一种基于网络爬虫和新浪API相结合的微博数据的采集方法与流程
本发明涉及微博数据采集技术领域,特别是一种基于网络爬虫和新浪api相结合的微博数据的采集方法。
背景技术:
对于微博中数据采集非常重要,这样也能为开展微博中社会安全事件的侦测提供重要的数据基础。目前,微博的数据采集方式主要有两种:基于新浪api和针对新浪微博平台的网络爬虫。基于新浪api的方案可以获取格式比较规范的数据,但是其调用次数有一定的限制,无法进行大规模的数据爬取,并且有些信息无法获取到;基于网络爬虫的方法虽然可以获取大规模的数据,但是其页面的分析处理过程比较复杂,并且其爬取的数据格式不规范,噪声数据比较多。
技术实现要素:
本发明的目的是要解决现有技术中存在的不足,提供一种基于网络爬虫和新浪api相结合的微博数据的采集方法。
为达到上述目的,本发明是按照以下技术方案实施的:
一种基于网络爬虫和新浪api相结合的微博数据的采集方法,包括以下步骤:
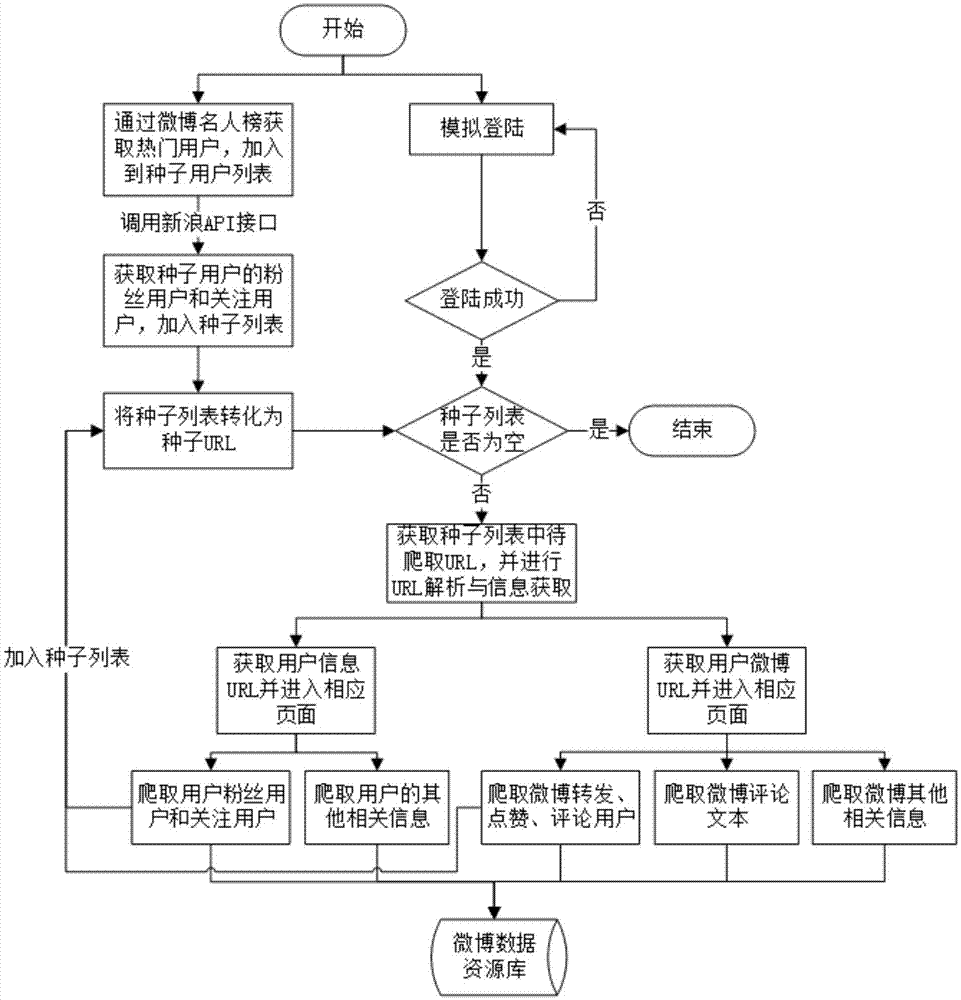
step1:基于新浪api从微博名人榜获取种子用户及其对应的粉丝用户和关注用户,加入到种子列表;
step2:将种子列表转换为种子url,并判断种子用户列表是否为空,若为空则进入step4,否则进入step3;
step3:遍历种子列表,采用网络爬虫的方法,爬取种子用户的相关微博信息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中;
step4:结束。
具体地,所述step3包括:
获取种子列表中待爬取url,并进行url解析与信息获取,具体包括:获取用户信息url并进入相应页面爬取用户粉丝用户和关注用户以及爬取用户的其他相关信息;获取用户微博url并进入相应页面爬取微博转发点赞、评论用户、爬取微博评论文本以及爬取微博其他相关信息;并将爬取的用户粉丝用户和关注用户、用户的其他相关信息、微博转发点赞、评论用户、爬取微博评论文本以及爬取微博其他相关构建相应的微博数据资源库;同时将爬取的用户粉丝用户和关注用户、爬取的微博转发点赞、评论用户加入种子列表中。
与现有技术相比,本发明通过将新浪api和针对新浪微博平台的网络爬虫相结合,既可以获取格式比较规范的微博数据,又能进行大规模的数据爬取,并且爬取的数据格式更加规范,噪声数据比较少,进而能够为开展微博中社会安全事件的侦测提供重要的数据基础。
附图说明
图1为本发明的流程图。
具体实施方式
下面结合具体实施例对本发明作进一步描述,在此发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。
如图1所示,本实施例的一种基于网络爬虫和新浪api相结合的微博数据的采集方法,包括以下步骤:
step1:基于新浪api从微博名人榜获取种子用户及其对应的粉丝用户和关注用户,加入到种子列表;
step2:将种子列表转换为种子url,并判断种子用户列表是否为空,若为空则进入step4,否则进入step3;
step3:遍历种子列表,采用网络爬虫的方法,爬取种子用户的相关微博信息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中,具体步骤为:获取种子列表中待爬取url,并进行url解析与信息获取,具体包括:获取用户信息url并进入相应页面从微博数据资源库中爬取用户粉丝用户和关注用户以及爬取用户的其他相关信息;获取用户微博url并进入相应页面从微博数据资源库中爬取微博转发点赞、评论用户、爬取微博评论文本以及爬取微博其他相关信息;同时将爬取的用户粉丝用户和关注用户、爬取的微博转发点赞、评论用户加入种子列表中。
step4:结束。
根据本实施例的方法采集完微博数据后,就可以对采集到的微博文本数据进行处理,清除其中的异常数据和噪声数据,实现数据格式的标准化,并构建相应的微博资源库,进而能够为开展微博中社会安全事件的侦测提供重要的数据基础。
本发明的技术方案不限于上述具体实施例的限制,凡是根据本发明的技术方案做出的技术变形,均落入本发明的保护范围之内。
技术特征:
技术总结
本发明公开了一种基于网络爬虫和新浪API相结合的微博数据的采集方法,基于新浪API从微博名人榜获取种子用户及其对应的粉丝用户和关注用户,加入到种子列表;将种子列表转换为种子URL,并判断种子用户列表是否为空,若为空则结束,否则遍历种子列表,采用网络爬虫的方法,爬取种子用户的相关微博信息、微博评论信息和用户个人信息,并将微博评论用户加入到种子列表中。与现有技术相比,本发明通过将新浪API和针对新浪微博平台的网络爬虫相结合,既可以获取格式比较规范的微博数据,又能进行大规模的数据爬取,并且爬取的数据格式更加规范,噪声数据比较少,进而能够为开展微博中社会安全事件的侦测提供重要的数据基础。
技术研发人员:张仰森;黄改娟;段瑞雪;张良;曾健荣
受保护的技术使用者:北京信息科技大学
技术研发日:2018.08.24
技术公布日:2019.01.18
- 还没有人留言评论。精彩留言会获得点赞!