一种基于双目视觉的障碍物检测与识别方法与流程
本发明涉及视觉识别技术领域,特别涉及一种基于双目视觉的障碍物检测与识别方法。
背景技术:
障碍物的检测与识别是机器人自主运动、以及无人汽车自动驾驶的关键技术。目前障碍物检测的方法有:1、基于超声波的检测方法;2、基于雷达的检测方法;3、基于结构光的检测方法;4、基于视觉的检测方法。但目前这些方法只是获取到了障碍物的距离信息,并不能确定障碍物的类别信息,而障碍物的类别也是自主机器人和无人汽车的制定决策的重要参考因素。
技术实现要素:
有鉴于此,本发明的目的一种基于双目视觉的障碍物检测与识别方法,实现既能获得障碍物的距离信息,也能够获得障碍物的类别信息,以便为自主机器人和无人汽车的决策制定提供更好的环境感知能力。
本发明基于双目视觉的障碍物检测与识别方法,包括以下步骤:
1)对双目摄像头进行标定:
首先对左、右摄像头分别进行标定,得到两个摄像头各自的内参矩阵和畸变系数矩阵,然后采用opencv中的立体校正算法得到本征矩阵、基础矩阵、旋转矩阵和平移矩阵;
2)生成左摄像头深度图像:
先获得经标定后的双目摄像头的左摄像头图像和右摄像头图像;再通过sgbm立体匹配算法得到左摄像头的视差图,检测出视差图中的空洞区域;再用空洞区域附近可靠视差值的均值对孔洞区域进行填充,从而得到完整的视差图;再根据平行双目视觉的几何关系,得到如下视差与深度的转换公式:
depth=(f*tx)/disp
上式中,depth表示深度图;f表示归一化的焦距;tx是左摄像头光心和右摄像头光心之间的距离,称作基线距离;disp是视差值;最后通过视差与深度的转换公式计算出左摄像头的深度图像;
3)将获得到的双目摄像头的左摄像头的图像尺寸裁剪为416*416,再将裁减后的图像输入yolov3网络模型,从而得到障碍物在图像中的窗口坐标信息和类别信息;本步骤得到的障碍物在图像中的窗口坐标信息也就是步骤2)深度图像中障碍物的窗口坐标信息;
4)取步骤3)获得的深度图像中障碍物窗口的中心位置的深度值作为障碍物的距离,从而获得障碍物的距离信息。
本发明的有益效果:
本发明基于双目视觉的障碍物检测与识别方法,其既能获得障碍物的距离信息,也能够获得障碍物的类别信息,从而能为自主机器人和无人汽车提供更好的环境感知能力,有利于其制定更正确的决策。
附图说明
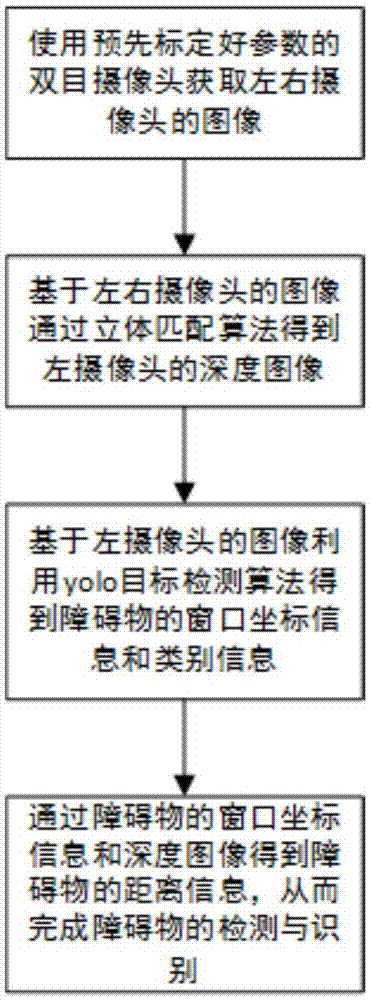
图1是本发明基于双目视觉的障碍物检测与识别方法的流程图。
具体实施方式
下面结合附图和实施例对本发明作进一步描述。
本实施例基于双目视觉的障碍物检测与识别方法,包括以下步骤:
1)对双目摄像头进行标定:
首先对左、右摄像头分别进行标定,得到两个摄像头各自的内参矩阵和畸变系数矩阵,然后采用opencv中的立体校正算法得到本征矩阵、基础矩阵、旋转矩阵和平移矩阵。
2)生成左摄像头深度图像:
先获得经标定后的双目摄像头的左摄像头图像和右摄像头图像;再通过sgbm立体匹配算法得到左摄像头的视差图,检测出视差图中的空洞区域;再用空洞区域附近可靠视差值的均值对孔洞区域进行填充,从而得到完整的视差图;再根据平行双目视觉的几何关系,得到如下视差与深度的转换公式:
depth=(f*tx)/disp
上式中,depth表示深度图;f表示归一化的焦距;tx是左摄像头光心和右摄像头光心之间的距离,称作基线距离;disp是视差值;最后通过视差与深度的转换公式计算出左摄像头的深度图像。
3)将获得到的双目摄像头的左摄像头的图像尺寸裁剪为416*416,再将裁减后的图像输入yolov3网络模型,从而得到障碍物在图像中的窗口坐标信息和类别信息;本步骤得到的障碍物在图像中的窗口坐标信息也就是步骤2)深度图像中障碍物的窗口坐标信息。
yolo的全称为:youonlylookonce:unified,real-timeobjectdetection,其是josephredmon和alifarhadi等人于2015年提出的基于单个神经网络的目标检测系统,yolov3是其第三代产品。yolov3网络模型使用的卷积神经网络模型为darknet-53,它包含53个卷积层,卷积核的大小为3*3和1*1两种,基于coco数据集对网络模型进行训练,当迭代次数大于指定迭代次数时训练结束。
4)取步骤3)获得的深度图像中障碍物窗口的中心位置的深度值作为障碍物的距离,从而获得障碍物的距离信息。
本实施例中基于双目视觉的障碍物检测与识别方法,其既能获得障碍物的距离信息,也能够获得障碍物的类别信息,从而能为自主机器人和无人汽车提供更好的环境感知能力,有利于其制定更正确的决策,例如当识别出对障碍物是无生命的石头时,自主机器人和无人汽车可做出绕行的决策;当识别出障碍物是人或其他动物时,自主机器人和无人汽车可做出等待人或动物离开后再前行的决策时。
最后说明的是,以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的宗旨和范围,其均应涵盖在本发明的权利要求范围当中。
技术特征:
技术总结
本发明公开了一种基于双目视觉的障碍物检测与识别方法,包括步骤:1)对双目摄像头进行标定2)生成左摄像头深度图像;3)将获得到的双目摄像头的左摄像头的图像尺寸裁剪为416*416,再将裁减后的图像输入YOLOv3网络模型,从而得到障碍物在图像中的窗口坐标信息和类别信息;4)取步骤3)获得的深度图像中障碍物窗口的中心位置的深度值作为障碍物的距离,从而获得障碍物的距离信息。本发明基于双目视觉的障碍物检测与识别方法,其既能获得障碍物的距离信息,也能够获得障碍物的类别信息,从而能为自主机器人和无人汽车提供更好的环境感知能力,有利于其制定更正确的决策。
技术研发人员:薛方正;刘阳阳;古俊波;罗胜元
受保护的技术使用者:重庆大学
技术研发日:2018.07.17
技术公布日:2018.12.18
- 还没有人留言评论。精彩留言会获得点赞!