一种深度学习框架的调度方法及系统与流程
本发明涉及人工智能深度学习技术领域,尤其涉及一种深度学习框架的调度方法及系统。
背景技术:
近年来,深度学习已经广泛地应用于语音识别,机器翻译,计算机视觉等领域,都取得了很好的效果。随着深度学习理论的兴起,多种深度学习的编程框架不断涌现。tensorflow、caffe、pytorch等深度学习框架在架构、性能、模型构建等许多方面都差异甚大。每种框架都有其特别适用的领域,而统一管理调度这些框架的平台却非常缺乏,极少数支持的平台,例如腾讯的di-平台,非开源,对自身的业务支持性很好,但是可扩展性不足。
另一方面,深度学习理论的发展离不开gpu硬件的进步。gpu(graphicsprocessingunit,图形处理器)是一种专门的图像运算处理器,主要工作于个人计算机、高性能服务器或移动设备之上,为它们加速各种3d图像和特效的处理。对于很多科学计算而言,性能主要取决于gpu的浮点计算能力,特别是对深度学习任务来说。但是,由于涉及gpu的计算很多本身就需要巨大的计算量,单机通常无法在短时间内完成,因此gpu的集群化管理和使用成为一种必然的趋势。
深度学习的模型训练需要海量数据,海量数据的预处理需要用大数据技术进行处理。大数据处理框架中最为流行的当属hadoop和spark。hadoop和spark均支持hadoopyarn(yetanotherresourcenegotiator)作为资源管理器。hadoopyarn的出现使得资源的管理和调度更加简单,大大简化了集群结构,并且使其具备了多种任务类型的可扩展性。
综上所述,结合传统的大数据集群框架hadoopyarn,对在hadoop平台上实现gpu资源的管理与调度并使其具备执行深度学习框架是我们要解决的首要问题。
技术实现要素:
为解决上述问题,第一方面,本发明提供一种深度学习框架的调度系统,包括全局资源管理器resourcemanager、多个节点管理器nodemanager、应用程序管理器applicationmaster和资源容器container;在yarn调度系统的配置选项中增加图像处理器gpu选项以及是否使用图像处理器gpu,并在所述全局资源管理器resourcemanager中增加图像处理器gpu的资源类型、添加图像处理器gpu的权重设置、增加可深度优先搜索gpu通用接口;
对每种应用设计单独的客户端并修改部分应用程序管理器,使更改配置后的yarn调度系统与其他系统软件相结合。
优选地,yarn调度系统具体通过以下步骤进行配置:
在resourcemanager中的resourcetype.java文件里增加gpu的资源类型,使gpu成为调度器的一种资源类型;
在resourcemanager中的resourceweight.java文件里增加gpu的权重设置;
在hadoop-yarn-common里的gpuresourcecalculator.java中增加可深度优先搜索gpu的通用接口;
扩展drf算法,使yarn调度器可以支持gpu的调度;
在nodemanager里的nodestatusupdateimpl.java文件里增加当前各个节点gpu总数及可用gpu的状态检测;
在nodemanager里的nodemanager.java文件里增加对当前各个节点正在使用的gpu状态检测;
在yarn-site.xml里增加每个槽的gpu数量,gpu过载数量,单个任务每个节点最大、最小可分配gpu数量,以及是否使用gpu资源。
优选地,对每种应用设计单独的客户端并修改部分applicationmaster,使更改配置后的yarn调度系统与其他系统软件相结合步骤,包括:
在客户端,对用户提交应用程序脚本的信息进行识别,并进行相应的初始化;监控应用程序,client获取唯一的applicationid,向数据结构applicationsubmissioncontext中放入启动applicationmaster所需的所有信息;将applicationmaster中从yarn调度系统中获取的节点资源转换为相应json格式。
第二方面,本发明提供一种深度学习框架的调度方法,应用于由全局资源管理器resourcemanager、多个节点管理器nodemanager、应用程序管理器applicationmaster和资源容器container构成的调度系统中;包括以下步骤:
在yarn调度系统的配置选项中增加图像处理器gpu选项以及是否使用图像处理器gpu,并在所述全局资源管理器resourcemanager中增加图像处理器gpu的资源类型、添加图像处理器gpu的权重设置、增加可深度优先搜索gpu通用接口;对每种应用设计单独的客户端并修改部分应用程序管理器,使更改配置后的yarn调度系统与其他系统软件相结合。
优选地,通过以下步骤对yarn调度系统进行配置:
在resourcemanager中的resourcetype.java文件里增加gpu的资源类型,使gpu成为调度器的一种资源类型;在resourcemanager中的resourceweight.java文件里增加gpu的权重设置;在hadoop-yarn-common里的gpuresourcecalculator.java中增加可深度优先搜索gpu的通用接口;扩展drf算法,使yarn调度器可以支持gpu的调度;在nodemanager里的nodestatusupdateimpl.java文件里增加当前各个节点gpu总数及可用gpu的状态检测;在nodemanager里的nodemanager.java文件里增加对当前各个节点正在使用的gpu状态检测;在yarn-site.xml里增加每个槽的gpu数量,gpu过载数量,单个任务每个节点最大、最小可分配gpu数量,以及是否使用gpu资源。
优选地,对每种应用设计单独的客户端并修改部分applicationmaster,使更改配置后的yarn调度系统与其他系统软件相结合步骤,包括:
在客户端,对用户提交应用程序脚本的信息进行识别,并进行相应的初始化;监控应用程序,client获取唯一的applicationid,向数据结构applicationsubmissioncontext中放入启动applicationmaster所需的所有信息;将applicationmaster中从yarn调度系统中获取的节点资源转换为相应json格式。
采用本发明的系统和方法,结合传统的大数据集群框架hadoopyarn,能够在hadoop平台上实现gpu资源的管理与调度,在本发明的系统中深度学习框架作为一个普通程序被使用的调度,极大提高gpu的被使用能力。
附图说明
图1为现有yarn调度系统的结构示意图;
图2为本发明实施例提供的一种深度学习框架的调度方法流程示意图;
图3为图2所示调度方法中yarn调度系统的配置方法的示意图;
图4为图2所示调度方法中客户端的设计和应用程序管理器修改的流程图;
图5为本发明实施例二提供的tensorflowonyarn的架构图;
图6为本发明实施例三1ps多worker下不同框架平均每个epoch运行时间柱状对比图;
图7为本发明实施例三1ps多worker下不同框架加速比示意图;
图8为本发明实施例三2ps多worker下不同框架平均每个epoch运行时间示意图;
图9为本发明实施例三2ps多worker下不同框架加速比示意图。
具体实施方式
下面结合附图和实施例,对本发明的技术方案做进一步的详细描述。
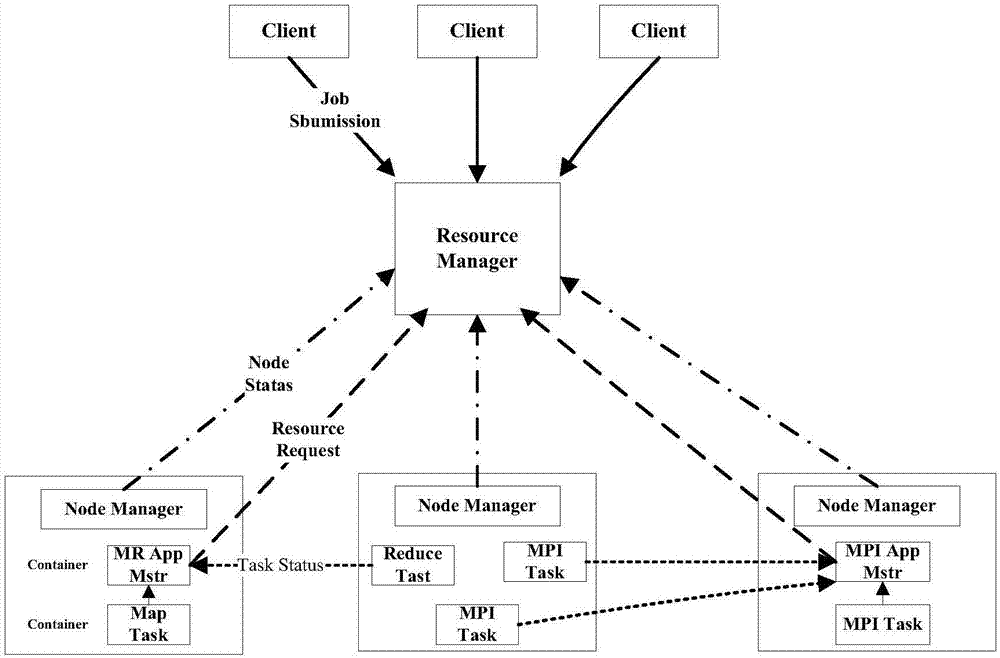
图1为现有yarn调度系统的结构示意图。如图1所示,resourcemanager是一个全局的资源管理器,client、nodemanager均与其进行交互,resourcemanager负责的是整个系统的资源管理和分配。用户通过client提交的每个应用程序,均包含一个applicationmaster。nodemanager可以看做是每个节点上的资源和任务管理器,负责各个节点的资源使用情况以及各个container的运行状态,并与resourcemanager进行交互。nodemanager同时处理applicationmaster上附加的各种实际请求,例如container的启动、停止等。container则可以看做是yarn在多维度资源的封装,container的具体封装是根据应用程序的需求动态生成的。
图2为本发明实施例提供的一种基于yarn调度系统的深度学习框架的调度方法流程示意图。如图2所示该方法包括步骤s100-s200:
s100,在yarn调度系统的配置选项中增加图像处理器gpu选项以及是否使用图像处理器gpu,并在所述全局资源管理器resourcemanager中增加图像处理器gpu的资源类型、添加图像处理器gpu的权重设置、增加可深度优先搜索gpu通用接口;
具体地,更改原有yarn调度系统配置的方法,如图3所示,包括以下步骤:
s101、在resourcemanager中的resourcetype.java文件里增加gpu的资源类型,使gpu成为调度器的一种资源类型,具体地,如下所示:
publicenumresourcetype{memory,cpu,gpu}
s102、在resourcemanager中的resourceweight.java文件里增加gpu的权重设置,具体地,如下所示:
publicresourceweights(floatmemoryweight,floatcpuweight,floatgpuweight){weights[resourcetype.memory.ordinal()]=memoryweight;
weights[resourcetype.cpu.ordinal()]=cpuweight;
weights[resourcetype.gpu.ordinal()]=gpuweight;}。
s103、在hadoop-yarn-common里的gpuresourcecalculator.java中增加可深度优先搜索gpu的通用接口,具体地,如下所示:
s104、扩展drf算法,使yarn调度器可以支持gpu的调度;drf算法,全称主资源公平调度(dominantresourcefairness)算法,是yarn
进行资源管理和调度的主要算法,可以支持多维资源调度。drf算法,在管理和调度cpu和内存两种资源的情况下,已经被实践证明非常适合应用于多为资源管理和调度的复杂环境中。因此为了使yarn调度器可以支持gpu的调度,调度器算法主要是在drf的基础上进行扩展。
drf算法中,主资源指的是各所需资源在相应总资源中所占比例最大的资源,drf算法的基本设计思想是将多维资源管理调度问题转化为单资源管理调度问题,将所有主资源中最小的主资源进行最大化。具体地,其算法伪代码如下所示:
r=<r1,…,rm>//m种资源对应的容量
c=<c1,…,cm>//已用掉的资源,初始值为0
si(i=1..n)//用户(或者框架)i的主资源所需份额,初始化为0
ui=<ui,1,…,ui,m>(i=1..n)//分配给用户i的资源,初始化为0
//挑选出主资源所需份额si最小的用户i
di<--{用户i的下一个任务需要的资源量}
ifc+di≤rthen
//将资源分配给用户i
c=c+di//更新c
ui=ui+di//更新u
else
return//资源全部用完
endif
s105、在nodemanager里的nodestatusupdateimpl.java文件里增加当前各个节点gpu总数及可用gpu的状态检测;
s106、在nodemanager里的nodemanager.java文件里增加对当前各个节点正在使用的gpu状态检测;
s107、在yarn-site.xml里增加每个槽的gpu数量,gpu过载数量,单个任务每个节点最大、最小可分配gpu数量,以及是否使用gpu资源。
s200,对每种应用设计单独的客户端并修改部分应用程序管理器,使更改配置后的yarn调度系统与其他系统软件相结合。为了使yarn可以支持多种深度学习框架以及容器,需要对每种应用设计单独的客户端并修改部分applicationmaster。多种深度学习框架主要指的是主流的深度学习,例如tensorflow、caffe、mxnet等,容器主要指的是singularity。如图4所示,包括以下步骤:
s201、在客户端,对用户提交应用程序脚本的信息进行识别,并进行相应的初始化;具体地,如下所示:
对用户提交应用程序脚本的信息进行识别,并进行相应的初始化,主要包括应用程序中,ps所需的个数和cpu核数,worker所需的个数,cpu核数和gpu个数。每个ps和worker的参数设置均一样,同时包括应用程序的名称,类型,输入,输出。以及启动应用程序的命令;
s202、监控应用程序,client获取唯一的applicationid,向数据结构applicationsubmissioncontext中放入启动applicationmaster所需的所有信息;具体地,client先要通过以下代码获取唯一的applicationid,
privateyarnclientapplicationnewapp;
privateapplicationidapplicationid;
getnewapplicationresponsenewappresponse=newapp.getnewapplicationresponse();
applicationid=newappresponse.getapplicationid();
然后往数据结构applicationsubmissioncontext中放入启动applicationmaster所需的所有信息。
s203、将applicationmaster中从yarn调度系统中获取的节点资源转换为相应json格式。具体地,如下所示:applicationmaster可以看做是相对独立的第三方,与resourcemanager和nodemanager两个服务都要进行交互,applicationmaster与resourcemanager交互,可以获得任务所需的计算资源,与nodemanager交互,可以实际启动计算任务,并对其进行监控。applicationmaster和resourcemanager、nodemanager之间的交互均可通过相应的rpc函数进行注册、通讯。需要特别注意的是,原生的tensorflow分布式程序所需的节点是在代码里固定的,配置方法如下:
tf.train.clusterspec({//这里给出的tf-worker(i)和tf-ps(i)都是服务器地址
采用yarn进行调度后,代码里留下的是从环境中获取具体服务器地址的接口,代码如下:
task_index=int(os.environ[“tf_index”])
job_name=os.environ[“tf_role”]
cluster_def=json.loads(os.environ[“tf_cluster_def”])
cluster=tf.train.clusterspec(cluster_def)
因此在applicationmaster需要把从yarn调度获取的节点资源转换为相应json格式。
转换方法主要如下:
//hashmap中key指的是角色,value指的是实际使用的节点地址,包括ip和端口
map<string,list<string>>clustermessage=newhashmap<string,list<string>>();
clustermessage.put(roleconstants.worker,workerlist);
clustermessage.put(roleconstants.ps,pslist);
this.clusterdefstr=newgson().tojson(clustermessage);
本系统设计并不改变原有深度学习框架和容器的运行,增加的是系统资源的管理和调度。因此本系统不改变原有深度学习框架和容器运行的任何结果。
具体地,以主流深度学习框架之一tensorflow为例,说明如何设计客户端,使调度层yarn与应用层相结合。图5为本发明实施例二提供的tensorflowonyarn的架构图;如图5所示,整个系统包括三种组件:
client:客户端:负责作业的启动和作业执行状态的获取。
applicationmaster(am):负责输入数据分片、启动及管理container、执行日志保存等;
container:作业实际执行的地方,取代原生tensorflow分布式程序需要在每个实际节点上手动启动ps(parameterserver)和worker进程,变为container自动启动,并把进程的运行状态定时向am进行汇报,同时还负责应用程序的输出等。
其中ps(parameterserver):负责保存和更新参数,该角色依托于作业采用的tensorflow深度学习框架,仅在分布式模式下启动。worker:执行作业训练逻辑,负责作业输出保存。
系统只监管到container层,worker和ps的实际运行由原有深度学习框架tensorflow负责。
为了验证本发明的系统的性能,实施例三列举了一系列验证本发明的系统性能的实验。
实验前,首先部署实验环境。在硬件上,本实验选用10台曙光w780-g20gpu服务器,每台配置2颗intelxeon2650v4处理器,每个单节点配置8块p100gpu加速卡,总共有80块nvidiateslap100gpu加速卡。计算存储网络方案采用infiniband高速网络,配置1台108口56gb/sfdr大端口模块化ib交换机,系统节点之间以56gb/sfdr线速交换,采用大端口模块。软件上,本实验选用centos7.2,cuda8.0,cudnn-v5.0,python2.7,nccl2.0,opencv2.4.13,tensorflow1.1.0,hadoop2.7.3,java1.8.0_65等。
实验程序选用分布式tensorflow程序,用于手写数字识别。网络架构为全连接神经网络,一层隐藏层。输入节点784个,中间一层隐藏层100个,输出节点10个。分别编写了原生的tensorflow分布式程序和使用yarn调度的tensorflow分布式程序,两者参数设置完全一样,主要代码一样,不同之处在于原生tensorflow分布式程序使用的节点是在程序里指定好了,并手动在各个指定节点上分别启动的,使用yarn调度的tensorflow分布式程序是由yarn自动分配的,程序里并不指定到各个具体节点,在一个节点上即可完成。程序主要参数设置如下:batch_size=100,learning_rate=0.0005,training_epochs=20,其他初始随机变量其他worker均与第一个worker的参数相同。
实验中采用了mnist数据集,mnist数据集是采集阿拉伯数字0-9的手写数字数据,每幅图片均为0到9中10个数字的任意一个,黑白像素。
mnist数据集可在http://yann.lecun.com/exdb/mnist/获取,它包含了四个部分:
trainingsetimages:train-images-idx3-ubyte.gz(9.9mb,解压后47mb,包含60,000个样本)
trainingsetlabels:train-labels-idx1-ubyte.gz(29kb,解压后60kb,包含60,000个标签)
testsetimages:t10k-images-idx3-ubyte.gz(1.6mb,解压后7.8mb,包含10,000个样本)
testsetlabels:t10k-labels-idx1-ubyte.gz(5kb,解压后10kb,包含10,000个标签)
采用原生的tensorflow分布式运行方法测试了1个ps,1,2,3,4,8个worker下以及2个ps,1,2,3,4,8个worker下程序完成时间。每种情况均进行10组实验,共计100组实验,每组实验的程序完成时间取worker中最迟完成的时间。每种情况的最后结果去除10组实验中的最高、最低值,取剩下8组的平均值。
使用yarn调度的tensorflow分布式运行方法同样测试了1个ps,1,2,3,4,8个worker下,2个ps,1,2,3,4,8个worker下程序完成时间。每种情况均进行10组实验,共计100组实验,每组实验的程序完成时间取全部完成时间。每种情况的最后结果去除10组实验中的最高、最低值,取剩下8组的平均值。
worker数可以看做是使用的计算节点数,每个worker均在不同的节点上,并占满每个节点的8块gpu。
每组实验均去除最高和最低时间,然后取平均值。
表1、1ps多worker下不同框架运行总时间(单位:秒)
行时间/worker数/20=平均每个epoch运行时间
表2、1ps多worker下不同框架平均每个epoch运行时间(单位:秒)
根据表2可得到一个如图6所示的1ps多worker下不同框架平均每个epoch运行时间柱状对比图。
由图6可以看出,不同worker下,每个epoch实际运行时间yarn调度的tensorflow分布式运行方法均大于原生的tensorflow分布式运行方法,这是因为yarn调度的tensorflow分布式运行方法的资源分配是动态的,只有在调度后才能确定程序运行的具体资源,这部分比原生的tensorflow分布式运行方法多了一些时间,另外应用程序在运行过程中均需要与applicationmaster和客户端进行通信,这部分也比原生的tensorflow分布式运行方法多了一些时间。不过考虑到yarn调度的tensorflow分布式运行方法的资源为自动分配,并在单节点启动,而非手动启动,原生的tensorflow分布式运行方法的实际总运行时间(考虑非计算机实际运行时间)会大于yarn调度的tensorflow分布式运行方法的实际总运行时间,而且随着worker的增加,非计算机实际运行时间会大大增加。
以1个ps,1个worker为基准,可得不同worker下得加速比
表3、1ps多worker下不同框架加速比
根据表3中的数据,可以得到如图7所示的1ps多worker下不同框架加速比示意图。如图7表示,yarntf和原生tf的加速比曲线是类似的,表明yarntf实际运行中增加的损耗并不以增加原生tf损耗为代价,yarntf具有同样的加速效果。
表4、2ps多worker下不同框架运行总时间(单位:秒)
运行时间/worker数/20=平均每个epoch运行时间
表5、2ps多worker下不同框架平均每个epoch运行时间
根据表5可得到一个如图8所示的2ps多worker下不同框架平均每个epoch运行时间柱状对比图。
图8的结果与图6类似,yarn调度的tensorflow分布式运行方法的计算机实际运行时间均大于原生tensorflow分布式运行方法的计算机实际运行时间。
以2ps,1个worker为基准,可得不同worker下得加速比。
表62ps多worker下不同框架加速比
根据表6中的数据,可以得到如图9所示的2ps多worker下不同框架加速比示意图。图6表明2ps多worker下,yarn调度的tensorflow分布式运行方法同样是有效的。
从图6和图9来看,使用yarn调度会比原生tensorflow分布式程序运行时间多,多余损耗主要用在了yarn的资源管理和调度上,但是考虑到原生tensorflow分布式程序需要在程序里指定固定节点,并且需要在每个节点上手动式分发,这会浪费大量的非计算机实际使用时间。考虑到多用户使用下,yarn调度的tensorflow分布式运行方法的可复用性更强,用户不用知道其他用户用了哪些节点,而原生tensorflow用户与用户需要提前商量好各节点的使用权。结合图7和图9来看,从1ps和2ps下不同worker的加速比来看,yarn调度的tensorflow分布式运行方法和原生tensorflow分布式程序的方法具有类似的趋势,表明yarn调度的tensorflow分布式运行方法加速效果与原生tensorflow分布式程序的方法加速效果相似。因此使用yarn调度tensorflow分布式程序会极大提高平台gpu的被使用能力。
本系统和方法实现了大数据框架与深度学习框架的结合,使得tensorflow可以用yarn进行调度。
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!