基于上下文信息和注意力机制的遥感影像语义分割方法与流程
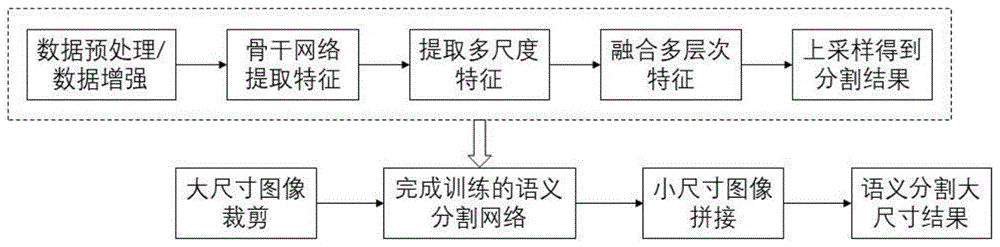
本发明属于遥感影像识别领域,尤其涉及一种基于上下文信息和注意力机制的高分辨率遥感影像语义分割方法。
背景技术:
近年来,随着遥感技术的快速发展,高分辨率的遥感影像数据越来越丰富,针对遥感图像的语义分割也逐渐成为一个重要的研究方向。语义分割任务需要对遥感图像中的每个像素按语义进行分类,从而得到整幅图像的分割结果。然而,由于遥感图像本身的大尺寸特性,一幅遥感图像中常常包含大量不同类别的地物,如建筑、植被、林地、汽车等。其中,建筑物有着多种多样的外形,汽车的尺寸相较于其他地物显得非常渺小,而植被和林地在外形上又比较相似,这些都增加了遥感影像语义分割的难度。
传统方法采用特征提取结合分类器的方式对遥感图像进行语义分割。特征提取部分均采用传统的手工特征,如梯度直方图hog、尺度不变特征sift、分割加速特征fast等,使用时需要对遥感影像进行具体分析,才能选择适用的特征。分类器则采用经典的统计学习方法中的支持向量机svm、随机森林rf、k-means聚类等方法,但对于包含复杂场景的遥感影像,传统方法难以处理。随着深度学习方法的普及,人们提出了一系列基于卷积神经网络cnn的方法用于处理语义分割任务,如全卷积网络fcn、u型网络u-net、分割网络segnet、标注网络deeplab系列等。fcn网络去掉了常规分类网络的全连接层,对骨干网络的输出上采样得到最终的分类结果,后续网络均基于fcn的思路进行改进,也在自然图像数据集上展现了它们相对于传统方法的优越性。然而,这些方法均是针对自然图像设计的,难以处理好具有复杂场景的大尺度变化的遥感影像。
技术实现要素:
本发明所要解决的技术问题在于提供一种基于上下文信息和注意力机制的遥感影像语义分割方法,该方法能够实现具有复杂场景和大尺度变化的遥感影像的高精度语义分割。
本发明采用的技术方案为:
一种基于上下文信息和注意力机制的遥感影像语义分割方法,包括以下步骤:
步骤1:对遥感影像进行标注,将带标注的遥感影像进行数据预处理和数据扩增;
步骤2:构建语义分割网络,将扩充后带标注的遥感影像输入构建的语义分割网络,对网络进行训练;
其中,构建语义分割网络具体如下:
构建语义分割网络模型,包括骨干网络-深度残差网络resnet、多尺度上下文信息模块和第一至第三注意力融合模块;
骨干网络-深度残差网络resnet将带标注的遥感影像提取得到4个不同层次的初步特征,并一一对应输入第一至第三注意力融合模块和多尺度上下文信息模块;
多尺度上下文信息模块将最高层的初步特征进行并行卷积和全局池化,将并行卷积和全局池化的结果进行级联,将级联后的特征提取结果输入第三注意力融合模块;
第三注意力融合模块将多尺度上下文信息模块的特征提取结果与第三层的初步特征进行级联,级联后经过卷积-bn-relu和池化操作再与第三层的初步特征相加,将相加结果输入第二注意力融合模块;
第二注意力融合模块将第三注意力融合模块的特征提取结果与第二层的初步特征进行级联,级联后经过卷积-bn-relu和池化操作再与第二层的初步特征相加,将相加结果输入第一注意力融合模块;
第一注意力融合模块将第二注意力融合模块的特征提取结果与第一层的初步特征进行级联,级联后经过卷积-bn-relu和池化操作再与第一层的初步特征相加;
将第一注意力融合模块的结果通过上采样引入高分辨率特征图,得到最终分割结果;
步骤3:将无标注的遥感影像输入训练好的语义分割网络,得到对应的分割结果。
其中,多尺度上下文信息模块包括并行卷积部分、全局池化部分和级联部分,并行卷积部分包括多个具有不同卷积核大小的支路,每一支路分别包括卷积层、bn层、relu层、卷积层和bn层;其中各支路的卷积层分别为3x3卷积、7x7卷积、11x11卷积和15x15卷积;全局池化部分包括全局卷积层、1x1卷积层和bn层;级联部分将并行卷积部分和全局池化部分各支路的特征提取结果进行级联。
其中,三个注意力融合模块结构相同,均包括卷积层、bn层、relu层、全局池化层、通道相乘部分和求和部分;处理过程包括以下步骤:
(301)卷积层将下一高层的特征提取结果与本层的初步特征进行级联;
(302)级联后的结果经过卷积-bn-relu操作,再进行全局池化操作,得到通道向量;
(303)将通道向量作为权重与经过卷积-bn-relu操作后的特征相乘,得到基于通道注意力机制的特征;
(304)将基于通道注意力机制的特征与本层的初步特征相加,得到特征提取结果。
本发明采用以上技术方案与现有技术相比,具有以下优点:
1.利用提出的多尺度上下文信息模块,可以有效处理具有大尺度变化的遥感影像,增强对多尺度地物的识别能力。
2.利用提出的注意力融合模块,可以有效结合不同层级的特征,提高分割时的定位精度,并增强特征的判别能力,从而应对具有复杂场景的遥感影像。
3.采用端到端的方式处理遥感影像语义分割问题,比传统的特征工程方法更加简洁,提取的特征也更有针对性。
附图说明
图1为本发明处理过程图。
图2为典型的城区遥感影像。
图3为本发明提出的遥感影像语义分割网络结构图。
图4为本发明提出的多尺度上下文信息模块结构图。
图5为本发明提出的注意力融合模块结构图。
图6为本发明网络输出的遥感影像语义分割结果图。
具体实施方式
本发明提供了一种基于上下文信息和注意力机制的遥感影像语义分割方法。为使本发明的目的,技术方案及效果更加清楚、明确,以下参考附图对本发明进一步详细说明。
图1为本发明处理过程图,首先通过骨干网络提取初步特征,然后利用多尺度上下文信息模块提取多尺度的特征并融合,其次利用注意力融合模块对不同层次的特征进行融合,提高最终的定位精度,最后得到的特征图进行上采样,即为最终的分割结果。网络训练完成后,将大尺寸图像进行裁剪通过训练好的语义分割网络得到分割结果,再进行拼接。
本发明基于上下文信息和注意力机制的遥感影像语义分割方法,主要包含以下步骤:
步骤1:对遥感影像进行标注,图2为典型的城区遥感影像,将带标注的遥感影像进行数据预处理和数据扩增;具体包括:
步骤s101:对标注数据进行类别编码,将以rgb值表示的图像编码为以类别标签(0,1,2,3,…)为亮度值的灰度图像。
步骤s102:采用旋转、缩放、翻转等方式对已有的遥感影像进行扩充。具体地,对已有的遥感影像和对应的标注数据,按顺时针依次旋转90°、180°、270°,或对其进行水平翻转和竖直翻转,或对原图像进行1.25倍的放大和0.75倍的缩小。
步骤2:构建语义分割网络,将扩充后带标注的遥感影像输入构建的语义分割网络,对网络进行训练;
本发明语义分割网络模型结构如图3所示。包括骨干网络-深度残差网络res1-res4,多尺度上下文信息模块cfm和三个注意力融合模块amm,三个注意力融合模块amm从上到下分别为第一至第三注意力融合模块。下面进行详细描述构建语义分割网络模型:
构建语义分割网络模型,包括骨干网络-深度残差网络resnet、多尺度上下文信息模块和第一至第三注意力融合模块;
骨干网络-深度残差网络resnet将带标注的遥感影像提取得到4个不同层次的初步特征,浅层的特征空间分辨率高,具有丰富的结构信息,但缺乏语义信息;深层的特征空间分辨率低,具有高层次语义信息,但缺乏细节结构信息。将4个不同层次的初步特征一一对应输入第一至第三注意力融合模块和上下文信息模块;
多尺度上下文信息模块将最高层的初步特征进行并行卷积和全局池化,将并行卷积和全局池化的结果进行级联,将级联后的特征提取结果输入第三注意力融合模块;
如图4所示,多尺度上下文信息模块包括并行卷积部分、全局池化部分和级联部分,并行卷积部分包括多个具有不同卷积核大小的支路,每一支路分别包括卷积层、bn层、relu层、卷积层和bn层;其中各支路的卷积层分别为3x3卷积、7x7卷积、11x11卷积和15x15卷积;全局池化部分包括全局卷积层、1x1卷积层和bn层;级联部分将并行卷积部分和全局池化部分各支路的特征提取结果进行级联。
bn层用于减小数据的协方差,促进网络收敛。relu层用作网络的非线性激活函数。输入的图像大小为512x512,经过骨干网络的不断下采样后,最高层特征的空间分辨率变为原来的1/32,即16x16。此时15x15的卷积等同于全局卷积,即类似于分类任务的全连接层,从而提高了网络分辨复杂地物的能力。卷积核的大小可以根据输入图片的大小进行调节,保证最大卷积核支路可以实现全局卷积。通过全局池化引入全局上下文信息,从而消除局部信息的歧义性,提高特征的判别能力。1x1卷积用于调整特征的通道数量,从而与并行卷积部分得到的特征进行特征级联。
第三注意力融合模块将多尺度上下文信息模块的特征提取结果与第三层的初步特征进行级联,级联后经过卷积-bn-relu和池化操作,再进行全局池化操作,得到一个通道向量,将通道向量作为权重与经过卷积-bn-relu操作后的特征相乘,得到基于通道注意力机制的特征,将基于通道注意力机制的特征与第三层的初步特征相加,将相加结果输入第二注意力融合模块;
第二注意力融合模块将第三注意力融合模块的结果与第二层的初步特征进行级联,级联后经过卷积-bn-relu操作,再进行全局池化操作,得到一个通道向量,将通道向量作为权重与经过卷积-bn-relu操作后的特征相乘,得到基于通道注意力机制的特征,将基于通道注意力机制的特征与第二层的初步特征相加,将相加结果输入第一注意力融合模块;
第一注意力融合模块将第二注意力融合模块的结果与第一层的初步特征进行级联,级联后经过卷积-bn-relu操作,再进行全局池化操作,得到一个通道向量,将通道向量作为权重与经过卷积-bn-relu操作后的特征相乘,得到基于通道注意力机制的特征,将基于通道注意力机制的特征与第一层的初步特征相加;
将第一注意力融合模块的结果通过上采样引入高分辨率特征图,得到最终分割结果;具体地,融合后特征的空间分辨率为原始图像的1/4,可直接通过双线性插值方式得到最终的分割结果。
其中,如图5所示,三个注意力融合模块结构相同,均包括卷积层、bn层、relu层、全局池化层、通道相乘部分和求和部分结构;全局池化和相乘操作可以选出更具有分辨力的特征,增强特征的识别能力,而显式的相加则直接引入了低层的高分辨率特征,引入了更丰富的细节信息,提高了最终分割时的定位精度。此外,求和操作使得整个模块有着类似残差模块的结构,从而具有类似残差模块的性能,即促进整个网络的收敛。
步骤3:将无标注的遥感影像输入训练好的语义分割网络,得到对应的分割结果。具体包括:
步骤s301:将无标记的测试图像进行分割,得到512x512的小尺寸图像。然后输入训练好的语义分割网络,得到相同尺寸大小的分割结果。
步骤s302:将相同尺寸大小的分割结果进行拼接,得到最终的大尺度遥感图像分割结果,如图6所示。
完成基于上下文信息和注意力机制的遥感影像语义分割。
- 还没有人留言评论。精彩留言会获得点赞!