一种基于LSTM网络的步态识别系统及方法与流程
本发明属于计算机视觉和深度学习技术领域,尤其涉及一种基于lstm网络的步态识别系统及方法。
背景技术:
目前,现有的步态识别技术大多基于对人体运动视频进行分割,然后从视频序列中提取步态特征,再对参考集和待识别样本之间的步态特征进行匹配完成身份识别。其本质是基于图片到图片的匹配问题,该类方法没有考虑视频中相邻帧之间的时序信息,忽略了相邻帧之间的相关性。基于实际应用场景中可用的往往是人体运动的视频序列。
综上所述,现有技术存在的问题是:现有的步态识别算法将其简单定义为图片之间的步态特征的匹配问题,即将视频分割成帧,再进行目标图片与视频帧之间的匹配完成步态识别。忽略了原始视频中相邻帧之间的相关性,将视频分割成帧也破坏了视频的完整度使其丢失时序信息。
技术实现要素:
针对现有技术存在的问题,本发明提供了一种基于lstm网络的步态识别系统。
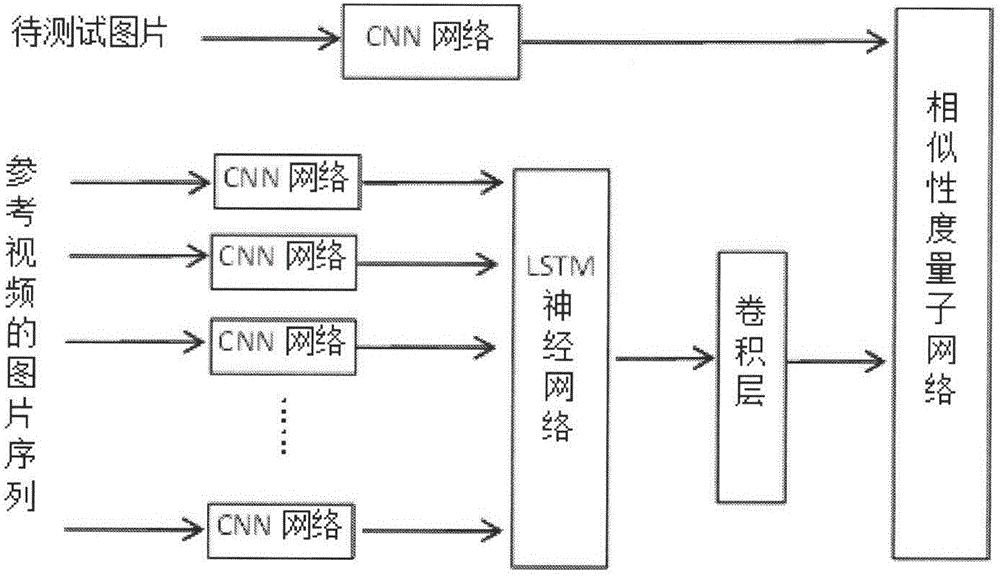
本发明是这样实现的,一种基于lstm网络的步态识别系统,设置有用于参考视频的图片序列进行特征提取的cnn+lstm网络单元;
与cnn网络单元相连接,用于局部感知的卷积层单元,该部分主要用于对视频进行步态特征的提取;
与lstm神经网络单元相连接,用于模拟时序信息的lstm神经网络单元,该部分对cnn提取的特征进一步进行时序相关性处理,分析视频中相邻帧之间的信息;
与相似性度量子网络相连接,用于进行相似性匹配的相似性度量子网络单元,主要完成对参考视频的步态特征与待识别样本的步态特征之间的匹配及误差计算。
本发明的另一目的在于提供一种所述基于lstm网络的步态识别方法,所述基于lstm网络的步态识别方法包括:人体运动图片的密集特征提取,对于视频序列从每个视频帧中提取步态特征,对视频中的时间和空间信息进行编码,之后将图片和视频的步态特征送入相似性度量网络进行步态特征匹配;在每个时间步的输出连接在一起作为视频的特征;将图像和视频的特征推送到相似性度量子网络,学习视频与图像之间步态特征的距离来度量图像与视频的相似程度。
本发明的优点及积极效果为:该基于lstm网络的步态识别系统提出的从图像到视频的步态识别思路,考虑了视频内的时序信息,使用lstm模拟视频中相邻帧之间的相关性,从而将视频作为一个整体分析其步态特征。该模型直接以端到端的方式学习视频序列的空间特征和时间特征并同时学习和优化特征表示和相似性度量。该系统更加接近于实际用用场景,并且考虑了时序信息使得匹配的准确度更高,具有更深远的研究价值。本发明提出基于cnn+lstm的步态识别算法,其特点是使用lstm对视频中相邻帧的相关性进行分析,在提取视频特征的同时保持了视频完整性。
附图说明
图1是本发明实施例提供的基于lstm网络的步态识别系统的结构示意图;
图2是本发明实施例提供的步态高斯图的提取过程流程图;
图中:1、cnn网络单元;2、lstm神经网络单元;3、卷积层单元;4、相似性度量子网络单元。
具体实施方式
为能进一步了解本发明的发明内容、特点及功效,兹例举以下实施例,并配合附图详细说明如下。
下面结合附图对本发明的结构作详细地描述。
如图1所示,本发明实施例提供的基于lstm网络的步态识别系统设置有:
用于参考视频的图片序列进行特征提取的cnn网络单元1;
与cnn网络单元1相连接,用于模拟时序信息的lstm神经网络单元2;
与lstm神经网络单元2相连接,用于局部感知的卷积层单元3;
与卷积层单元3相连接,用于进行相似性匹配的相似性度量子网络单元4。
从图片到视频的步态识别,以端到端的方式制定了包含特征提取、视频时空信息编码和相似性度量的识别框架,其算法框架如图1所示。使用cnn网络单元1进行特征提取,lstm神经网络单元2模拟时序信息,相似性度量子网络单元4进行相似性匹配。
具体的实施过程:在训练过程中,采用cnn网络单元1进行人体运动图片的密集特征提取,对于视频序列,使用cnn网络单元1从每个视频帧中提取步态特征,将视频中各帧的步态特征并入到lstm神经网络单元2进一步对视频中的时间和空间信息进行编码,之后将图片和视频的步态特征送入相似性度量网络进行步态特征匹配。作为一种循环神经网络,lstm神经网络单元2允许信息在视频序列的时间间隔之间流动,将lstm神经网络单元2在每个时间步的输出连接在一起作为视频的特征,有效地模拟了相邻帧之间的相关性。最后将图像和视频的特征推送到相似性度量子网络,学习视频与图像之间步态特征的距离度量来度量图像与视频的相似程度。
本识别系统分为两大部分,第一部分用于图像和视频特征提取,第二部分用于相似性学习。在第一部分,使用cnn网络单元1来提取输入图像的特征,用cnn网络单元1和lstm神经网络单元2的组合来提取视频的特征。每帧视频首先由cnn网络单元1处理,产生人体运动的特征向量,将各帧特征输送入lstm神经网络单元2进一步分析各帧之间相关性,lstm神经网络单元2将各帧输出连接在一起作为视频序列的特征向量。最后,输入图像和视频的特征向前传递到相似子网络进行距离度量学习。具体的实施过程如下:
数据准备
选取中科院的数据库作为实验数据库,根据图2过程提取步态高斯图,主要过程为从视频序列中减除运动背景得到人体运动轮廓图,对轮廓图进行形态学处理使其噪声减小并连续并提取步态周期,进一步对轮廓图进行归一化使其大小相等,在一个步态周期内计算步态高斯图。为了增加训练序列的多样性,应用包括裁剪和镜像的数据增强方法对数据进行扩充,从而提升算法的鲁棒性。
模型的建立
建立图1所示的深度网络模型并建立该模型相关的配置文件,主要有deploy.prototxt、solver.prototxt、train_valprototxt等文件,这些文件主要定义了训练数据、测试数据、模型的优化方法、迭代次数……等相关信息,有利于我们更好地得到一个基于lstm网络的步态识别模型。
3、实验:
根据发明内容的不同本实验进行了三组实验,分别为:
a:选取相同携带状态的训练样本和测试样本(均为nm或者bg或者cl),选取所有视角(0-180)下的步态序列作为训练集,任意角度的视频序列作为测试集。
b:选取nm状态下的所有视角(0-180)作为训练样本集同视角下的bg和cl状态的视频作为测试序列。
c:选取nm、bg、cl状态下所有视角(0-180)下的序列作为训练样本集,任意角度与状态下的序列作为测试集。
以上所述仅是对本发明的较佳实施例而已,并非对本发明作任何形式上的限制,凡是依据本发明的技术实质对以上实施例所做的任何简单修改,等同变化与修饰,均属于本发明技术方案的范围内。
技术特征:
技术总结
本发明属于计算机视觉和深度学习技术领域,公开了一种基于LSTM网络的步态识别系统及方法,设置有用于参考视频进行特征提取的CNN+LSTM网络单元,即使用CNN网络单元对参考视频进行特征提取,进一步用LSTM神经网络单元模拟视频的时序信息;设置有用于待识别者步态图片序列进行特征提取的CNN单元,即使用CNN直接对待识别者的图片进行特征提取。本发明从图像到视频的步态识别思路,考虑了视频内的时序信息,使用LSTM模拟视频中相邻帧之间的相关性,从而将视频作为一个整体分析其步态特征。该模型直接以端到端的方式学习视频序列的空间特征和时间特征并同时学习和优化特征表示和相似性度量。
技术研发人员:李洪安
受保护的技术使用者:西安科技大学
技术研发日:2018.01.29
技术公布日:2019.08.06
- 还没有人留言评论。精彩留言会获得点赞!