一种基于两阶段学习的多模态时间序列建模方法与流程
本发明涉及计算机视觉、多模态时间序列建模技术领域,具体涉及一种基于两阶段学习的多模态时间序列建模方法。
背景技术:
多模态深度置信网络(MDBN)是一种生成模型,利用多模态受限玻尔兹曼机(MRBM)学习对应各个模态的深度置信网络(DBN)的联合特征分布。对于每一个模态,MDBN都建立了一个DBN来获取该模态的抽象特征分布,并且利用MRBM从这些不同模态的特征中学习到联合特征。
长短期记忆模型(LSTM)是一种循环神经网络,可以用于时间序列数据建模。LSTM单元通常以几个“门”机制来实现,可以控制输入和输出记忆单元的信息。
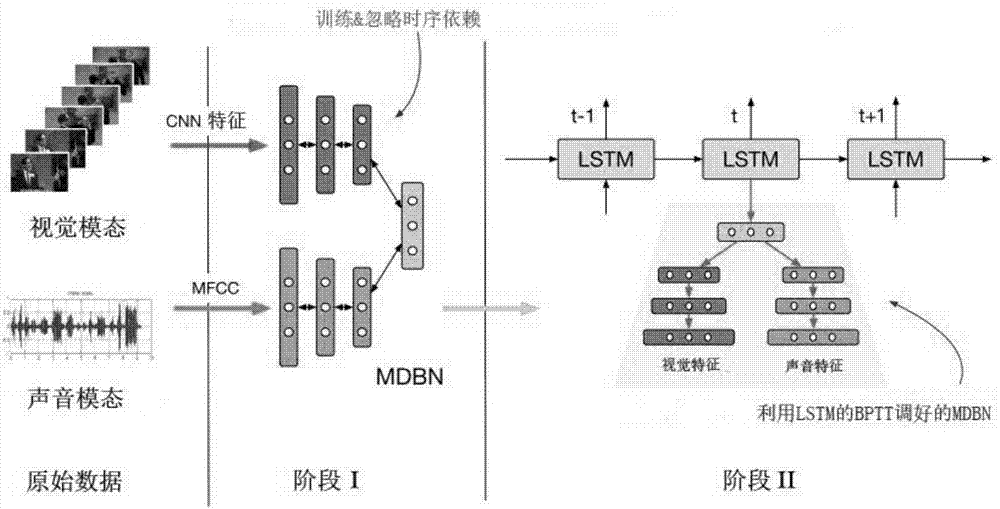
两阶段多模态学习模式不需要估计整个时序信息的分布而在第一阶段仅仅提取了不考虑时间依赖信息的静态特征分布,从而得到多模态的抽象特征分布,第二阶段中利用LSTM的时序建模能力将静态特征装换为相应的动态特征分布。两阶段多模态学习模式的结果显示更高层次的抽象特征比低层次的能更有效的学习到时序依赖信息。两阶段多模态学习模式的模型在Big Bang Theory数据集(说话人识别),AVLetters数据集(语音识别)上取得了当前最好的结果。
技术实现要素:
本发明的目的是为了解决现有技术中的上述缺陷,提供一种基于两阶段学习的多模态时间序列建模方法。
本发明的目的可以通过采取如下技术方案达到:
一种基于两阶段学习的多模态时间序列建模方法,所述的多模态时间序列建模方法包括下列步骤:
S1、在第一阶段,提取各时间步下每个模态的静态特征分布,先利用深度置信网络(DBN)学习每个模态的静态特征分布,再通过多模态深度置信网络(MDBN)将各个模态的静态特征融合到顶端的联合隐层状态J上,Njoint是联合隐层状态的特征维度;
S2、通过多模态学习技术获得各个时刻下的联合特征分布,多模态深度置信网络(MDBN)通过多模态学习技术获得联合特征分布,将多模态深度置信网络(MDBN)每两个邻接的层作为一个受限玻尔兹曼机(RBM),两个模态隐层的联合分布与联合隐层状态J的联合分布如下:
其中代表模态1的第二个隐层的状态,代表模态2的第二层隐层的状态,J代表两个第二层隐层顶端的联合隐层状态,γ,σ是第二个隐层和联合隐层单元输入的偏置项,W1和W2是两个模态第二个隐层和联合隐层之间的权重矩阵,Z(Θ)是划分函数,获得联合分布的方程后,用对比k散度算法(CD-k)逐层的训练深度置信网络(DBN);
S3、在第二阶段,通过递归神经网络对获得的高层次联合特征分布进行时间序列依赖建模,通过梯度反传将独立的静态特征分布转化为相应的动态特征分布。
进一步地,所述的步骤S3过程如下:
在第一阶段的多模态深度置信网络(MDBN)被预训练后,将联合隐层状态J在每个时间步输入到顶端的LSTM,利用LSTM时序建模能力来学习联合隐层状态J,在每个时间步,输出当前帧的预测标签作为当前说话人的标签,整个序列分类的表现将会在所有的时间步上进行平均运算,训练误差如下:
式中n表示第n个帧,n=1,2,...,N,y∈Rk是one-hot向量代表真实标签,ynk是时间n的one-hot向量第k项,Onk是时间n第k个单元的输出,根据这个平均类别损失,采用基于时间的反向传播算法(BPTT)来训练第一阶段的多模态深度置信网络(MDBN)和顶端的LSTM网络。
进一步地,所述的多模态深度置信网络(MDBN)将每两个邻接的层都作为一个受限玻尔兹曼机(RBM),定义相邻层的联合分布,为一个模态的输入,vi为第i个模态的输入,为第一个隐藏层的状态,为第二个隐藏层的状态,代表模态1的第二个隐层的状态,代表模态2的第二层隐层的状态,α,β,γ是输入的偏置项,αi为第i个输入的偏置项,βj是第j个输入的偏置项,ωij为第i个模态输入与第j个模态第一个隐层的权重,Z(Θ)是划分函数,受限玻尔兹曼机(RBM)的联合分布写成公式为:
进一步地,所述的步骤S2中用对比k散度算法(CD-k)逐层的训练深度置信网络(DBN)的过程如下:
S201、给出视觉层的输入则可以从条件分布中采样隐层的值
S202、用采样后的隐层状态h重构视觉层的值v′:
S203、重复步骤S201和步骤S202K次,获得最后一层视觉层的值vk,然后用数据分布和模型分布去计算参数的梯度。
进一步地,用数据分布和模型分布去计算权重的梯度如下:
进一步地,所述的步骤S3的训练系统的学习过程中采用两阶段多模态学习算法,具体如下:
S301、遍历每个模态m下,其中m=1,2,...,M,M为模态数量,深度置信网络(DBN)的每一层i,其中i=1,2,…,L,L为深度置信网络(DBN)的深度,将hi和hi+1之前的权重作为受限玻尔兹曼机(RBM)用对比k散度算法(CD-k)来进行训练;
S302、修正每个模态所有预训练的权重;
S303、得到每个模态第L个隐层状态并且作为多模态深度置信网络(MDBN)的顶端在一个多模态受限玻尔兹曼机(MRBM)学习联合层,和受限玻尔兹曼机(RBM)有相同的训练过程;
S304、得到多模态序列的N-长度的静态联合特征分布;
S305、输入联合特征序列并且训练LSTM,包括了每个时间步调好的多模态深度置信网络(MDBN)。
本发明相对于现有技术具有如下的优点及效果:
根据本发明的方法,由于在第一阶段不需要对整个时序序列进行分布估计,从而显著的减少了第一阶段的训练成本。此外,在更高抽象层次学习到的时序信息比起低层次的信息更加有效。
附图说明
图1是多模态深度置信网络(MDBN)模型的结构示意图;
图2是两阶段时序多模态学习模型的结构示意图;
图3是说话人识别在Big Bang Theory数据集上的效果可视化图。
具体实施方式
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
实施例
本实施例公开一种针对多模态时间序列数据的两阶段学习建模方法用于说话人识别和语音识别。所谓模态,即人的“感官”。现实中的数据均是人们的感官感受到对现实世界的描述,主要包视频模态、文本模态、语音模态等。多模态时间序列数据即由以上两种及以上模态按照时间发生先后顺序组成的时序数据。例如,由按时间采集的图像信息组成的视频数据和按时间采集的音频信息组成的语音数据,共同组成了音视频两种模态的多模态时序数据。
本实施例以生活大爆炸(BBT)数据集和AVLetters数据集作为实验数据。讲话人识别任务目标是在一个连续对话的语境中根据面部特征和声音特征确定说话人。首先使用人脸检测算法确定每个录像帧中的人脸,然后这些帧被人工标记为5类,分别是Shelton,Lenord,Howard,Raj和Penny。由此得到310,000帧人工标记的5个任务的数据。对于语音数据,提取每个人在录像中说话的一段,将它们合并为一个语音数据,并且对应于图像序列中的人物进行标记。
用第二季的前6个片段进行训练,第一季的前6个片段进行测试。用Caffenet对BBT数据集抓取图像特征,用20-ms-滑动窗口-10-ms-步长MFCCs预处理语音数据,每个序列长度为49。分别设置了0.5s,1.0s,1.5s,2.0s,2.5s,3.0s的滑动窗口。
语音识别中给出一段录像剪辑片段中的嘴型和配音,任务是识别出说话的人物身份。本实施例选取了AVLetters数据集的780个短录像剪辑。在每个录像中都有一个人从A念到Z。一共有10个人,每个人读3次26个英文字母。所有帧的剪辑图像大小都为60*80.数据集同时提供了声音数据的MFCC特征。将训练集的前两个当做训练集,后一个当做测试集。我们的实验中说话人之间是独立的。为了匹配图像和声音帧的长度,将一个图像帧和4个声音帧连续的输入到模型中。
步骤S1、在第一阶段,提取各时间步下每个模态的静态特征分布。具体地,先利用深度置信网络(DBN)学习每个模态的静态特征分布,再通过多模态深度置信网络(MDBN)将各个模态的静态特征融合到顶端的联合隐层状态J上,如图2所示,Njoint是公共特征层的维度。
步骤S2、通过多模态学习技术获得各个时刻下的联合特征分布。具体地,多模态深度置信网络(MDBN)通过多模态学习技术可以获得联合特征分布。多模态深度置信网络(MDBN)每两个邻接的层都可以看成是一个受限玻尔兹曼机(RBM)。两个模态隐层的联合分布和联合隐层状态J的联合分布可以写为:
其中代表模态1的第二个隐层的状态,代表模态2的第二层隐层的状态。J代表两个第二层隐层顶端的联合隐层状态,γ,σ是第二个隐层和联合隐层单元输入的偏置项。W1和W2是两个模态第二个隐层和联合隐层之间的权重矩阵。Z(Θ)是划分函数。获得了联合分布的方程后,可以用对比k散度算法(CD-k)逐层的训练深度置信网络(DBN)。
步骤S3、在第二阶段,通过递归神经网络对获得的高层次联合特征分布进行时间序列依赖建模,通过梯度反传将独立的静态特征分布转化为相应的动态特征分布。具体地,在第一阶段的多模态深度置信网络(MDBN)被预训练后,将联合隐层状态J在每个时间步输入到顶端的LSTM。在这个阶段,利用LSTM时序建模能力来学习联合特征J,在每个时间步,输出当前帧的预测标签(当前说话人的标签)。整个序列分类的表现将会在所有的时间步上进行平均运算。训练误差可以写成:
这里n表示第n个帧,n=1,2,...,N,y∈Rk是one-hot向量代表真实标签。ynk是时间n的one-hot向量第k项,Onk是时间n第k个单元的输出。根据这个平均类别损失,采用基于时间的反向传播算法(BPTT)来训练第一阶段的MDBN和顶端的LSTM网络。
其中,根据步骤S2所述的多模态深度置信网络(MDBN)每两个邻接的层都可以看成是一个受限玻尔兹曼机(RBM),定义相邻层的联合分布,为一个模态的输入,vi为第i个模态的输入,为第一个隐藏层的状态,为第二个隐藏层的状态,代表模态1的第二个隐层的状态,代表模态2的第二层隐层的状态。α,β,γ是输入的偏置项。αi为第i个输入的偏置项,βj是第j个输入的偏置项,ωij为第i个模态输入与第j个模态第一个隐层的权重,Z(Θ)是划分函数。RBM的联合分布写成公式为:
其中,步骤S2所述的用k对比分散算法(CD-k)一层一层的训练DBN按照以下步骤实施:
1)给出视觉层的输入则可以从条件分布中采样隐层的值
2)用采样后的隐层状态h重构视觉层的值v′:
3)重复1)和2)K次,将会获得最后一层视觉层的值vk。然后用数据分布和模型分布去计算参数的梯度,比如计算权重的梯度梯度:
其中,步骤S3所述的训练系统的学习过程中,两阶段多模态学习算法具体如下:
1)遍历每个模态m下,其中m=1,2,...,M,M为模态数量,深度置信网络(DBN)的每一层i,其中i=1,2,…,L,L为深度置信网络(DBN)的深度,将hi和hi+1之前的权重作为RBM用CD-k来进行训练。
2)修正每个模态所有预训练的权重。
3)得到每个模态第L个隐层状态并且作为多模态深度置信网络(MDBN)的顶端在一个多模态受限玻尔兹曼机(MRBM)学习联合层,和受限玻尔兹曼机(RBM)有相同的训练过程。
4)得到多模态序列的N-长度的静态联合特征分布。
5)输入联合特征序列并且训练LSTM,包括了每个时间步调好的多模态深度置信网络(MDBN)。
说话人识别中,本实施例中模型相比于其它模型有更好的表现结果,不同的滑动窗口结果提升7.74%-11.42%的准确率。语音识别中平均准确率可以达到66.51%。和baseline模型以及只采用图像或者声音信息的LSTM模型进行的对比,本实施例中多模态方法比单一模态的方法表现更好,可以达到98.01%的准确率。
如图3所示,为了在视觉上展示上述实施例的结果,选取了几个由本实施例中公开方法处理的帧的效果,该方法可以利用视觉声音特征识别Big Bang Theory(BBT)中的两个人物角色。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!