在从具有上部中示出的趋势的xindfjwi,j项的值获得的xoutdfi的值被计算多次的情况下xoutdfi的一个示例的直方图。
图5图示关于“混合类型”的条形图和直方图,上部图示示出绘制对于“混合类型”中的每个索引j的xindfjwi,j项的值的一个示例(峰值项的数目是1)的条形图,并且下部图示示出在从具有上部中示出的趋势的xindfjwi,j项的值获得的xoutdfi的值被计算多次的情况下xoutdfi的一个示例的直方图。
图6图示关于“类型1”的条形图和直方图,上部图示示出绘制对于“类型1”中的每个索引j的xindfjwi,j项的值的一个示例(峰值项的数目是2)的条形图,并且下部图示示出在从具有上部中示出的趋势的xindfjwi,j项的值获得的xoutdfi的值被计算多次的情况下xoutdfi的一个示例的直方图。
图7图示关于“混合类型”的条形图和直方图,上部图示示出绘制对于“混合类型”中的每个索引j的xindfjwi,j项的值的一个示例(峰值项的数目是2)的条形图,并且下部图示示出在从具有上部中示出的趋势的xindfjwi,j项的值获得的xoutdfi的值被计算多次的情况下xoutdfi的一个示例的直方图。
图8a是示出通过本发明的实施例中的信息估计装置的过程的一个示例的流程图。
图8b是示出图8a中的步骤s14中的数据分析和计算过程的一个示例的流程图。
图8c是示出图8b中的步骤s143中的类型确定和计算过程的一个示例的流程图。
图9是示出在与本发明的实施例有关的实验中使用的神经网络的结构的一个示例的示图。
图10a是示出通过神经网络的功能的一个示例的图表并且示出实验的结果和通过常规技术获得的结果。
图10b是示出在尝试集成层的输出值xoutdfi多次的情况下值的一个示例的图表并且示出实验的结果和通过常规技术获得的结果。
具体实施方式
下文参见绘图描述本发明的实施例。首先解释神经网络的每个层中的过程和符号,它们是本发明的实施例的描述所必需的。
神经网络由许多层组成。供应给每个层的输入数据服从于在层中定义的计算过程,并且将处理结果输出为输出数据。该输出数据被作为去到下一层的输入数据供应给下一层。在下一层中,该数据同样服从于在该层中定义的计算过程,并且将处理结果输出为输出数据。因此按顺序在层中重复执行输入、计算和输出,以便在神经网络中传播数据。最终,估计结果从输出层输出。
在此说明书中,假设去到神经网络的给定层i的输入数据是nxinl维随机可变向量xinl,并且来自层i的输出数据是nxoutl维随机可变向量xoutl,它们被写出如下。在此说明书中,nxinl表示n的下标是xinl,并且nxoutl表示n的下标是xoutl。
根据具有任何复杂轮廓的多变量分布的密度函数hinl和houtl,这些随机可变向量xinl和xoutl被表述如下。
例如,如果概率密度函数hinl和houtl是高斯分布,则应用下面的表达式。
在这里,μxinl是表示均值的nxinl维向量,并且σxinl是大小为nxinl×nxinl的方差-协方差矩阵。同时,μxoutl是表示均值的nxoutl维向量,并且σxoutl是大小为nxoutl×nxoutl的方差-协方差矩阵。在此说明书中,μxinl表示μ的下标是xinl,σxinl表示σ的下标是xinl,μxoutl表示μ的下标是xoutl,σxoutl表示σ的下标是xoutl。
根据本发明,总概率定律被用来通过m条件概率密度分布的混合来表示每个概率密度,如下所示。
所有条件的概率的总和为1,并且表述如下。
作为一个示例,如果多变量分布hinl和houtl中的每个都是条件多变量高斯分布高斯的混合,则应用下面的表达式。
在这里,“遵循多变量分布的随机变量”的数据xinl或xoutl简单地意指“以一般形式表述”的数据。这覆盖以下各项:在“单”变量分布的情况下,数据可以是1维变量,nxinl=1,nxoutl=1。在方差-协方差σxinl、σxoutl为零的情况下,数据可以是固定值并且不是随机变量。
接下来简要地描述如何在神经网络的每层中计算这样的多变量分布数据。在下面单独地描述每层的过程。
<退出层d中的计算过程>。
下面描述退出层d中的计算过程。令去到退出层d的输入数据是nxind维随机可变向量xind,并且来自退出层d的输出数据是nxoutd维随机可变向量xoutd。在此说明书中,nxind表示n的下标是xind,并且nxoutd表示n的下标是xoutd。
使用指示符函数z={0,1}来表述退出。在这里,z是遵循如下面所述的伯努里分布的随机变量,在这里z=0具有退出概率pdrop,并且z=1具有不退出概率(1-pdrop)。使输入数据xind的nxind个元素中的每一个都乘以z(其被独立地设置成z=0或z=1)。因为总的和值会因为退出而下降,所以通过乘以给定常数c来使总值的标度增加。
<完全连接的(fc)层f中的计算过程>。
下面描述完全连接的(fc)层f中的计算过程。令去到fc层f的输入数据是nxinf维随机可变向量xinf,并且来自fc层f的输出数据是nxoutf维随机可变向量xoutf。在此说明书中,nxinf表示n的下标是xinf,并且nxoutf表示n的下标是xoutf。
fc层f的参数定义如下。令wf(大小:nxoutf×nxinf)是表示权重的矩阵,并且bf(大小:nxoutf×1)是表示偏差的向量。假设已经在学习阶段中得到它们的最优值。
使用下面的表达式来执行根据fc层f中的输入数据xinf计算输出数据xoutf的过程。
<激活层a中的计算过程>。
下面描述激活层a中的计算过程。令去到激活层a的输入数据是nxina维随机可变向量xina,并且来自激活层a的输出数据是nxouta维随机可变向量xouta。在此说明书中,nxina表示n的下标是xina,并且nxouta表示n的下标是xouta。
激活函数例如是s形函数或纠正线性单元(relu)函数。当将激活函数表示为函数f时,使用下面的表达式来执行根据激活层a中的输入数据xina来计算输出数据xouta的过程。
<退出层d→fc层f中的计算过程>。
在如稍后描述的下面这样的情况下执行根据本发明的特征过程:作为遵循多变量分布的随机变量的输入数据经过上面提到的退出层d,进入某一fc层f,并且最终经过激活层a。假设将集成退出层d和fc层f的层(具有退出的fc层f)作为集成层df,下面描述集成层df中的过程。
如下面所示的,令去到集成层df的输入数据是nxindf维随机可变向量xindf,并且来自集成层df的输出数据是nxoutdf维随机可变向量xoutdf。在此说明书中,nxindf表示n的下标是xindf,并且nxoutdf表示n的下标是xoutdf。
在该集成层df中,根据输入数据xindf来计算输出数据xoutdf的过程包括集成层df的退出层d的一部分中的计算和集成层df的fc层f的一部分中的计算。详细地,根据下面的表达式来执行集成层cf中的计算。
为了简单起见,可以将对于退出的标度调整中乘以的给定常数c假设成并入权重wdf。
特别地,如下表示xoutdf中的第i个元素xoutdfi(1≤i≤nxoutdf):
这是在最后向其添加偏差项bi的项xindfjzjwi,j(1≤j≤nxindf)的列表的总和。在该表达式中包括两种类型的随机变量xindfj和zj,其中剩下的是固定值。
随机变量xindfj是从具有集成层df前面的层中的退出的柏努利分布的变换导出的输入数据,并且根据前一层的结构采用任何分布。随机变量zj从该集成层df中的退出导出,并且是柏努利分布,其中zj={0,1}中的zj=0具有概率pdrop。因此这两种类型的随机变量是独立的。
考虑计算xoutdfi的值的情况。如上面提到的,xindfjzjwi,j项的数目是nxindf(1≤j≤nxindf),并且每个项中的zj都可以独立地采用zj=0或zj=1。因此,存在关于xindfjwi,j项的nxindf个中的每一个是否对总和作出贡献的大量分支,以使得可乘以作为该项的和的xoutdfi的值最大具有2^nxindf个变化(2的nxindf次方)。在退出的情况下计算xoutdfi多次导致具有2^nxindf种类型的值的离散散射的波动的分布。
典型的神经网络具有大约nxindf=1024个神经元数目,并且所以需要计算21024个总和。这样的计算要求巨大的处理,并且在实践时间内不能完成。
本发明提出一种通过使用解析方法来利用一个计算过程计算方差的技术(按照惯例计算方差需要大量的计算过程),因此不必要执行大量计算过程。根据本发明,归因于退出在每个计算处波动的输出数据的值被视为“随机变量”。通过确定从其导出随机变量的原始“概率密度分布”,有可能直接发现概率密度分布的分布轮廓随着每个层中的计算过程如何变化。因此,确定从输出层输出的数据的概率密度分布的分布轮廓以及计算其方差使得能够获得估计结果的置信区间,即方差。
<信息估计装置10的结构>。
下面参考图2描述本发明的实施例中的信息估计装置(用于使用神经网络来执行估计估计过程的估计器)的结构。图2是示出本发明的实施例中的信息估计装置的结构的一个示例的框图。图2中示出的信息估计装置10包括估计的置信区间计算单元20和数据分析单元30。该信息估计装置10是使用具有退出层的神经网络的估计器,并且具有不仅仅获得估计结果而且还获得估计的可能方差的函数。
在本发明的实施例中的装置结构的描述中使用的框图仅仅表示与本发明有关的函数,并且该函数实际上可以通过硬件、软件、固件或其任何组合来实施。可以将通过软件实施的函数作为可由基于硬件的处理单元(诸如中央处理单元(cpu))执行的一个或多个指令或代码存储在任何计算机可读介质中。可以通过包括集成电路(ic)和ic芯片集的各种设备来实施与本发明有关的函数。
估计的置信区间计算单元20被配置成除了如在常规神经网络中那样对每个层中的输入数据执行计算过程并且输出估计结果之外,还计算关于输入数据传播通过并且作为退出的结果从每个层输出的分布的分布轮廓,并且计算作为置信区间的从最终输出层输出的方差。如果从最终输出层输出的估计结果的方差大,则估计结果大幅波动,也就是说其可靠性低。如果方差小,则估计结果的可靠性高。估计的置信区间计算单元20特别具有执行与由数据分析单元30确定的近似计算方法相对应的近似计算(例如与下面提到的“类型1”、“类型2”和“混合类型”中的任意相对应的近似计算)的函数,以计算数据的分布轮廓。
例如,估计的置信区间计算单元20能够执行以下过程:将与由数据分析单元30确定的数据类型相关联的近似计算方法应用于集成层df中的计算以由此基于去到集成层df的输入数据来解析地计算来自集成层df的输出数据的每个向量元素的方差。
该数据分析单元30被配置成分析在神经网络的每个层中计算并且从该每个层输出的数据的属性,确定用于计算其分布的最优近似计算丰富(数据类型确定),以及向估计的置信区间计算单元20告知近似计算方法。该数据分析单元30特别具有分析去到集成层df的输入数据、组合神经网络中的退出层d和fc层f、以及向估计的置信区间计算单元20告知对于输入数据的最优近似计算方法(例如下面提到的“类型1”、“类型2”和“混合类型”中的任一个)的函数。
例如,该数据分析单元30能够执行以下过程:基于由去到具有多变量分布的集成层df的输入数据的每个向量元素与权重的相应积形成的项的数值分布来确定来自具有多变量分布的集成层的输出数据的每个向量元素的数据类型。
下面详细描述估计的置信区间计算单元20和数据分析单元30中的过程。
<数据分析单元30中的过程>。
首先描述数据分析单元30中的过程。在集成层df中,如上面提到的,基于输入数据xindf来计算输出数据xoutdf。xoutdf中的第i个元素xoutdfi(1≤i≤nxoutdf)表达如下。
该数据分析单元30分析从包括在xoutdf的第i个元素xoutdfi中的nxindf个xindfjzjwi,j项之中排除zj的xindfjwi,j项(1≤j≤nxindf)的属性。
下面参考图3到7描述包括在xoutdf的第i个元素xoutdfi中的xindfjwi,j项(1≤j≤nxindf)的属性。在图3到7的每一个中,上部的条形图示出绘制对于每个索引j的xindfjwi,j项的值的状态,并且下部的直方图示出在从具有上部中示出的趋势的xindfjwi,j项的值获得的xoutdfi的值被计算多次的情况下归因于随机变量zj={0,1}的变化而波动的xoutdfi的值的分布状态。换言之,下部的直方图通过频率示出在以蒙特卡洛方式计算xoutdfi多次的情况下哪个值被频繁地产生。该直方图因此示出xoutdfi的可能概率密度分布。在图3到7的每一个中,上部的条形图中的水平轴指示索引j并且上部的条形图中的垂直轴指示xindfjwi,j项的值,并且下部的直方图中的水平轴指示xoutdfi的值并且下部的直方图中的垂直轴指示频率。
实际上,xindfj是另一独立随机变量。然而,例如,可以用xindfj的均值μxindfj来替换xindfj,以使得xindfjwi,j项的值被视为μxindfjwi,j的固定值。在此说明书中,μxindfj表示μ的下标是xindfj。
该数据分析单元30分析nxindf个xindfjwi,j项(1≤j≤nxindf)中的每一个的绝对值|xindfjwi,j|。在此说明书中,具有比其他项异常大的绝对值的项被称为“峰值项”,并且其他项被称为“非峰值项”。例如,该数据分析单元30计算所有nxindf个xindfjwi,j项(1≤j≤nxindf)的标准偏差σμw,并且将大于或等于通过用σμw乘以由设计者提前设置的预定数(比值dratio)而获得的值σμwdratio的任何xindfjwi,j项视为异常峰值项。例如,假定xindfjwi,j项的值被视为μxindfjwi,j的固定值。然后,通过下面的表达式来定义对于异常峰值项的条件。
计算来自nxindf个μxindfjwi,j项(1≤j≤nxindf)的满足该条件的所有峰值项。在这些峰值项中,具有更大异常的(由设计者提前设置的)预定数目(例如若干个,诸如5个)的峰值项的被存储为峰值列表。在这里,该预定数目指示被存储为峰值列表的峰值项的最大数目。可能存在很多峰值项,或仅几个峰值项或没有峰值项。例如,在峰值项的数目少于预定数目的情况下,比预定数目更少的峰值项被存储为峰值列表。在峰值项的数目多于预定数目的情况下,按异常的降序排列提取预定数目的峰值项,并且将其存储为峰值列表。在下文中用npeak(npeak<<nxindf)来表示存储为峰值列表的峰值项的数目。在这里,npeak采用小于或等于预定数目(存储为峰值列表的峰值项的最大数目)的值。在不存在峰值项的情况下,如稍后所述的那样来确定“类型2”,并且不需要存储峰值列表。
<“类型1”的确定>。
在峰值项是几个(总共npeak)并且其他剩余数目(nxindf-npeak)的项的值小到足以被认为是零的情况下,该数据分析单元30确定“类型1”。这是xindfjwi,j项的值的分布,在其中几个(总共npeak)项突出就像δ函数的峰值且其他剩余数目(nxindf-npeak)的项基本上是零。
图4和图6的上部的每个都示出在这种情况下xindfjwi,j项的值的状态。在图4的上部中,xindfjwi,j项中的一个项(一个峰值项)具有大的值,并且其他项的值小到足以被认为是零。在图6的上部中,xindfjwi,j项的两个项(两个峰值项)中的每个都具有大的值,并且其他项的值小到足以被认为是零。
在xoutdfi被确定为“类型1”的情况下,估计的置信区间计算单元20仅考虑这些异常峰值项(即npeak个xindfjwi,j项),而将剩余的项近似为零。估计的置信区间计算单元20因此可以通过仅检查这些峰值项的2^npeak个分支组合来计算xoutdfi的分布,其中不需要检查所有2^nxindf个分支。稍后将描述在“类型1”中通过估计的置信区间计算单元20的分布计算方法。
各种方法都可用于确定剩余(nxindf-npeak)数目的项是否小到足以被认为是零,并且不对确定方法进行限制。作为一个示例,计算剩余(nxindf-npeak)数目的项的分布的均值和方差,而不是计算npeak个峰值项的分布的均值和方差。在满足均值小于第一预定值(靠近零)且方差小于第二预定值(小变化)的条件的情况下,可以将除峰值项以外的剩余(nxindf-npeak)数目的项确定为小到足以被认为是零。在不满足该条件的情况下,可以将除峰值项以外的剩余(nxindf-npeak)数目的项确定为没有小到足以被认为是零。
<“类型2”的确定>。
在不存在峰值项的情况下,该数据分析单元30确定“类型2”。简单来讲,这是所有xindfjwi,j值都整体类似没有任何明显异常的情况(诸如均匀分布或高斯分布)。
图3的上部示出在这样的情况下xindfjwi,j项的值的状态。在其中xoutdfi被确定为“类型2”的情况下,中心极限定理成立。估计的置信区间计算单元20可以在不需要检查2^nxindf个分支的情况下通过将总和分布视为统计上的一个整体的高斯分布来计算xoutdfi的分布。稍后将描述在“类型2”中通过估计的置信区间计算单元20的分布计算方法。
<“混合类型”的确定>。
实际上,上面提到的“类型1”属性和“类型2”属性常常是混合的,如在图5和图7的上部中的每一个中示出的xindfjwi,j项的值的状态中那样。这是在其中存在一个或多个异常项(诸如峰值项)并且除峰值项以外的剩余(nxindf-npeak)数目的项没有小到足以被认为是零的情况。
在图5的上部中,xindfjwi,j项中的一个项(一个峰值项)具有大的值,并且其他项的值没有小到足以被认为是零。在图7的上部中,xindfjwi,j项的两个项(两个峰值项)中的每个都具有大的值,并且其他项的值没有小到足以被认为是零。
在此类情况下,该数据分析单元30确定“混合类型”,其是“类型1”和“类型2”的混合。在“混合类型”中,估计的置信区间计算单元20首先获取假设为“类型1”的峰值项,并且不是将这些值视为随机变量而是视为条件固定值(例如μxindfjwi,j)。关于除了峰值项之外的剩余(nxindf-npeak)数目的项,估计的置信区间计算单元20可以计算假设有条件的“类型2”的分布。稍后将描述在“混合类型”中通过估计的置信区间计算单元20的分布计算方法。
接下来描述估计的置信区间计算单元20中的过程。下面详细地描述在由数据分析单元30确定的“类型1”、“类型2”和“混合类型”的每一个中通过估计的置信区间计算单元20的分布计算方法。
<“类型1”中的分布计算方法>。
首先描述“类型1”中的分布计算方法。在数据分析单元30将集成层df中计算的xoutdf的第i个元素xoutdfi中包括的xindfjwi,j项的属性确定为“类型1”的情况下,估计的置信区间计算单元20仅使用存储为峰值列表的npeak个峰值项来计算xoutdfi的分布。
首先,考虑在其中峰值项的数目为1(即npeak=1)的最简单的情况。在这种情况下,xindfjwi,j项的值例如处于图4的上部中示出的状态。
假定xoutdfi中的j=第peaki个项(1≤peaki≤nxindf)是异常的。当用xindfpeakizpeakiwi,peaki来表示该峰值项时,xoutdfi被表述如下。在此说明书中,xindfpeaki表示xindf的下标是peaki,zpeaki表示z的下标是peaki,并且wi,peaki表示w的下标是i,peaki。
关于排除这些项的zj的xindfjwi,j项,在xindfjwi,j项中的一个项(j=第peaki个项)具有大的值且其他项小到足以被视为零的情况下(作为一个示例如图4的上部中示出的那样),xoutdfi被表述如下:
因为随机变量zpeaki={0,1},所以如下面示出的xoutdfi具有带有两个分支的值。
当使用δ函数并且简化x=xoutdfi时,该表达式给出的xoutdfi所遵循的概率密度函数如下。
图4的下部示出该概率密度函数的轮廓。这是与由实际上以蒙特卡洛方式计算xoutdfi多次得到的结果的值的直方图相同的结果。
同样地,在峰值项的数目是2或更多的情况下可以使用δ函数。在xindfjwi,j项中的两个项(两个峰值项)中的每个都具有大的值且其他项小到足以被视为零的情况下(作为一个示例如图6的上部中示出的那样),xoutdfi的概率密度函数具有在图6的下部中示出的轮廓。在这种情况下,存在两个峰值项,对于这两个峰值项中的每一个都存在是否选择峰值项的两种情况。因此,如图6的下部中所示的那样,xoutdfi的概率密度函数被计算为22=4个δ函数。这是与由实际上以蒙特卡洛方式计算xoutdfi多次得到的结果的值的直方图相同的轮廓。
<“类型2”中的分布计算方法>。
接下来描述“类型2”中的分布计算方法。如在上面提到的情况中那样,对应于输入xindf的输出xoutdf的第i个元素xoutdfi被表述如下:
在“类型2”中,从xoutdfi项之中排除zj的xindfjwi,j项的值处在图3的上部中示出的状态。因为在“类型2”中所有xindfjwi,j的值是类似的,根据中心极限定理,这可以被看作当输出数据的向量xoutdf中的每个元素xoutdfi(1≤i≤nxoutdf)的值随着随机变量zj={0,1}波动时形成高斯分布。在统计学中这可以被计算为“样本和误差的波动”。下面描述这怎么被视为“样本和误差的波动”。
假定xindfj不是随机变量,而仅仅是固定值μxindfi。zj是柏努利分布的随机变量。如先前提到的,假定zj=0的概率为pdrop,并且否则zj=1,xoutdfi中的xindfjzjwi,j项的和的一部分可以被解释为样本和,其是“当从总体(population)(其是n=nxindf个xindfjwi,j(1≤j≤nxindf)项的集合)采样均值m=n×(1-pdrop)个xindfjwi,j项时的和”。
因此,xoutdfi是通过将偏差项bi加到该和而获得的值。每次该采样被执行,就会选择m个不同的xindfjwi,j,并且在形成分布函数时作为m个不同xindfjwi,j的和的xoutdfi的值每次都变化。这是“样本和误差的波动”。
在“类型2”中,在nxindf个xindfjwi,j(1≤j≤nxindf)项中不包括异常峰值项。因此,nxindf个xindfjwi,j(1≤j≤nxindf)项的值随着总体的分布在峰度和偏斜度方面是弱的,以使得根据李雅普诺夫定理中心极限定理成立。在每次采样波动的和值xoutdfi因此可以被视为高斯分布,如在图3的下部中示出的。
因为xoutdfi的分布可以被视为如上所述的高斯分布,所以一旦其均值e[xoutdfi]和方差var(xoutdfi)是已知的就可以识别分布轮廓。
在中心极限定理成立的情况下,方差通常被称为“样本和误差的方差”,并且可以根据如在非专利文献2中描述的以下表达式来解析计算该方差。
在此处,varpopulation是总体的nxindf个xindfjwi,j(1≤j≤nxindf)项的方差,在这里zj=1。
同时,如下简单地获得均值μdfi。
因为xindfj是固定值μxindfj,所以可以根据下面的表达式来计算均值μdfi。
通常,假定xindfj不是μxindfj而是多变量分布的随机变量,将非专利文献2中的表达式进一步展开,以使得在总体的值的随机变量也遵循多变量分布的情况下和的变量被表述如下。此说明书的结尾处的补充说明1中给出了该表达式的证明。还在补充说明2中描述了协方差计算方法。
因为该方差是高斯分布,所以数据输出值xoutdfi的概率密度函数被表述如下。
在本发明的实施例中,中心极限定理成立的情况是“类型2”,与“类型1”的区别在于,在“类型1”处中心极限定理不成立。主要在去到靠近神经网络的最终输出层的集成层df的输入数据中发现“类型2”。
<“混合类型”中的分布计算方法>。
接下来描述“混合类型”中的分布计算方法,该“混合类型”是“类型1”和“类型2”的混合。
在“类型1”和“类型2”被混合的情况下实际上存在以下实例:排除zj的xindfjwi,j项、几个项(即npeak(npeak<<nxindf)个项)具有比其他值异常地更大的绝对值并且其他剩余(nxindf-npeak)数目的项不能被视为零。在这些实例中,不能通过如在“类型1”中那样仅重点关注来自2^nxindf个分支之中的几个分支,或者通过如在“类型2”中那样将xindfjzjwi,j项的和综合地视为高斯分布来计算该分布。
在这种情况下,在本发明的实施例中,首先将属性看作“类型1”以便提取峰值项并识别关于峰值项组合的分支,并且然后根据有条件的“类型2”针对每个分支执行计算。在下面描述这一点。
首先,考虑在其中峰值项的数目为1(即npeak=1)的最简单的情况。如在前述情况中那样,在这里关心以下输出数据的向量xoutdf的第i个元素xoutdfi。xoutdfi被表述如下:
在这里,假定如在“类型1”中那样仅xoutdfi中的j=第peaki个项(1≤peaki≤nxindf)是异常大的,则用xindfpeakizpeakiwi,peaki来表示该项。从这些项之中排除zj的xindfjwi,j项的值作为一个示例处在图5的上部中示出的状态中。
如果该峰值项xindfpeakizpeakiwi,peaki不是随机变量而是固定值,则然后剩余项xindfjzjwi,j(1≤j,j≠peaki≤nxindf)可以被视为如在“类型2”中那样不包括异常值。
因此,如在“类型1”中,对于异常峰值项xindfpeakizpeakiwi,peaki,分开考虑该项被选择(zpeaki=1)的情况和该项不被选择(zpeaki=0)的情况。然后在这些情况中的每一个中计算常规“类型2”。
如下面所示的那样将xoutdfi的表达式分成两个部分。
在这里
在此处,xwdfi是(nxindf-1)个xindfjzjwi,j项的和的一部分(其根据排除峰值项的zj={0,1}而变化),并且是随机变量。同时,biasdfi包括峰值项和偏差项,并且是固定值。
当zpeaki=1时(即当峰值项xindfpeakizpeakiwi,peaki被选择时),p(zpeaki=1)=1-pdrop,并且上面提到的两部分被表述如下:
这些指示如在“类型2”中那样从有限数目的xwdf项的总体进行采样并且计算它们的和。在这种情况下该总体是n=(nxindf-1)个xindfjwi,j项(1≤j,j≠peaki,j≤nxindf-1),用varpopulation来表示其方差。该计算可以被视为从总体采样均值m=n(1-pdrop)–1个项。
如上面提到的,如下所示在形成均值μ1dfi和方差-协方差σ1dfi的高斯分布的同时和的值xoutdfi在每次采样处都波动。
在这里
其中
当zpeaki=0时(即当不选择峰值项xindfpeakizpeakiwi,peaki时),p(zpeaki=0)=pdrop,并且上面提到的两个部分被表述如下:
该总体同样是n=(nxindf-1)个xindfjzjwi,j项(1≤j,j≠peaki,j≤nxindf-1),用varpopulation来表示其方差。该计算可以被视为从该总体采样均值m=n(1-pdrop)个项,并且如下所示在形成均值μ0dfi和方差-协方差σ0dfi的高斯分布的同时和的值xoutdfi在每次采样都波动。
在这里
其中
因此,在这两种情况下,当zpeaki=1和zpeaki=0这两种情况时xwdfi的一部分是高斯分布并且偏差项biasdfi是不同的。当进行简化x=xoutdfi时,xoutdfi的值的概率密度函数如下。
高斯混合分布处在图5的下部中所示出的状态中。
可以在峰值项的数目为2或更多的情况下执行相同的计算。图7的上部示出排除zj的xindfjwi,j项的值的状态,并且图7的下部示出在这种情况下xoutdfi的概率密度分布。
如上所述,在作为“类型1”和“类型2”的混合的“混合类型”中,用(2的(峰值项的数目)次方)个高斯混合分布来表示输出数据的概率密度分布。
这可按一般形式书写如下。在数据xoutdfi具有npeak(npeak<<nxindf)个峰值项xindfpeakiwi,peaki的情况下,存在2^npeak个分支条件conk(1≤k≤2^npeak),每个峰值项都对应于被退出(zpeaki=0)和不被退出(zpeaki=1)两种情况。
作为结果,根据下面的条件高斯混合分布用概率密度函数来定义数据x=xoutdfi。在此说明书中,xconk表示x的下标是conk。
在具有多层结构的神经网络中,需要针对与输出数据传播通过的每个后续层中的单独条件相对应的每个函数来独立地处理数据x。除此之外,在每个集成层fc中,这些条件分支进一步增加需要被单独计算的函数的数目。然而,在一个神经网络中退出层d的数目是3,或者在大多数情况下更少,以使得在本发明的实施例中提出的技术可以实现实际计算过程。
<激活层a中的计算>。
在激活层a中,计算由输入数据xina通过激活函数f而产生的输出数据xouta。详细地,激活层a中的过程包括根据以下表达式的计算。
输入数据是遵循多变量分布的随机变量。在被供应给激活层a的情况下,其被输出为因非线性激活函数f而失真的多变量分布。当给定的复函数失真时通常难以计算结果得到什么种类的函数。然而,如果服从于输入的函数是已知函数(诸如高斯分布或δ函数),则可以通过近似到某一程度来从数学上确定该函数。在本发明的实施例中,为了这样做,采用多个“条件”概率密度函数pdf(xconk|conk)的混合的上面提到的表示,其中对于用高斯分布或δ函数表述的每个函数,计算方法是已知的。这实现激活函数f中的变形计算。
因此,在激活层a中,如下所示利用每个条件概率密度函数通过激活函数f足以计算变换的f(pdf(xconk|conk))。
如果在集成层df后面的层不具有激活层a并且仅包括简单的线性变换层,则可以通过将混合分布近似成一个分布高达二阶矩(secondmoment)来执行后续层中的过程。在高斯混合中的一些高斯函数也重叠(例如各个分布是类似的)的情况下,可以采用诸如组合成一个高斯函数的加速技术。
详细地,假定多变量高斯混合分布被表述如下。
关于第k1个高斯函数gauss(xconk1|conk1)和第k2个高斯函数gauss(xconk2|conk2),在它们的均值和方差就值而言接近的情况下,例如如下面所示的合并成一个高斯函数gauss(xconk_1_2|conk_1_2)可以降低混合分布的数目并且减轻计算过程。在此说明书中,xconk1表示x的下标是conk1,xconk2表示x的下标是conk2,并且xconk_1_2表示x的下标是conk_1_2。
例如,可以通过计算过程来合并两个高斯函数。当用μk1和σk1分别表示在合并之前高斯函数gauss(xconk1|conk1)的均值和偏差并且用μk2和σk2分别表示在合并之前高斯函数gauss(xconk2|conk2)的均值和偏差时,则可以如下计算合并之后的高斯函数gauss(xconk_1_2|conk_1_2)的均值μk_1_2和偏差σk_1_2。
在任意情况下,最终从神经网络的输出层输出的数据的混合多变量分布被近似成高达二阶矩的一个分布函数,并且其方差被计算为最终估计输出结果的置信区间。
<信息估计装置10中的处理流程>。
下面参考图8a至8c来描述信息估计装置10中的过程。基本处理流程如下。估计的置信区间计算单元20接收输入数据,并且执行神经网络的每个层中的计算。在被供应有数据的层是具有退出的fc层(集成层df)的情况下,该数据分析单元30分析输入数据可以被分类成哪种类型。然后执行与数据分析单元30所确定的类型相对应的计算过程,以获得表示置信区间连同估计结果的方差,其中数据被视为条件多变量分布。
图8a是示出本发明的实施例中的信息估计装置中的过程的一个示例的流程图。
将去到神经网络的输入数据供应给信息估计装置10中的估计的置信区间计算单元20(步骤s11)。该估计的置信区间计算单元20被配置成按照构成神经网络的多个层的顺序来执行该过程。因此将输入数据供应给作为第一层的输入层来开始神经网络中的过程(步骤s12)。
在供应有输入数据的层是具有退出的fc层(集成层df)的情况下,该估计的置信区间计算单元20与数据分析单元30合作地执行数据分析和计算过程(步骤s14)。稍后将参考图8b和8c来描述步骤s14中的过程。另一方面,在供应有数据的层不是具有退出的fc层的情况下,估计的置信区间计算单元20执行在层中设置的计算过程(步骤s15)。
在步骤s14或s15中的计算过程已完成之后,将从该计算过程结果产生的输出数据作为去到下一层的输入数据供应给下一层(步骤s16)。在下一层是最终输出层的情况下(步骤s17:“是”),有条件地分离的多变量分布的方差被计算为一个组合方差,并且从输出层输出(步骤s18)。在下一层不是最终输出层的情况下(步骤s17:“否”),该过程返回到步骤s13以执行下一层中的计算过程。
下面参考图8b描述图8a中的步骤s14中的数据分析和计算过程。图8b是示出图8a中的步骤s14中的数据分析和计算过程的一个示例的流程图。
在输入数据被供应给具有退出的fc层的情况下执行图8b中的数据分析和计算过程。首先,该估计的置信区间计算单元20获取去到集成层df的输入数据xindf(步骤s141)。在这里假设在该集成层df中设置权重wdf和偏差bdf。
然后该估计的置信区间计算单元20和数据分析单元30针对如上文所述使用输入数据xindf、权重wdf和偏差bdf计算的输出数据的向量xoutdf的第i个元素xoutdfi、针对从i=1到i=nxoutdf的每个元素(即从第一行到第nxoutdf行的所有行)执行类型确定和计算过程。详细地,该估计的置信区间计算单元20和数据分析单元30首先设置i=1(步骤s142),并且针对来自nxoutdf个元素中的第i个输出数据xoutdfi执行类型确定和计算过程(步骤s143)。稍后将参考图8c来描述步骤s143中的类型确定和计算过程。
在步骤s143中的类型确定和计算过程已完成之后,在处理目标xoutdfi是最后一行(即i=nxoutdf)的情况下(步骤s144:“是”),该数据分析和计算过程结束。在处理目标xoutdfi不是最后一行(即i=nxoutdf)的情况下(步骤s144:“否”),使i递增(即i=i+1)(步骤s145),并且该过程返回到步骤s143以执行针对下一行的xoutdfi的类型确定和计算过程。
下面参考图8c描述图8b中的步骤s143中的类型确定和计算过程。图8c是示出图8b中的步骤s143中的类型确定和计算过程的一个示例的流程图。图8c示出针对具体第i个元素xoutdfi的计算过程。
在图8c中,该数据分析单元30首先计算来自nxoutdf个元素中的第i个输出数据xoutdfi(步骤s1431)。对于nxindf个xindfjwi,j项,例如在假设随机变量xindfj是它们的均值μxindfj的情况下计算μxindfjwi,j(步骤s1432)。此外,计算nxindf个xindfjwi,j项的标准偏差σμw(步骤s1433)。从nxindf个μxindfjwi,j项之中,提取满足“绝对值|μxindfjwi,j|≥σμwdratio”的所有项,并且按绝对值|μxindfjwi,j|的降序来布置它们(步骤s1434)。
在没有项满足|μxindfjwi,j|≥σμwdratio的情况下(步骤s1435:“否”),该数据分析单元30将第i个元素xoutdfi确定为“类型2”,并且该估计的置信区间计算单元20使用“类型2”中的分布计算方法来执行计算过程(步骤s1436)。步骤s1436中的“类型2”中的计算过程如上所述的那样,并且对所有nxindf个xindfjwi,j项计算多变量采样误差和。
在任何项都满足|μxindfjwi,j|≥σμwdratio的情况下(步骤s1435:“是”),按|μxindfjwi,j|的降序来提取预定数目(npeak)个项并将其存储为峰值列表(步骤s1437)。该数据分析单元30然后确定不同于被存储为峰值列表的峰值项的剩余项是否小到足以被视为零(步骤s1438)。
在剩余项小到足以被视为零的情况下(步骤s1438:“是”),该数据分析单元30将第i个元素xoutdfi确定为“类型1”,并且该估计的置信区间计算单元20使用“类型1”中的分布计算方法来执行计算过程(步骤s1439)。步骤s1439中的“类型1”中的计算过程如上所述的那样。例如,对于被存储为峰值列表的最大数目npeak个μxindfjwi,j项中的每一个,关于在最大程度上包括该项被选择为退出的情况和该项没有被选择为退出的情况的所有2^npeak个情况来执行计算。
在剩余项没有小到足以被视为零的情况下(步骤s1438:“否”),该数据分析单元30将第i个元素xoutdfi确定为“混合类型”,并且该估计的置信区间计算单元20使用“混合类型”中的分布计算方法来执行计算过程(步骤s1440)。步骤s1440中的“混合类型”中的计算过程如上所述的那样。例如,对于被存储为峰值列表的最大npeak个μxindfjwi,j项中的每一个,关于在最大程度上包括该项被选择为退出的情况和该项没有被选择为退出的情况的所有2^npeak个情况来执行计算。进一步地,计算对于所有剩余xindfjwi,j项的多变量采样误差和。
<实验结果>。
下面描述使用在上述本发明的实施例中提出的技术进行的实验。图9示出实验中使用的神经网络的结构。意图将该神经网络用于学习某一简单函数y=g(x)的回归问题,该简单函数y=g(x)接收作为输入的标量值x并且从其输出层输出标量值y。该神经网络由多个fc层f(包括通过relu函数的计算过程)、退出层d(设置成pdrop=0.4)、以及fc层f构成,在这里fc层的神经元的数目是2^10=1024。
图10示出使用在本发明的实施例中提出的技术进行的实验的结果。图10a示出该实验结果和通过常规技术获得的结果,并且是示出通过神经网络的函数的一个示例的图表。在图10a中,对于给定范围中的x,示出其函数g(x)的输出值y的估计结果,并且还示出犹如带的通过非专利文献1中公开的常规技术计算的估计的方差的平方根(标准偏差σ)(试验的数目mc=40)。图10b示出该实验结果和通过常规技术获得的结果,并且是示出在尝试集成层的输出值xoutdfi多次的情况下该值的一个示例的图表。在图10b中,对于同一范围中的x,示出图10a中的方差的平方根和通过在本发明的实施例中提出的技术计算的方差的平方根。
利用常规技术,通过对每个输入x执行估计计算mc次而获得的y的值的波动被产生为方差。这样的方差是不稳定的。另一方面,利用在本发明的实施例中提出的技术,该方差被解析计算,以使得可以产生稳定且平滑的方差。
<补充说明1:在总体是随机变量的情况下样本均值误差的方差的计算>。
假定如下面所示总体yi(1≤i≤n)是遵循n维多变量高斯分布的随机变量。在此处,μy是指示均值的n维向量,并且σy是n×n方差-协方差矩阵。
在从这里采样n个样本的情况下计算样本均值误差的方差,在这里:
ai和aj(i≠j)是相关的(在n大的情况下可能是独立的);
yi和yj(i≠j)是相关的;以及
ai和yj是独立的,
样本均值误差的方差被表述如下。
因为yi是随机变量,所以不能从方差var和协方差cov得出yi。假定ai和yi是独立的,下面的表达式成立。
因此,用预期值e来表述作为随机变量的yi。如在上面使用下面的表达式。
样本均值误差的方差的第一项的一部分被表述如下:
此外,下面的关系式成立。
通过使用该关系式,样本均值误差的方差的第二项的一部分被表述如下:
作为随机变量的yi的均值是e(yi)。这是与索引i有关的值。对于所有索引的均值(即均值的均值)如下。
将这两个部分组合以产生样本均值误差的以下方差。
用下面的表达式(公式)1使用yi的预期值e来定义样本总体的和的方差。
(表达式1)。
表达式1不存在问题。然而,表达式1使用总体数据yi(1≤i≤n)的预期值e,这是不方便的。期望使用作为随机变量的总体数据的每个个体值yi的方差var(yi)和协方差cov(yi,yj)来表示这一点。此外,尽管总体数据yi是随机变量,但是如果总体数据yi是固定值(采用均值e(yi))则期望还使用作为一个整体的方差varpopulation(y)(其被表述如下)。
在这里
鉴于这些要求,使用作为随机变量的总体数据的方差var(yi)和协方差cov(yi,yj)以及varpopulation(y)来表述样本总体的和的方差。这导致下面的表达式。下面给出该表达式等同于表达式1的证明。
提出的
首先,使用下面的表达式来修改该表达式。
提出的
然后使用下面的表达式来修改该表达式。
提出的
使用下面的表达式来进一步修改该表达式。
提出的
上面给出的表达式中的第一和第二项的系数如下。
使用上述内容,表达式被修改如下。
提出的
该表达式是上面计算的表达式1中的样本总体的和的方差,并且满足下面关系。
提出的
下面总结结论。假定存在n个有限数目的总体数据yi(1≤i≤n),并且这些数据yi不是固定值而是如下所示遵循n维多变量高斯分布的随机变量。在此处,μy是指示均值的n维向量,并且σy是n×n方差-协方差矩阵。
在从n个随机变量的总体采样n个随机变量的情况下,样本和误差的方差如下。
在此处,方差var(yi)和协方差cov(yi,yj)是从方差-协方差矩阵获得的随机变量的总体的方差-协方差。在每个总体都不是随机变量的情况下假设方差varpopulation(y)是样本和误差的方差(该值被假设成均值e(yi)),并且varpopulation(y)被表述如下。
在这里
<补充说明2:样本均值误差的协方差的计算>。
可以以与方差相同的方式来计算协方差。假定两个总体y1和y2是如下所示遵循n维多变量高斯分布的随机变量。在此处,μ1y和μ2y中的每一个都是指示均值的n维向量,并且σ1y和σ2y中的每一个都是n×n方差-协方差矩阵。
计算在以y1和y2关于索引i同步的状态采样n个样本的情况下(即当y1i被采样时,y2i也被采样)的样本均值误差的协方差cov(y1,y2)。
可以用使用下面的表达式(公式)的方差来表示协方差。
var(y1)和var(y2)是分别对于总体y1和y2的上面提到的样本均值误差的方差,并且所以是可计算的。
var(y1+y2)是根据由将总体y1和y2的相应项加在一起结果得到的被如下表示的新总体y1+y2的样本均值误差的方差。
可以通过上面提到的方法,通过将相应的项视为一个项y_1_2i(在这里y_1_2i=y1i+y2i)来计算来自该总体的均值误差方差。
本发明实现对表示对于使用神经网络的估计装置中的估计结果的置信区间的方差的稳定和快速计算,并且适用于所有与神经网络有关的技术。本发明还实现更宽范围的神经网络的应用,并且在要求快速且可靠处理的环境(例如对诸如汽车或步行者之类的移动对象的估计)中是卓有成效的。
- 还没有人留言评论。精彩留言会获得点赞!