基于突发词检测和过滤的微博突发话题检测方法与流程
本发明属于互联网技术领域,具体涉及一种突发话题检测方法。
背景技术:
近年来,随着web2.0社交网络的兴起,微博以其方便快捷的优点迅速流行起来,现在已经发展成为网络信息传播的主要途径。突发话题在微博中传播速度非常迅速,能够产生巨大的影响力,因此,微博平台上的社会突发话题检测技术对于社会热点的及时发现、网络民意的尽快感知、突发话题及早响应等方面都具有积极的现实意义。然而,目前对于微博的突发话题检测而言依旧存在一些挑战。首先,微博上话题具有多样性。同一时间微博上各种话题如社会话题类话题、娱乐八卦类话题、个人生活琐事等多种话题掺杂在一起,存在大量对于话题检测而言无意义的信息。其次,微博上有的话题表现出间歇性。通常同一个话题会随着微博用户的关注程度和时间的推移经历一个产生、发展、成熟、衰退和消亡的完整生命周期。通常这个生命周期是连续的,但是一些话题在产生后会沉寂两到三天,之后随着相关的后续消息出现再次出现。
本发明提出了基于突发词检测和过滤的微博突发话题检测方法。从两个方面进行研究。突发词提取上,综合考虑了词的基本权重和突发权重,利用词出现频次、包含词的微博数、词出现频次的增长速度计算词的突发值;利用词突发值趋势分析的方法,计算短期突发值的均值与长期突发值的均值的差,过滤无效的突发词。本发明能够更加准确地检测突发话题。
技术实现要素:
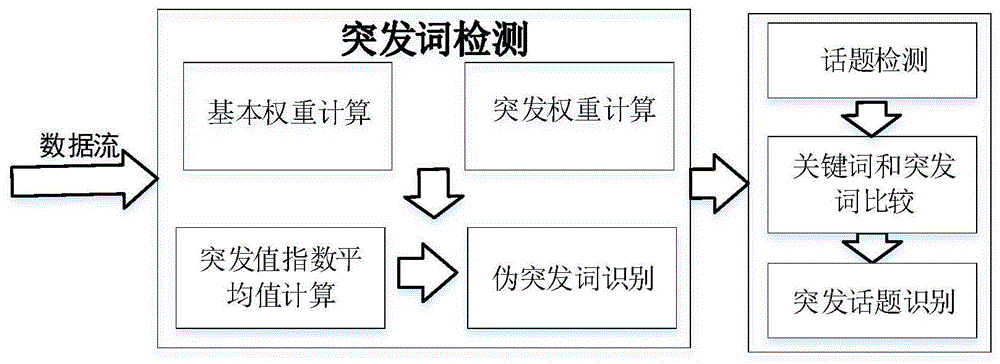
本发明所提出的基于突发词检测和过滤的微博突发话题检测方法分为三个部分:突发词的提取、伪突发词的过滤和突发话题识别。首先,分别计算一个词在某个时间片的基本权重与突发权重,根据这个词的基本权重与突发权重计算一个词的突发值;其次,计算一个词突发值在两个不同长度时间段内的指数平均值,根据两个指数平均值的差判断词突发值的变化趋势;最后,使用主题模型和聚类的方法检测出当前时间片的话题,并选出每个话题出现频次最高的3个词作为关键词。如果一个话题中的关键词包含突发词,则认为这个话题是突发话题。
为达到上述目的,如图1所示,本发明的技术方案划分为三个部分:
1.基于词突发值计算的突发词检测;
2.基于突发值指数平均值的伪突发词识别;
3.基于话题关键字和突发词相似度的突发话题识别
本发明有以下一些技术特征:
(1)提出基于词突发值计算的突发词检测,突发词提取上,综合考虑了词的基本权重和突发权重,利用词出现频次、包含词的微博数、词出现频次的增长速度计算词的突发值。
(2)提出基于突发值指数平均值的伪突发词识别,计算一个词突发值在两个不同长度时间段内的指数平均值,根据两个指数平均值的差判断词突发值的变化趋势。
(3)提出基于话题关键字和突发词相似度的突发话题识别,使用主题模型与聚类算法结合的方法来检测时间片内的话题。当一个话题的前三个关键词与突发词的相似度大于一个阈值时,此话题为突发话题。算法的精确率、召回率比传统算法有较大提高。
本发明提出了一种突发话题检测方法,理论系统完备,创新性突出,主要用在社交网络数据中。本发明应用在社交网络突发话题检测领域,可以处理各种话题混杂的社交网络文本数据,识别出伪突发词,提高突发话题检测的准确性和实时性。
附图说明
图1为基于突发词检测和过滤的微博突发话题检测模型的基本内容结构图;
具体实施方式
为使本发明的目的、算法计算及优点更加清楚明白,以下参照附图对本发明做进一步详细地说明。本发明算法的具体实现分为以下几步:
1.基于词突发值计算的突发词检测
结合词的基本权重和突发权重,提出了一种基于突发值计算的突发词算法。算法主要包括两个部分:基本权重计算和突发权重计算。这个过程采用公式(1)来阐述:
w(i,j)=λf(i,j)+(1-λ)b(i,j)(1)
其中f(i,j)和b(i,j)分别代表词wi在第j时间片的基本权重和突发权重,wi表示词典中第i个词,j表示时间片的顺序。λ为调节系数(0<λ<1)。算法具体实现步骤:
步骤1:统计词的频率信息。将数据集划分成n个时间片下的数据集d1,…,dn;获取一个词的累计词频、词频最高的词的词频、包含这个词的文档和时间片内总文档数;
步骤2:计算基本权重。计算词的累计词频与最高词频的比值、包含词的文档数与总文档数比值,对两个比值进行加权处理,以输出词的基本权重;
步骤3:计算突发权重。计算词累计词频的增长速度作为突发权重,其中,词的累计词频表示当前时间片内所有文档中,词出现的累计次数,用于比较的词频是词wi在之前k个时间片内的平均累计词频;
步骤4:加权计算基本权重和突发权重,最终得到词wi在第j时间片的突发值;当突发值大于某个阈值时,这个词是突发词。
2.基于突发值指数平均值的伪突发词识别
提出的基于突发值指数平均值的伪突发词识别算法,主要的实施划分为三个阶段。在第一阶段,计算词的突发值计算在两个时间段内指数平均值的差。第二阶段,计算差值在一个时间段的指数平均值。第三阶段,比较第一阶段和第二阶段的结果判断词的突发值变化趋势,判断词是否为伪突发词。算法具体实现步骤:
步骤1:计算词突发值在之前n天内的指数平均值,取不同的n的值n1,n2;
步骤2:计算词突发值在n1-n2两个时间段内的差值,并计算差值的指数平均值;
步骤3:比较步骤2得到差值和差值的指数平均值,判断词是否为伪突发词。
3.基于突发词的突发话题识别
提出一种基于话题关键字和突发词相似度的突发话题识别算法,算法的具体步骤如下:
步骤1:使用主题模型计算当前时间片内的文本的主题分布;
步骤2:对当前时间片内的文本,通过聚类算法比较文本之间的余弦相似度得到聚类结果,每一个类是一个话题;
步骤3:选取每个话题文本中累计词频最高的三个词为关键词;
步骤4:当一个话题的关键词包含当前时间片的突发词时,这个话题是突发话题。
技术特征:
1.一种基于突发词检测和过滤的微博突发话题检测方法,其特征在于,该方法包括:
基于词突发值计算的突发词检测;
基于突发值指数平均值的伪突发词识别;
基于话题关键字和突发词相似度的突发话题识别。
2.根据权利要求1所述的方法,其特征在于,根据分词结果计算词在一个时间片的突发值:
在一个时间片内,获取一个词的累计词频、词频最高的词的词频、包含这个词的文档和时间片内总文档数,并计算词的累计词频与最高词频的比值、包含词的文档数与总文档数比值,对两个比值进行加权处理,以输出词的基本权重。
计算词累计词频的增长速度作为突发权重,其中,词的累计词频表示当前时间片内所有文档中,词出现的累计次数。对两个权重加权求和计算出突发值。
3.根据权利要求1所述的方法,其特征在于,计算词在不同长度时间段内的突发值的指数平均值,计算两个指数平均值的差值,再次计算差值在一个时间段内的指数平均值。比较两个结果的大小确定词突发值的变化趋势,以此识别伪突发词。
4.根据权利要求1所述的方法,其特征在于,使用主题模型与聚类算法结合的方法来检测时间片内的话题,当一个话题的前三个关键词包含突发词时,此话题为突发话题。
技术总结
本发明提出了一种基于突发词检测和过滤的微博突发话题检测方法。方法包括三个部分:基于词突发值计算的突发词检测、基于突发值指数平均值计算的伪突发词识别和基于话题关键字和突发词相似度的突发话题识别。理论系统完备,创新性突出,主要用于社交网络文本处理中。该发明为微博突发话题检测提供了解决方案,具有很高的实用价值。
技术研发人员:薛哲;杜军平;张强
受保护的技术使用者:北京邮电大学
技术研发日:2019.07.12
技术公布日:2019.11.22
- 还没有人留言评论。精彩留言会获得点赞!