基于模糊聚类和拉格朗日插值的电网缺失数据填补方法与流程
本发明属于电网缺失数据填补
技术领域:
,更为具体地讲,涉及一种基于模糊聚类和拉格朗日插值的电网缺失数据填补方法。
背景技术:
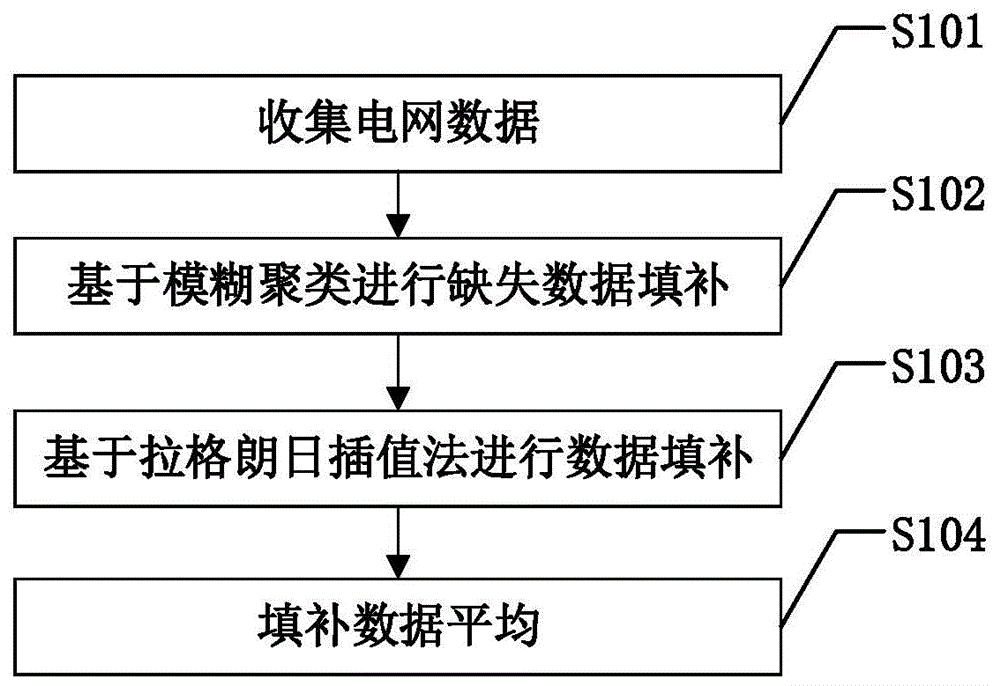
:在电网数据收集中,由于种种原因,比如年代过久、统计不全、人主观因素等,都会造成电网数据的缺失,这种数据的缺失是人为不可避免的,也是完全随机的。缺失数据会直接影响到电网统计推断的结果,比如电网是否安全稳定运行、电线是否跟换、变电站座数是否应该增加等。因此在数据分析前需采用一种数据补充方法将缺失的数据补充完整,提高电力系统数据分析的准确性和曲线类数据的可用性,为后续分析提供支持。目前在电网缺失数据中常用的填补方法有:直接删除法、均值填补、众数填补。直接删除法是最简单的,但是会造成信息的丢失;均值填补即是利用均值进行填充;众数填补即是利用样本中出现最多的数据进行填充,均值填补、众数填补会随着样本间差异变化而变化,当样本间差异较大时,误差很大;而单一的最近邻等算法又存在维度的单一性。技术实现要素:本发明的目的在于克服现有技术的不足,提供一种基于模糊聚类和拉格朗日插值的电网缺失数据填补方法,提高数据填补的准确性。为实现上述发明目的,本发明基于模糊聚类和拉格朗日插值的电网缺失数据填补方法具体包括以下步骤:s1:收集d个地区的m个电网参数在n个时间点的数据构成(n×d)×m的电网数据矩阵其中i=(n-1)n+d,n=1,2,…,n,d=1,2,…,d,i=1,2,…,n×d,j=1,2,…,m,元素表示第n个时间点时第d个地区第j个电网参数的数据,当xij为缺失数据,将其加入缺失数据集合xf;对电网数据矩阵进行数据标准化,消除数据的量纲,得到电网数据矩阵x=(xij);s2:基于模糊聚类对缺失数据集合xf中的缺失数据xi′j′进行填补,得到填补结果具体步骤包括:s2.1:对缺失数据集合xf中每个缺失数据xi′j′进行初始化,得到缺失数据的初始填补值s2.2:将当前电网数据矩阵x中的(n×d)×m个元素随机分为k类,计算得到每一类的初始聚类中心其中k=1,2,…,k;s2.3:初始化迭代次数r=1;s2.4:对于当前电网数据矩阵x的每个元素xij,计算得到其与当前各个聚类中心的距离根据以下公式计算得到各个元素属于各个聚类的隶属度其中,m表示预设的模糊因子;s2.5:根据以下公式对聚类中心进行更新:s2.6:对于缺失数据集合xf中的每个缺失数据xi′j′,根据以下公式计算得到其新的填补值s2.7:判断是否达到迭代结束条件,如果未达到,进入步骤s2.8,否则进入步骤s2.9;s2.8:令r=r+1,返回步骤s2.4;s2.9:将当前各个缺失数据xi′j′的填补结果作为填补结果s3:对于缺失数据集合xf中的每个缺失数据xi′j′,将其前p个时间点的数据和后q个时间点的相应电网参数数据组成数据序列,采用拉格朗日插值法对缺失数据xi′j′进行数据填补,将得到的填补结果作为填补结果s4:对于缺失数据集合xf中的每个缺失数据xi′j′,将步骤s2得到的填补数据与步骤s3得到的填补数据进行平均,得到最终的填补结果本发明基于模糊聚类和拉格朗日插值的电网缺失数据填补方法,收集得到电网数据矩阵并进行归一化处理,先基于模糊聚类对缺失数据进行填补,然后采用拉格朗日插值法对缺失数据进行数据填补,将两种方法得到的填补数据进行平均,得到最终的填补结果。本发明模糊聚类进行缺失数据填补,模糊聚类通过使用隶属度更加准确客观地进行了聚类;在采用拉格朗日插值法进行数据填补加入了时序概念,表述的是某个城市某个特征历年的变化;通过以上两种方法的结合,不再是单一的对数据进行填补,而是在考虑样本、特征之间关系的同时还加入了时间序列的概念,提高填补数据的准确度。附图说明图1是本发明基于模糊聚类和拉格朗日插值的电网缺失数据填补方法的一种具体实施方式流程图;图2是本发明中基于模糊聚类进行缺失数据填补的流程图。具体实施方式下面结合附图对本发明的具体实施方式进行描述,以便本领域的技术人员更好地理解本发明。需要特别提醒注意的是,在以下的描述中,当已知功能和设计的详细描述也许会淡化本发明的主要内容时,这些描述在这里将被忽略。实施例图1是本发明基于模糊聚类和拉格朗日插值的电网缺失数据填补方法的一种具体实施方式流程图。如图1所示,本发明基于模糊聚类和拉格朗日插值的电网缺失数据填补方法具体包括以下步骤:s101:收集电网数据:收集d个地区的m个电网参数在n个时间点的数据构成(n×d)×m的电网数据矩阵其中i=(n-1)n+d,n=1,2,…,n,d=1,2,…,d,i=1,2,…,n×d,j=1,2,…,m,元素表示第n个时间点时第d个地区第j个电网参数的数据,当xij为缺失数据,将其加入缺失数据集合xf。对电网数据矩阵进行数据标准化,消除数据的量纲,得到电网数据矩阵x=(xij)。本实施例中的数据标准化采用归一化,即电网数据矩阵x中的元素maxj表示电网数据矩阵第j个电网参数中的最大值。s102:基于模糊聚类进行缺失数据填补:基于模糊聚类(fuzzyc-means,fcm)对缺失数据集合xf中的缺失数据xi′j′进行填补,得到填补结果图2是本发明中基于模糊聚类进行缺失数据填补的流程图。如图2所示,本发明中基于模糊聚类进行缺失数据填补的具体步骤包括:s201:设置缺失数据初始值:对缺失数据集合xf中每个缺失数据xi′j′进行初始化,得到缺失数据的初始填补值即令一般来说,初始填补值可以设置为0,也可以根据实际需要来设置,例如设置为对应电网参数现有数据的均值。s202:随机分类:将当前电网数据矩阵x中的(n×d)×m个元素随机分为k类,计算得到每一类的初始聚类中心其中k=1,2,…,k,k的大小是根据实际需要确定的。s203:初始化迭代次数r=1。s204:计算隶属度:对于当前电网数据矩阵x的每个元素xij,计算得到其与当前各个聚类中心的距离根据以下公式计算得到各个元素属于各个聚类的隶属度其中,m表示预设的模糊因子。所有隶属度可以构成大小为(n×d×m)×k的隶属度矩阵u,隶属度矩阵u中各个隶属度满足以下条件:s205:更新聚类中心:根据以下公式对聚类中心进行更新:s206:计算缺失数据的填补值:对于缺失数据集合xf中的每个缺失数据xi′j′,根据以下公式计算得到其新的填补值s207:判断是否达到迭代结束条件,如果未达到,进入步骤s208,否则数据填补结束,进入步骤s209。迭代结束条件一般有两种,一是相邻两次计算得到的聚类中心所组成的向量之间的距离小于预设阈值,二是达到最大迭代次数,可以根据实际需要进行设置。s208:令r=r+1,返回步骤s204。s209:得到填补结果:将当前各个缺失数据xi′j′的填补结果作为填补结果s103:基于拉格朗日插值法进行数据填补:对于缺失数据集合xf中的每个缺失数据xi′j′,将其前p个时间点的数据和后q个时间点的相应电网参数数据组成数据序列,p和q的具体大小根据需要进行设置,采用拉格朗日插值法对缺失数据xi′j′进行数据填补,将得到的填补结果作为填补结果拉格朗日(lagrange)插值法是一种常用的插值方法,其具体过程在此不再赘述。在本发明中,考虑到缺失数据与前后相邻时间点的数据相关性较大,所以优选选取与缺失数据最近的三个时间点的数据组成数据序列。s104:填补数据平均:对于缺失数据集合xf中的每个缺失数据xi′j′,将步骤s102得到的填补数据与步骤s103得到的填补数据进行平均,得到最终的填补结果为了更好地说明本发明的技术方案,采用一个具体实施例对本发明进行详细说明。本实施例以国网某省公司某些年的数据为对象,对其旗下各个分公司的电网数据进行缺失填补,用以展示本发明方法的技术效果。本实施例中以年为周期进行电网数据统计,共计8年,即n=8,所统计的分公司有15个,即d=15,电网参数包括10千伏变电站座数、10千伏变电容量、10千伏电缆条数、110千伏变电站座数、110千伏变电容量、110千伏电缆条数、220千伏变电站座数、220千伏变电容量、220千伏电缆条数、全社会用电量、现价gdp、负荷增长率、全社会最大负荷等30个,因此m=30个。因此所获得的电网数据矩阵的大小为120×30,对该矩阵进行归一化处理得到电网数据矩阵x。表1是本实施例中电网数据矩阵x的表格形式。表1为了验证本发明的技术效果,在表1中随机设置10个数据为缺失数据。表2是本实施例中缺失数据集合的明细。表2首先基于模糊聚类对10个缺失数据进行填补,得到填补结果然后采用拉格朗日插值法对10个缺失数据进行填补,得到填补结果最后将两种方法的填补结果进行平均,从而得到最终的填补结果。为了进行技术效果的对比,还基于knn聚类(其中参数k=1)对10个缺失数据进行填补,将其填补结果连同填补结果填补结果一起作为对比数据。表3是本实施例中不同方法得到的填补结果对比表。缺失数据真实值模糊聚类拉格朗日knn本发明x16,10.23210.25100.18030.03350.21565x20,150.08810.10910.07810.03690.0936x50,60.17100.10860.20600.18420.1573x88,230.11140.11050.12150.03750.116x11,30.10660.10900.11580.11540.1124x97,260.11080.10930.11170.00150.1105x69,80.04310.11050.06760.09070.08905x110,50.07230.06440.07360.07910.069x6,290.12030.10930.12760.03550.11845x101,190.12030.10810.02800.11750.06805表3表4是本实施例中不同方法得到的填补结果与真实值的误差统计表。缺失数据模糊聚类拉格朗日knn本发明x16,18.1422.3285.577.09x20,1523.8411.3558.126.24x50,636.4920.477.728.01x88,230.819.0766.344.13x11,32.258.638.265.44x97,261.350.8198.650.27x69,8156.3856.84110.44106.61x110,510.931.89.414.56x6,299.146.0770.491.54x101,1910.1476.722.3343.43表4本实施例采用填补准确度(fillaccuracyrate,fac)来评价各种方法的优越性,填补准确度评价函数的计算公式如下:其中:n表示缺失数据数量,n1为所有填补结果中正确填补结果的数量,正确填补结果指填补结果在真实值的±10%误差范围内(在表4中已加粗标识)表5是本实施例中不同方法的填补准确度统计表。模糊聚类拉格朗日knn本发明填补准确度50%50%40%80%表5从表3、表4、表5中可以清晰的看出,本发明所得到的填补结果要优于基于模糊聚类的填补方法、拉格朗日插值、基于knn聚类的填补方法,更加接近真实数据。尽管上面对本发明说明性的具体实施方式进行了描述,以便于本
技术领域:
的技术人员理解本发明,但应该清楚,本发明不限于具体实施方式的范围,对本
技术领域:
的普通技术人员来讲,只要各种变化在所附的权利要求限定和确定的本发明的精神和范围内,这些变化是显而易见的,一切利用本发明构思的发明创造均在保护之列。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1